Clear Sky Science · pl
Federacyjne modele bazowe CT do wykrywania przerzutów do węzłów chłonnych w rakach trzustki w wielu ośrodkach
Dlaczego to ma znaczenie dla pacjentów
Rak trzustki jest jednym z najbardziej śmiertelnych nowotworów, częściowo dlatego, że często jest wykrywany późno i już rozsiany do pobliskich węzłów chłonnych. Wiedza, czy do takiego rozsiewu doszło przed operacją, jest kluczowa: wpływa na to, jak agresywne powinno być zabieg oraz czy pacjentom należy podać najpierw chemioterapię. Tymczasem dzisiejsze badania CT, oceniane przez ekspertów, przeoczają wiele ukrytych przerzutów. Badanie to analizuje, jak nowa generacja dużych medycznych modeli AI, trenowanych wspólnie w szpitalach bez udostępniania surowych danych pacjentów, może zwiększyć dokładność i równość podejmowanych decyzji wpływających na życie.
Trudny rak i ślepy punkt obrazowania
Większość raków trzustki to gruczolakoraki przewodowe trzustki (pancreatic ductal adenocarcinoma), znane z niskiej przeżywalności. Kluczowym sygnałem powagi choroby jest zajęcie węzłów chłonnych w pobliżu trzustki. Radiolodzy starają się wykrywać to na skanach CT, zwykle oceniając rozmiar i kształt węzłów chłonnych. Niestety te wskazówki wzrokowe są zawodna: wielu pacjentów z mikroskopowym rozsiewem wygląda „normalnie” w CT, a różni eksperci często się nie zgadzają. W efekcie stopień zaawansowania nowotworu może być niedoszacowany i część pacjentów może nie otrzymać intensywnego leczenia, którego faktycznie potrzebują.
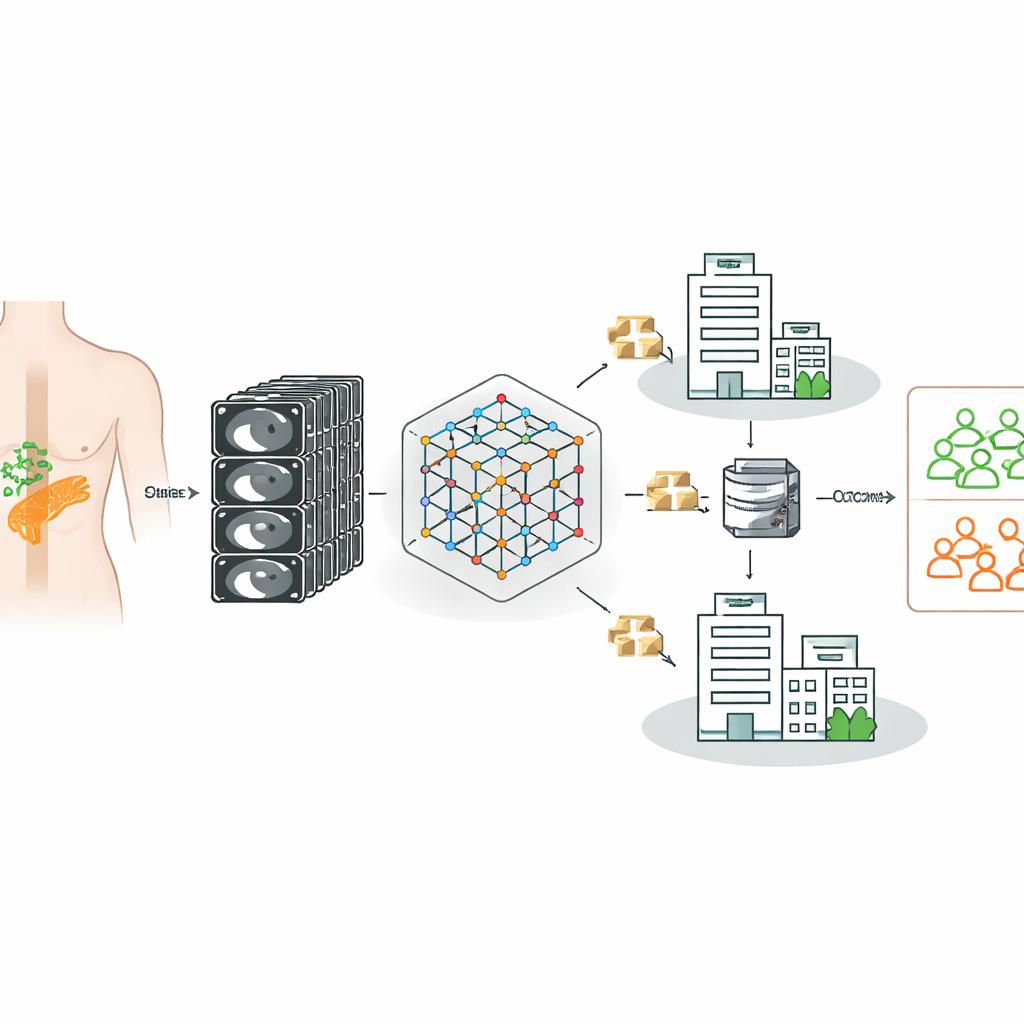
Nauczanie modelu CT na danych z wielu szpitali
Naukowcy oparli pracę na potężnym „modelu bazowym” dla obrazów CT — systemie AI pierwotnie wyszkolonym na 148 000 skanach CT, by rozpoznawać ogólne wzorce w trójwymiarowej anatomii. Następnie dopracowali ten model tak, by dla każdego pacjenta z rakiem trzustki decydował, czy węzły chłonne były rzeczywiście przerzutowe, używając potwierdzonych wyników chirurgicznych i patologicznych jako prawdy podstawowej. Co ważne, dane pochodziły z trzech niemieckich szpitali z różnymi skanerami, protokołami obrazowania i populacjami pacjentów, odzwierciedlając złożoną rzeczywistość praktyki klinicznej, a nie jedną starannie wyselekcjonowaną bazę danych.
Współpraca bez udostępniania danych pacjentów
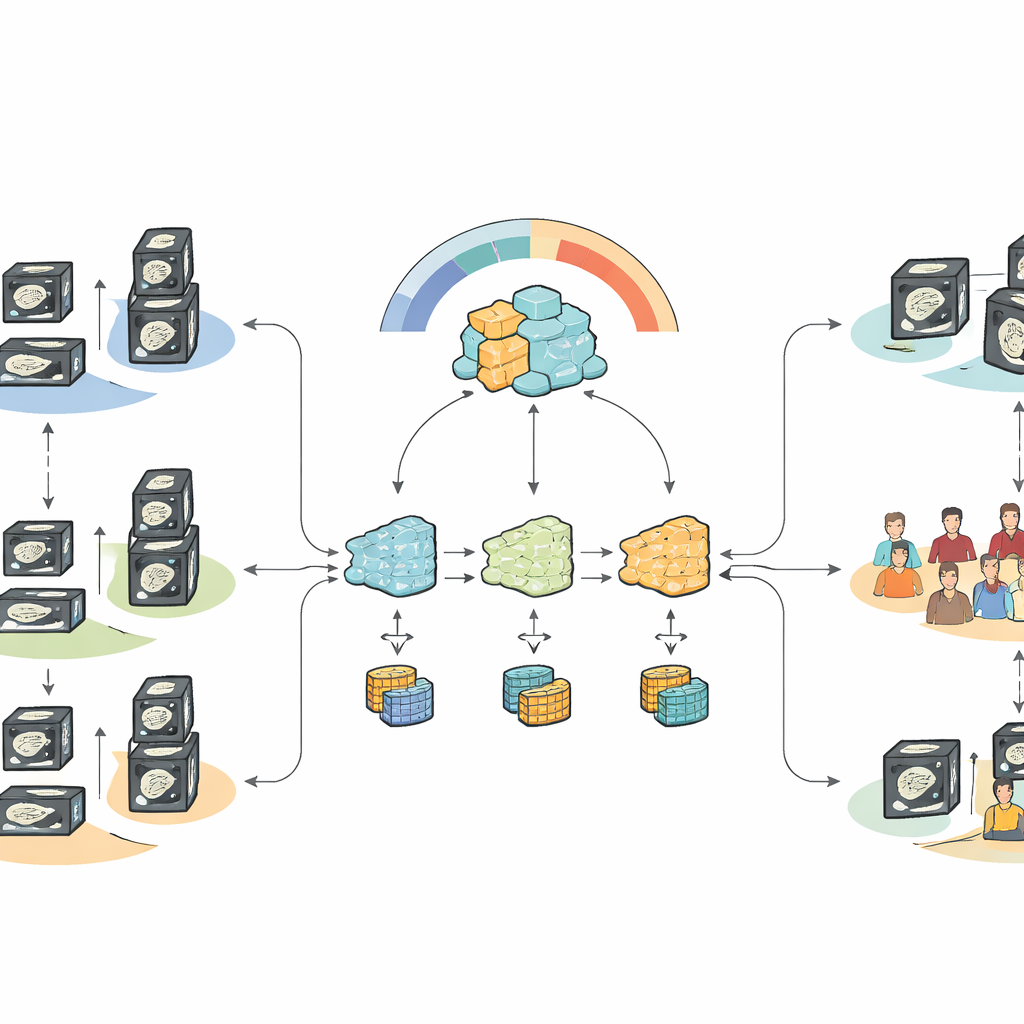
Ponieważ surowe przepisy o prywatności uniemożliwiają szpitalom swobodne łączenie skanów pacjentów, zespół zwrócił się ku uczeniu federacyjnemu. W tym podejściu wspólny model jest wysyłany do każdego szpitala, trenowany lokalnie na danych tego szpitala, a następnie aktualizowany centralnie za pomocą jedynie wyuczonych parametrów modelu, nigdy samych obrazów. Standardowe metody federacyjne jednak zakładają, że wszystkie miejsca są do siebie podobne. W medycynie rzadko jest to prawda: różnice w urządzeniach, czasie podania kontrastu i składzie pacjentów mogą popychać lokalne modele w sprzeczne strony, pogarszając wydajność, gdy ich aktualizacje są po prostu uśredniane.
Mądrzejszy sposób łączenia wiedzy szpitali
Aby to rozwiązać, autorzy zaprojektowali „świadomą heterogeniczności” metodę łączenia aktualizacji z każdego szpitala. Ich metoda uwzględnia nie tylko to, jak niezrównoważone są etykiety w danym miejscu (ile pacjentów ma lub nie ma przerzutów), lecz także jak bardzo granica decyzyjna wyuczona w danym szpitalu różni się od wspólnego modelu. Klienci, których modele odpływają zbyt daleko od wspólnego wzorca, są ważone mniej podczas scalania aktualizacji. Ta strategia uwzględniająca reprezentacje stabilizuje trening, jednocześnie pozwalając systemowi uczyć się z unikalnych doświadczeń każdego szpitala, dając globalny model, który lepiej rozdziela pacjentów z przerzutami i bez nich.
Co wyniki pokazują dla opieki w świecie rzeczywistym
Gdy wszystkie dane zostałyby zebrane centralnie — scenariusz zwykle zablokowany przez regulacje prywatności — dopracowany model bazowy wyraźnie przewyższał tradycyjne techniki uczenia maszynowego i wcześniejsze modele raka trzustki w rozróżnianiu przypadków przerzutowych od nieprzerzutowych. W warunkach federacyjnych, zachowujących prywatność, nowe podejście uwzględniające heterogeniczność odzyskało większość tej wydajności i przewyższyło standardowe metody federacyjne, które albo przewidywały zbyt wiele, albo zbyt mało przerzutów. System był szczególnie dobry pod względem czułości — wykrywania pacjentów z zajętymi węzłami chłonnymi — przy osiągnięciu umiarkowanej, lecz poprawionej swoistości, co jest kompromisem zgodnym z priorytetem klinicznym unikania przeoczenia choroby, nawet kosztem pewnej liczby fałszywych alarmów.
Co to oznacza na przyszłość
Dla czytelnika nietechnicznego kluczowy przekaz jest taki, że silne modele AI można teraz trenować na wrażliwych skanach rozproszonych w wielu szpitalach bez przemieszczania danych, i mimo to poprawiać ocenę przez lekarzy, czy rak trzustki rozprzestrzenił się do węzłów chłonnych. Praca ta pokazuje, że rozpoczęcie od szerokiego modelu bazowego CT i zastosowanie mądrzejszego sposobu łączenia wiedzy z różnych szpitali daje bardziej wiarygodne, klinicznie istotne prognozy niż starsze metody. Choć narzędzie nie jest jeszcze doskonałe — zwłaszcza w ograniczaniu fałszywie dodatnich wyników — stanowi obiecujący krok w kierunku bezpieczniejszego i bardziej spójnego wsparcia decyzji dla chirurgów i onkologów mierzących się z jednym z najtrudniejszych nowotworów.
Cytowanie: Bhalla, P., Gaviria, D.D., Kupczyk, P. et al. Federated CT foundation models for multi-center detection of lymph node metastasis in pancreatic cancer. Sci Rep 16, 12051 (2026). https://doi.org/10.1038/s41598-026-47631-2
Słowa kluczowe: rak trzustki, przerzuty do węzłów chłonnych, tomografia komputerowa, medyczna sztuczna inteligencja, uczenie federacyjne