Clear Sky Science · nl
Vroeg voorspellend model voor antibioticumresistentie gebaseerd op multi-task learning met gegevens uit meerdere instellingen
Waarom dit belangrijk is voor de dagelijkse zorg
Antibioticaresistentie verandert stilletjes eens goed te behandelen infecties in levensbedreigende ziekten. Artsen moeten vaak al een antibioticum kiezen voordat laboratoriumtests aantonen welk middel werkt, een vertraging die enkele dagen kan duren. Deze studie onderzoekt hoe computermodellen die zijn getraind op ziekenhuisgegevens artsen vroegtijdig kunnen waarschuwen welke antibiotica waarschijnlijk zullen falen, wat patiënten kan beschermen en de verspreiding van resistente bacteriën kan vertragen.
Antibiotica onder druk
De moderne geneeskunde steunt zwaar op antibiotica, van routinematige operaties tot oncologische zorg. Toch evolueren bacteriën snel en verschijnen nieuwe antibiotica langzamer dan oude hun werkzaamheid verliezen. In Zuid-Korea, waar deze studie plaatsvond, wordt tot een derde van de antibioticavoorschriften in ziekenhuizen als ongepast beoordeeld. Kweektesten die aantonen of een micro-organisme resistent is, duren gewoonlijk drie tot vijf dagen, waardoor artsen vaak in het duister moeten handelen. De onderzoekers probeerden resistentie te voorspellen voor negen belangrijke antibioticagroepen, met alleen informatie die vroeg in het ziekenhuisverblijf beschikbaar is.
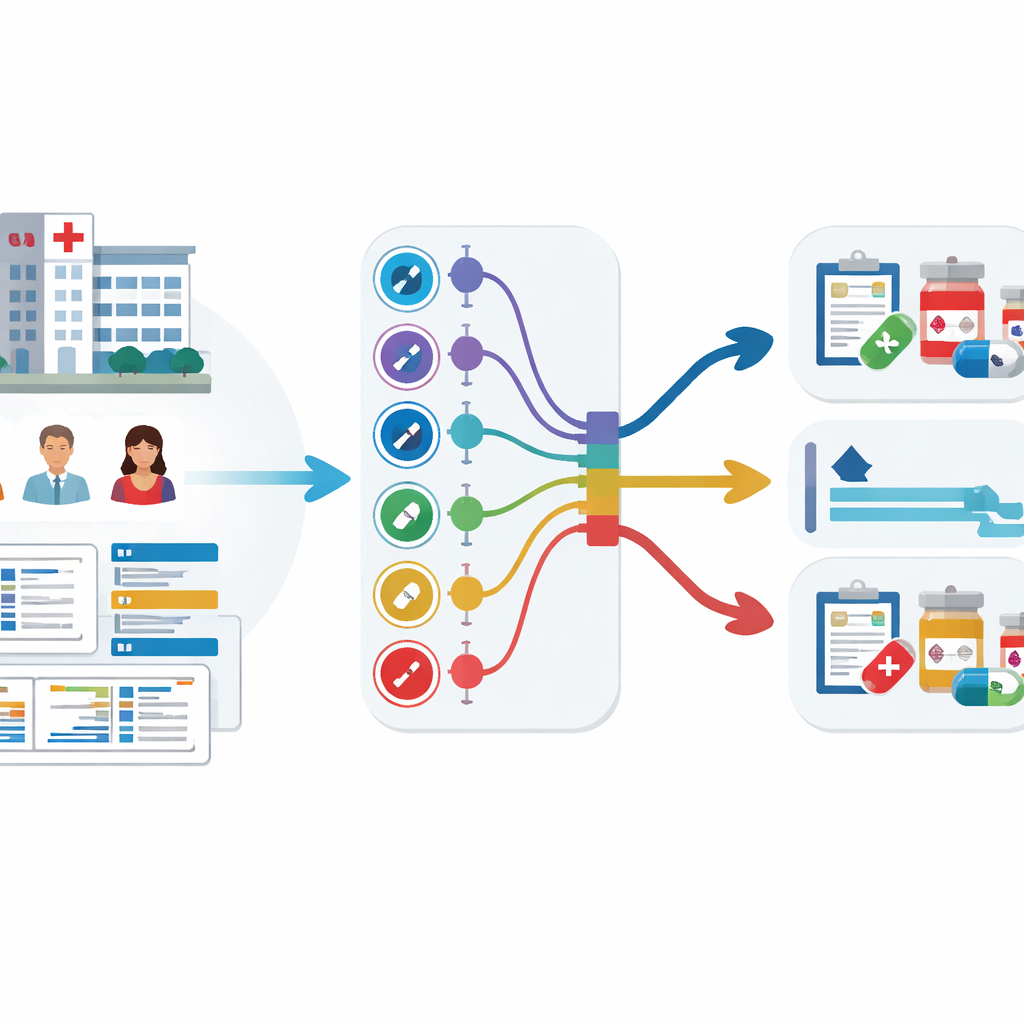
Ziekenhuisgegevens omzetten in vroege waarschuwingen
Het team analyseerde elektronische medische dossiers van 59.551 volwassen patiënten in drie grote Koreaanse ziekenhuizen over meer dan een decennium. Deze dossiers bevatten leeftijd, vitale functies, verblijfsduur, eerder antibioticagebruik en, cruciaal, eerdere kweekresultaten die lieten zien welke antibiotica al hadden gefaald. In plaats van negen afzonderlijke modellen te trainen—één voor elke antibioticagroep—gebruikten ze een strategie genaamd multi-task learning, waarmee één model meerdere gerelateerde voorspeltaken tegelijk kan leren. Er werden twee versies getest: één met een gedeelde kern die uitsplitst naar aparte uitgangen voor elke antibioticagroep (hard sharing), en één waarin de taken losser met elkaar verbonden zijn (soft sharing).
Het probleem van onvolledige labresultaten oplossen
Reële ziekenhuisgegevens zijn rommelig: niet elke patiënt wordt tegen elk antibioticum getest. Eerdere studies verwijderden vaak deze deels gelabelde gevallen, waardoor hun datasets kleiner werden en patronen die over verschillende middelen heen liepen werden genegeerd. Hier hebben de onderzoekers de leeregel van het model herschreven zodat het simpelweg missende labresultaten overslaat bij het berekenen van de trainingsfout. Hierdoor konden ze vrijwel alle patiënten in de analyse houden, zelfs wanneer sommige antibioticumresultaten ontbraken. Vooral het hard-sharing model profiteerde van deze opzet, omdat het gemeenschappelijke signalen van resistentie kon leren terwijl het toch zijn voorspellingen voor elke geneesmiddelengroep verfijnde.
Hoe goed presteerden de modellen?
Getest op gegevens van ziekenhuizen die ze nog niet hadden gezien, presteerden de multi-task modellen over het algemeen beter dan meer traditionele methoden zoals logistische regressie en standaard boosting-algoritmen. Gemiddeld toonde het hard-sharing model de beste balans tussen nauwkeurigheid en stabiliteit over de negen antibioticaklassen, en het was bijzonder sterk voor geneesmiddelengroepen met de schaarste aan data, zoals aminoglycosiden. Een afzonderlijke analyse die verklaart welke kenmerken de voorspellingen aandrijven, toonde aan dat eerder resistentie bij een patiënt voor een antibioticum de belangrijkste factor was, gevolgd door resistentie of gebruik van verwante middelen, en ook leeftijd en verblijfsduur. Subgroepanalyses lieten zien dat hard sharing het beste werkte wanneer eerdere kweekresultaten voor een bepaald antibioticum beschikbaar waren, terwijl soft sharing beter presteerde wanneer zulke geschiedenis ontbrak.
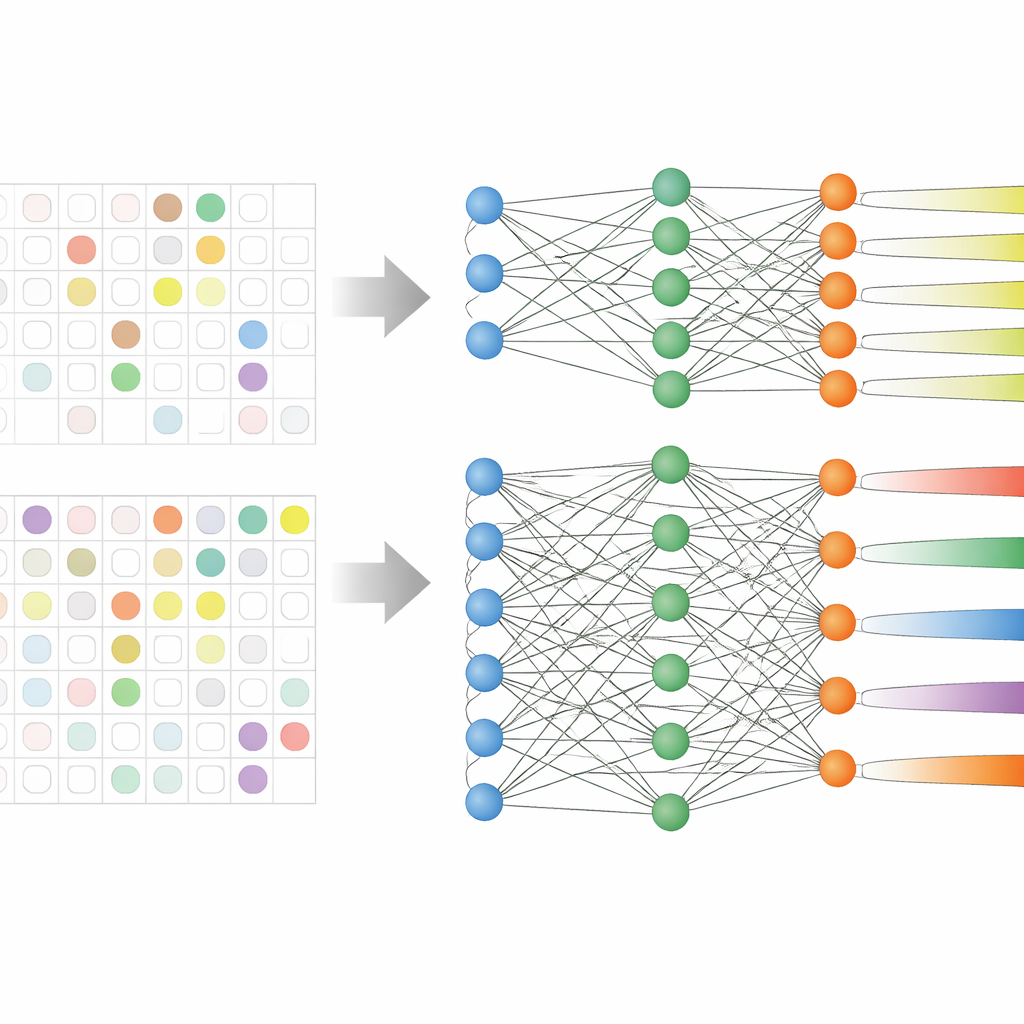
Wat dit betekent voor patiënten en clinici
De studie suggereert dat slim gebruik van ziekenhuisgegevens vroege, redelijk betrouwbare voorspellingen van antibioticumresistentie over meerdere belangrijke geneesmiddelfamilies kan opleveren. Zelfs bescheiden verbeteringen in voorspellingen, toegepast op grote aantallen patiënten, kunnen artsen helpen sneller te kiezen voor smallere, meer gerichte antibiotica en met meer vertrouwen af te bouwen van brede middelen. Dat kan op zijn beurt complicaties verminderen, ziekenhuisverblijven verkorten en de algehele march van resistentie vertragen. De auteurs waarschuwen dat hun model nog in de echte wereld getest en verfijnd moet worden, vooral wanneer eerdere kweekgegevens ontbreken, maar ze betogen dat multi-task learning een veelbelovende manier is om beter gebruik te maken van imperfecte medische data en zorgvuldiger antibioticagebruik te ondersteunen.
Bronvermelding: Kim, Y., Jeong, I., Park, JH. et al. Multi task learning based early prediction model for antibiotic resistance using multi institutional cohort data. Sci Rep 16, 11891 (2026). https://doi.org/10.1038/s41598-026-41185-z
Trefwoorden: antibioticaresistentie, klinische beslissingsondersteuning, elektronische patiëntendossiers, machine learning, multi-task learning