Clear Sky Science · es
Modelos multimodales para la clasificación del cáncer de piel usando texto clínico libre e imágenes dermatoscópicas
Por qué importan las exploraciones de piel más inteligentes
El cáncer de piel es frecuente, pero cuando se detecta pronto, las personas suelen tener muy buen pronóstico. Los médicos ya usan fotografías en primer plano de los lunares para decidir cuáles parecen preocupantes. Este estudio plantea una pregunta simple con grandes implicaciones: si los ordenadores pudieran leer también las notas del médico sobre cada lunar, no solo las imágenes, ¿podrían detectar el cáncer de piel de forma más precisa y justa?

Imágenes y palabras cuentan una historia más completa
Los investigadores construyeron un gran conjunto de datos a partir de consultas dermatológicas rutinarias en el Reino Unido. Incluyó 5.481 imágenes dermatoscópicas en primer plano de 4.538 adultos, junto con datos básicos del paciente como edad y tipo de piel, y cuatro tipos de notas clínicas. Estas notas abarcaron cómo se veía la lesión y cómo cambiaba con el tiempo, si había antecedentes familiares de cáncer de piel, la exposición solar del paciente y lo que pensaba y planeaba el cirujano. Cada caso fue etiquetado como benigno o maligno, confirmándose los casos malignos mediante biopsia siempre que fue posible.
Pistas ocultas dentro de las notas clínicas
A diferencia de los datos de casillas simples, el texto libre permite a los médicos describir rasgos sutiles: un lunar que se ha oscurecido, una mancha que sangra o un paciente que trabajó al aire libre durante años. Esos detalles pueden ser muy informativos, pero también pueden desvelar la respuesta. Muchas notas contienen lo que los autores llaman lenguaje sesgador: frases que afirman o insinúan fuertemente el diagnóstico o el tratamiento, como «carcinoma basocelular, derivar para biopsia» o «no requiere tratamiento». Si un modelo de aprendizaje automático se apoya simplemente en estos atajos, puede parecer muy preciso en datos históricos mientras aprende poco sobre cómo reconocer realmente el cáncer a partir de las imágenes o de las descripciones reportadas por el paciente.
Enseñar a los ordenadores a ignorar atajos
Para abordar este problema, el equipo diseñó varios niveles de limpieza del texto. Reglas simples eliminaron primero los nombres explícitos de enfermedades de la piel y las palabras benigno y maligno. Luego usaron un gran modelo de lenguaje para realizar un filtrado más sutil. En una configuración, las frases diagnósticas clave y los planes de tratamiento se sustituyeron por etiquetas neutrales para que los autores pudieran medir cuánto mejoraba el rendimiento cada tipo de enunciado. En el ajuste más estricto, solo se conservaron la información factual que un paciente podría proporcionar razonablemente, como cuánto tiempo llevaba presente un lunar o hábitos solares pasados. Este enfoque buscaba acercar el texto a lo que vería un sistema orientado al paciente en lugar de depender de pistas internas de los especialistas.
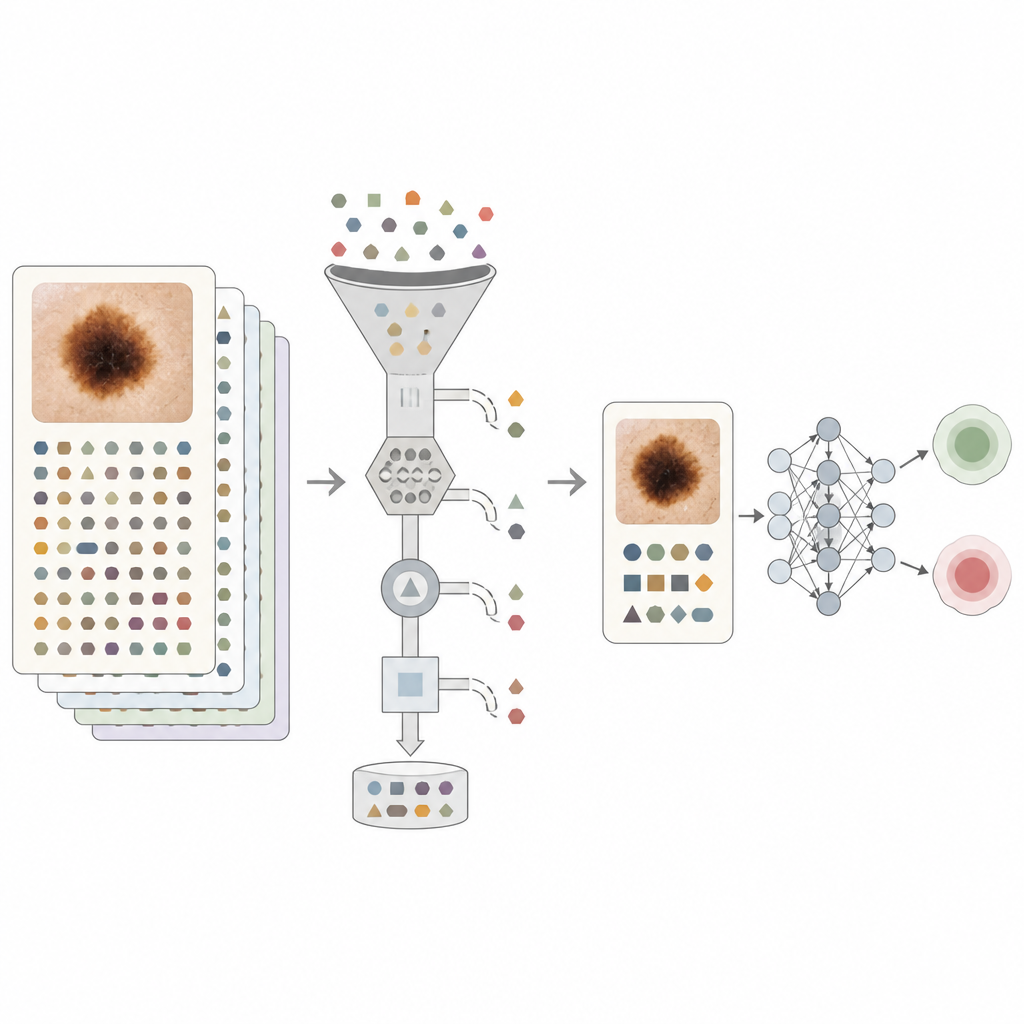
Qué aprendieron realmente los modelos
Cuando el modelo informático se basó solo en imágenes, funcionó bien, pero añadir notas sin filtrar lo mejoró de forma significativa. La medida principal de precisión, el área bajo la curva ROC (AUROC), subió de 0,909 con solo imágenes a 0,970 con imágenes más notas sin procesar. Incluso cuando se eliminó todo el lenguaje diagnóstico evidente, combinar imágenes con texto cuidadosamente filtrado alcanzó aún un AUROC de alrededor de 0,948, superior a cualquiera de las fuentes por separado. Los experimentos con frases etiquetadas mostraron que acciones sencillas como «derivar al hospital» transmitían casi tanta información como una etiqueta de cáncer explícita, confirmando que muchas notas contienen un fuerte sesgo incorporado. Los autores también examinaron el rendimiento según grupos de edad y categorías de tono de piel y encontraron niveles relativamente bajos de injusticia, tanto para el modelo solo de imágenes como para los modelos multimodales completos.
Qué significa esto para las futuras revisiones de la piel
Para los no expertos, la conclusión principal es que las notas del médico contienen pistas reales y útiles que pueden ayudar a los ordenadores a apoyar decisiones sobre el cáncer de piel, pero deben manejarse con cuidado. Si se permite que los modelos lean notas sin filtrar, pueden aprender a imitar la redacción de los médicos en lugar de reconocer por sí mismos los lunares de riesgo. Este estudio muestra que, al limpiar el texto de forma reflexiva y combinarlo con imágenes y datos básicos del paciente, es posible mejorar la precisión reduciendo al mismo tiempo el sesgo oculto. Con el tiempo, esas herramientas multimodales podrían ayudar a los médicos de atención primaria a hacer mejores derivaciones y acortar las esperas para la atención especializada, además de sentar las bases para sistemas seguros y conscientes del texto que algún día podrían asistir directamente a los pacientes.
Cita: Watson, M., Winterbottom, T., Hudson, T. et al. Multimodal models for skin cancer classification using clinical freetext and dermatoscopic images. Commun Med 6, 277 (2026). https://doi.org/10.1038/s43856-026-01456-2
Palabras clave: cáncer de piel, aprendizaje automático, dermatología, notas clínicas, imágenes médicas