Clear Sky Science · fr
Modèle de prédiction précoce de la résistance aux antibiotiques basé sur l’apprentissage multi-tâches utilisant des données de cohortes multi-institutionnelles
Pourquoi cela compte pour les soins de santé quotidiens
La résistance aux antibiotiques transforme discrètement des infections autrefois curables en maladies potentiellement mortelles. Les médecins doivent souvent choisir un antibiotique avant que les analyses de laboratoire n’indiquent quels médicaments seront efficaces, un délai qui peut durer plusieurs jours. Cette étude examine comment des modèles informatiques entraînés sur des dossiers hospitaliers peuvent fournir aux médecins une alerte précoce sur les antibiotiques susceptibles d’échouer, aidant à protéger les patients et à ralentir la propagation des bactéries résistantes.
Des antibiotiques sous pression
La médecine moderne repose largement sur les antibiotiques, pour tout, des interventions chirurgicales courantes aux soins oncologiques. Pourtant les bactéries évoluent rapidement, et de nouveaux antibiotiques apparaissent plus lentement que d’autres perdent leur efficacité. En Corée du Sud, où se déroule cette étude, jusqu’à un tiers des prescriptions d’antibiotiques à l’hôpital sont jugées inappropriées. Les cultures qui révèlent si un germe est résistant prennent généralement trois à cinq jours, forçant les médecins à traiter à l’aveugle. Les chercheurs ont cherché à prédire la résistance à neuf grands groupes d’antibiotiques, en n’utilisant que des informations disponibles tôt lors de l’hospitalisation d’un patient.
Transformer les données hospitalières en alertes précoces
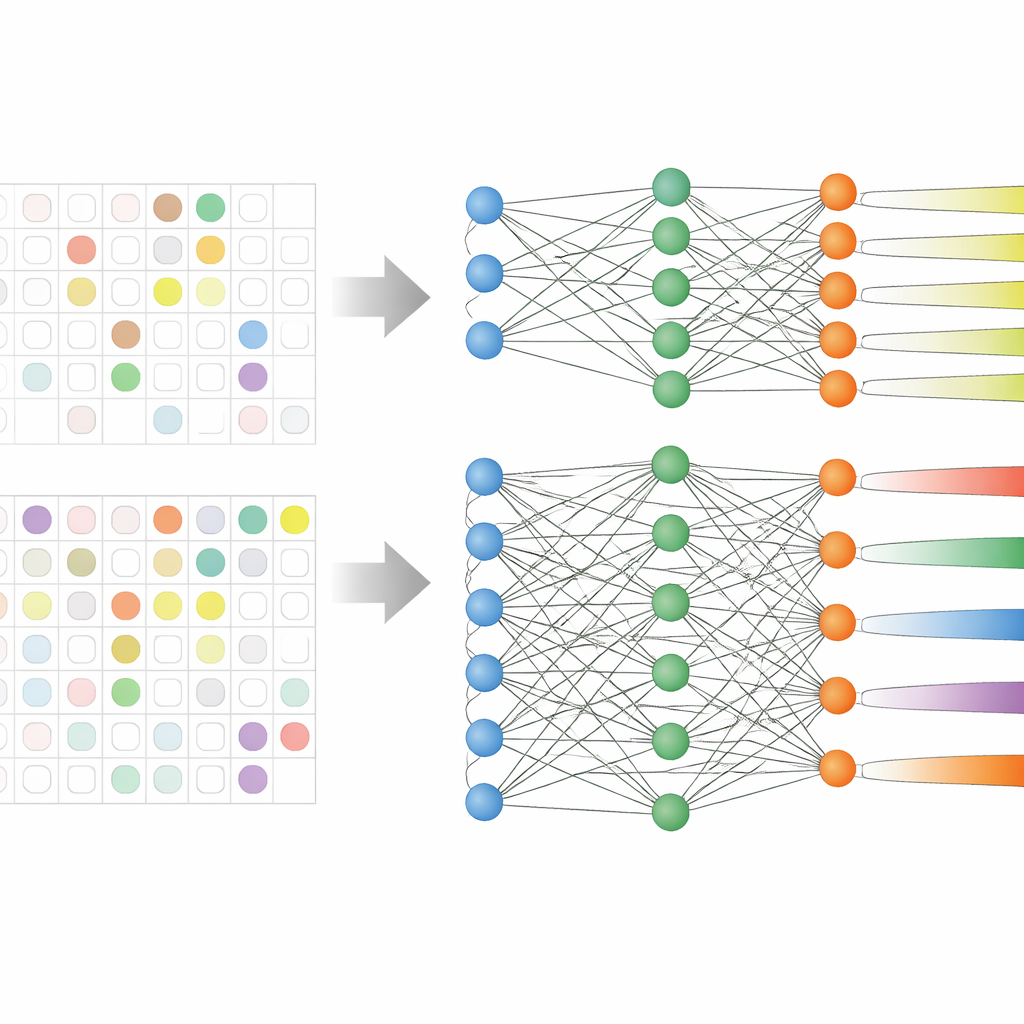
L’équipe a analysé les dossiers médicaux électroniques de 59 551 patients adultes dans trois grands hôpitaux coréens sur plus d’une décennie. Ces dossiers comprenaient l’âge, les constantes vitales, la durée du séjour, les usages antérieurs d’antibiotiques et, fait crucial, les résultats antérieurs de cultures montrant quels antibiotiques avaient déjà échoué. Plutôt que d’entraîner neuf modèles séparés — un pour chaque groupe d’antibiotiques — ils ont utilisé une stratégie appelée apprentissage multi-tâches, qui permet à un seul modèle d’apprendre plusieurs tâches de prédiction liées simultanément. Deux variantes ont été testées : une avec un noyau partagé qui se ramifie en sorties distinctes pour chaque groupe (partage dur), et une où les tâches sont liées de façon plus flexible (partage souple).
Résoudre le problème des résultats de laboratoire incomplets
Les données hospitalières réelles sont désordonnées : tous les patients ne sont pas testés contre chaque antibiotique. Les études antérieures éliminaient souvent ces cas partiellement étiquetés, réduisant leurs jeux de données et ignorant des schémas qui traversent différents médicaments. Ici, les chercheurs ont réécrit la règle d’apprentissage du modèle pour qu’il ignore simplement les résultats de laboratoire manquants lors du calcul de son erreur d’entraînement. Cela leur a permis de conserver presque tous les patients dans l’analyse, même lorsque certains résultats antibiotiques faisaient défaut. Le modèle à partage dur a particulièrement bénéficié de cette approche, car il pouvait apprendre des signaux communs de résistance tout en affinant ses prédictions pour chaque groupe de médicaments.
Quelle a été la performance des modèles ?
Lors des tests sur des données d’hôpitaux qu’ils n’avaient pas vues auparavant, les modèles multi-tâches ont généralement surpassé des méthodes plus traditionnelles comme la régression logistique et les algorithmes de boosting standard. En moyenne, le modèle à partage dur a montré le meilleur compromis entre précision et stabilité sur les neuf classes d’antibiotiques, et il était particulièrement performant pour les groupes de médicaments avec les données les plus rares, comme les aminosides. Une analyse distincte expliquant les caractéristiques qui motivent les prédictions a révélé que la résistance antérieure d’un patient à un antibiotique était le facteur le plus important, suivi de la résistance ou de l’utilisation de médicaments apparentés, ainsi que de l’âge et de la durée du séjour. Des analyses par sous-groupes ont montré que le partage dur fonctionnait mieux lorsque des résultats de culture antérieurs pour un antibiotique donné étaient disponibles, tandis que le partage souple était préférable lorsque cet historique faisait défaut.
Ce que cela signifie pour les patients et les cliniciens
L’étude suggère qu’une utilisation intelligente des dossiers hospitaliers peut fournir des prévisions précoces et raisonnablement fiables de la résistance aux antibiotiques pour plusieurs familles de médicaments majeures. Même des gains modestes en précision prédictive, appliqués à un grand nombre de patients, pourraient aider les médecins à choisir plus tôt des antibiotiques plus ciblés et à réduire l’usage d’antibiotiques à large spectre avec plus de confiance. Cela peut à son tour réduire les complications, raccourcir les durées d’hospitalisation et ralentir la progression générale de la résistance. Les auteurs précisent que leur modèle nécessite encore des tests et des ajustements en conditions réelles, notamment lorsque les données de cultures antérieures sont absentes, mais ils soutiennent que l’apprentissage multi-tâches offre une voie prometteuse pour mieux exploiter des données médicales imparfaites et soutenir un usage plus prudent des antibiotiques.
Citation: Kim, Y., Jeong, I., Park, JH. et al. Multi task learning based early prediction model for antibiotic resistance using multi institutional cohort data. Sci Rep 16, 11891 (2026). https://doi.org/10.1038/s41598-026-41185-z
Mots-clés: résistance aux antibiotiques, support à la décision clinique, dossiers de santé électroniques, apprentissage automatique, apprentissage multi-tâches