Clear Sky Science · pl
Model wczesnego przewidywania oporności na antybiotyki oparty na uczeniu wielozadaniowym z wykorzystaniem danych kohort wieloinstytucjonalnych
Dlaczego to ma znaczenie dla codziennej opieki zdrowotnej
Oporność na antybiotyki cicho przemienia kiedyś uleczalne infekcje w choroby zagrażające życiu. Lekarze często muszą wybierać antybiotyk zanim badania laboratoryjne wykażą, które leki zadziałają — a takie opóźnienie może trwać kilka dni. Badanie to analizuje, w jaki sposób modele komputerowe trenowane na zapisach szpitalnych mogą dać lekarzom wczesne ostrzeżenie, które antybiotyki prawdopodobnie zawiodą, pomagając chronić pacjentów i spowalniać rozprzestrzenianie się opornych bakterii.
Antybiotyki pod presją
Współczesna medycyna w dużej mierze polega na antybiotykach — od rutynowych zabiegów chirurgicznych po opiekę onkologiczną. Tymczasem bakterie ewoluują szybko, a nowe antybiotyki pojawiają się wolniej niż stare tracą skuteczność. W Korei Południowej, gdzie przeprowadzono to badanie, nawet do jednej trzeciej szpitalnych przepisów antybiotyków uznaje się za nieodpowiednie. Posiewy, które ujawniają, czy drobnoustrój jest oporny, zwykle zajmują trzy do pięciu dni, zmuszając lekarzy do leczenia w ciemno. Badacze postawili sobie za cel przewidzenie oporności na dziewięć głównych grup antybiotyków, wykorzystując jedynie informacje dostępne we wczesnym okresie pobytu pacjenta w szpitalu.
Przekształcanie danych szpitalnych w wczesne ostrzeżenia
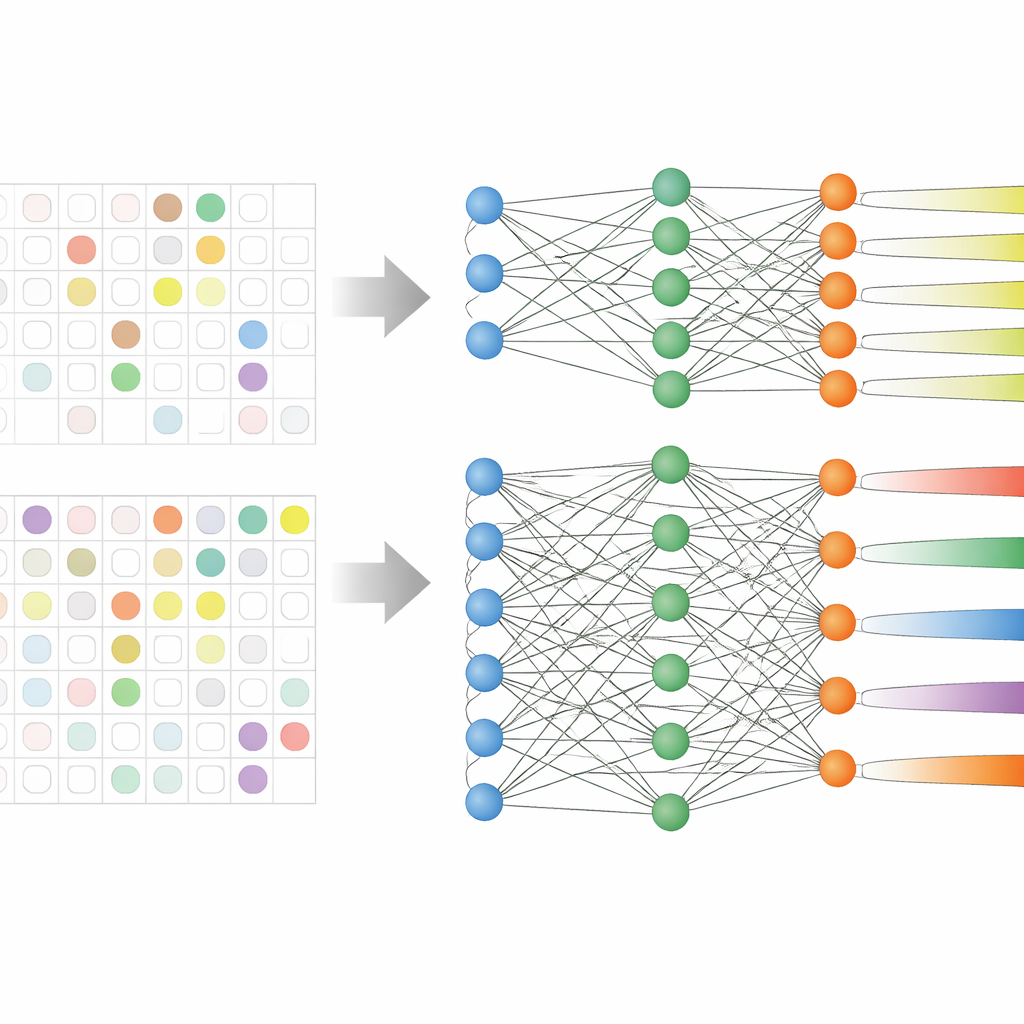
Zespół przeanalizował elektroniczne rekordy medyczne 59 551 dorosłych pacjentów z trzech dużych koreańskich szpitali z okresu ponad dekady. Rekordy zawierały wiek, parametry życiowe, czas pobytu, wcześniejsze stosowanie antybiotyków oraz, co kluczowe, wyniki wcześniejszych posiewów pokazujące, które antybiotyki już zawiodły. Zamiast trenować dziewięć oddzielnych modeli — po jednym dla każdej grupy antybiotyków — zastosowano strategię nazwaną uczeniem wielozadaniowym, pozwalającą jednemu modelowi uczyć się kilku powiązanych zadań predykcyjnych jednocześnie. Przetestowano dwie wersje: jedną z dzielonym rdzeniem rozgałęziającym się na osobne wyjścia dla każdej grupy antybiotyków (tzw. hard sharing) oraz drugą, w której zadania są połączone luźniej (soft sharing).
Rozwiązanie problemu niekompletnych wyników laboratoryjnych
Prawdziwe dane szpitalne są nieuporządkowane: nie każdego pacjenta testuje się wobec wszystkich antybiotyków. Wcześniejsze badania często odrzucały takie częściowo oznaczone przypadki, zmniejszając zbiory danych i ignorując wzorce obejmujące różne leki. W tym badaniu badacze zmodyfikowali regułę uczenia modelu tak, by po prostu pomijać brakujące wyniki laboratoryjne przy liczeniu błędu treningowego. Pozwoliło to zachować niemal wszystkich pacjentów w analizie, nawet jeśli brakowało wyników dla niektórych antybiotyków. Model z hard sharing szczególnie skorzystał na tym rozwiązaniu, ponieważ mógł uczyć się wspólnych sygnałów oporności, jednocześnie dopasowując przewidywania do każdej grupy leków.
Jak dobrze radziły sobie modele?
Gdy testowano je na danych ze szpitali, których nie widziały podczas treningu, modele wielozadaniowe generalnie przewyższały bardziej tradycyjne metody, takie jak regresja logistyczna czy standardowe algorytmy boostingowe. Średnio model z hard sharing wykazywał najlepszą równowagę między dokładnością a stabilnością w dziewięciu klasach antybiotyków i był szczególnie silny dla grup leków o najskromniejszych danych, jak aminoglikozydy. Osobna analiza wyjaśniająca, które cechy wpływają na przewidywania, wykazała, że poprzednia oporność pacjenta na dany antybiotyk była najważniejszym czynnikiem, a dalej — oporność lub stosowanie powiązanych leków, wiek i długość pobytu. Analizy podgrup pokazały, że hard sharing działał najlepiej, gdy dostępne były wcześniejsze wyniki posiewów dla danego antybiotyku, podczas gdy soft sharing był lepszy, gdy taka historia była nieobecna.
Co to oznacza dla pacjentów i klinicystów
Badanie sugeruje, że inteligentne wykorzystanie zapisów szpitalnych może dostarczać wczesnych, stosunkowo wiarygodnych prognoz dotyczących oporności na antybiotyki w kilku głównych rodzinach leków. Nawet umiarkowane poprawy dokładności przewidywań, zastosowane w dużych populacjach pacjentów, mogłyby pomóc lekarzom szybciej wybierać węższe, bardziej ukierunkowane antybiotyki i pewniej rezygnować z leków o szerokim spektrum. To z kolei może zmniejszyć powikłania, skrócić pobyty w szpitalu i spowolnić szerszy postęp oporności. Autorzy zastrzegają, że ich model wciąż wymaga testów i dopracowania w rzeczywistych warunkach, szczególnie gdy brakuje danych z wcześniejszych posiewów, ale argumentują, że uczenie wielozadaniowe oferuje obiecujący sposób lepszego wykorzystania niedoskonałych danych medycznych i wspierania bardziej ostrożnego stosowania antybiotyków.
Cytowanie: Kim, Y., Jeong, I., Park, JH. et al. Multi task learning based early prediction model for antibiotic resistance using multi institutional cohort data. Sci Rep 16, 11891 (2026). https://doi.org/10.1038/s41598-026-41185-z
Słowa kluczowe: oporność na antybiotyki, wsparcie decyzji klinicznych, elektroniczne rekordy medyczne, uczenie maszynowe, uczenie wielozadaniowe