Clear Sky Science · de
Frühvorhersagemodell für Antibiotikaresistenz auf Basis von Multi-Task-Learning mit multi-institutionellen Kohortendaten
Warum das für die alltägliche Versorgung wichtig ist
Antibiotikaresistenz verwandelt still und leise einst gut behandelbare Infektionen in lebensbedrohliche Erkrankungen. Ärztinnen und Ärzte müssen häufig eine Antibiotikawahl treffen, bevor Laboruntersuchungen zeigen, welche Wirkstoffe noch wirksam sind – ein Zeitraum, der mehrere Tage in Anspruch nehmen kann. Diese Studie untersucht, wie Computer‑Modelle, die auf Krankenhausdaten trainiert wurden, Ärztinnen und Ärzten frühzeitig Hinweise darauf geben können, welche Antibiotika wahrscheinlich versagen, um so Patienten zu schützen und die Ausbreitung resistenter Keime zu verlangsamen.
Antibiotika unter Druck
Die moderne Medizin ist in vielen Bereichen – von Routineoperationen bis zur Krebsbehandlung – stark auf Antibiotika angewiesen. Gleichzeitig passen sich Bakterien schnell an, während neue Antibiotika langsamer kommen, als alte an Wirksamkeit verlieren. In Südkorea, wo die Studie durchgeführt wurde, werden bis zu einem Drittel der Antibiotikaverschreibungen im Krankenhaus als unangemessen bewertet. Kulturtests, die zeigen, ob ein Erreger resistent ist, dauern meist drei bis fünf Tage, sodass Ärztinnen und Ärzte zunächst im Dunkeln therapieren müssen. Die Forschenden zielten darauf ab, die Resistenz gegenüber neun wichtigen Antibiotikagruppen vorherzusagen – und zwar allein mit Informationen, die früh im Krankenhausaufenthalt verfügbar sind.
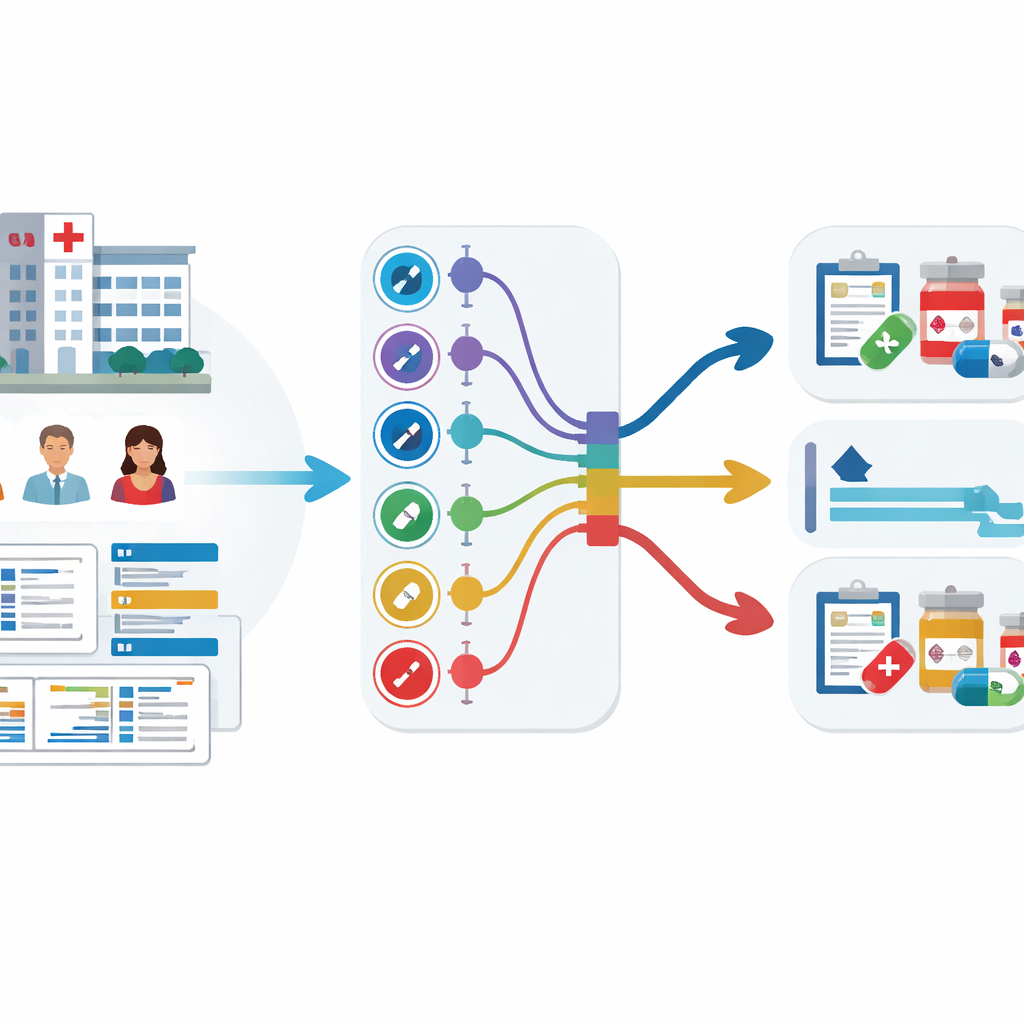
Krankenhausdaten in Frühwarnungen verwandeln
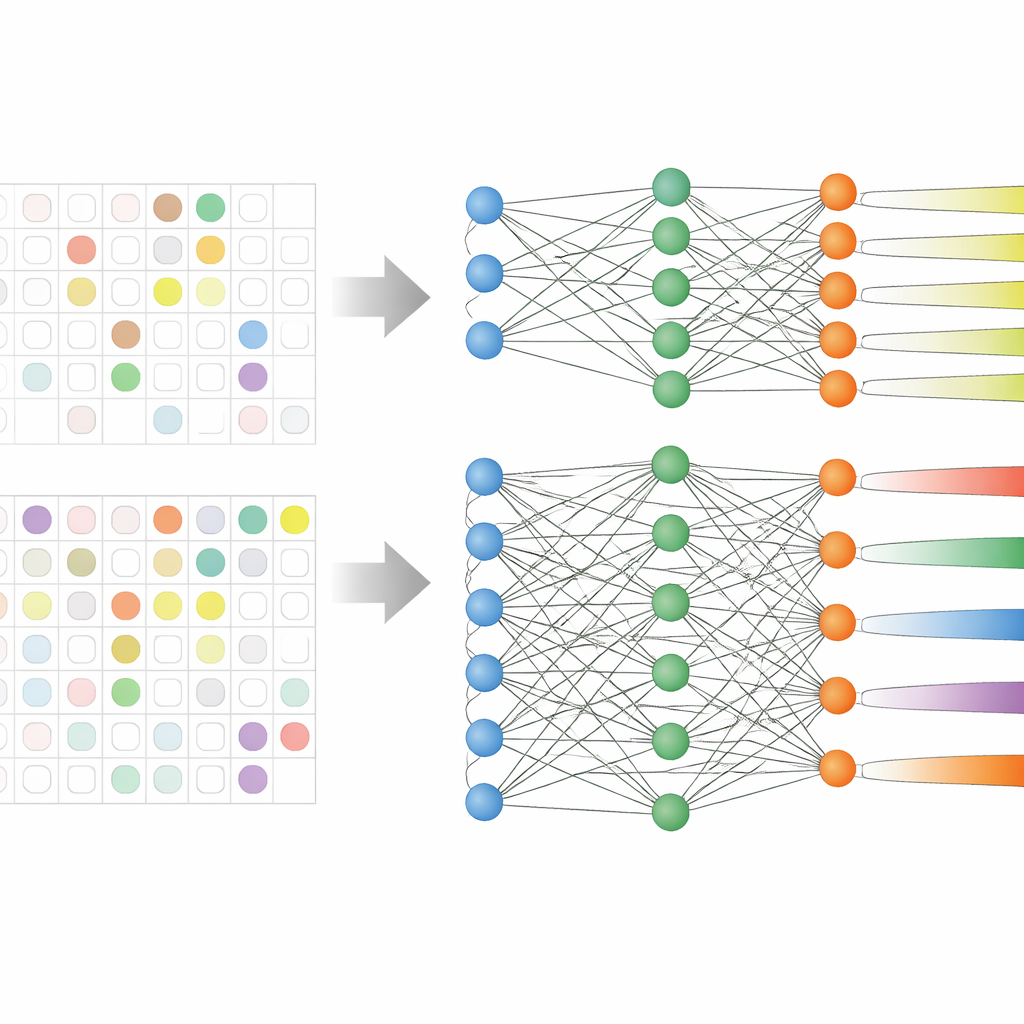
Das Team analysierte elektronische Krankenakten von 59.551 erwachsenen Patientinnen und Patienten aus drei großen koreanischen Krankenhäusern über mehr als ein Jahrzehnt. Diese Datensätze enthielten Alter, Vitalzeichen, Aufenthaltsdauer, frühere Antibiotikaanwendungen und – entscheidend – frühere Kulturtestergebnisse, die zeigten, welche Antibiotika bereits versagt hatten. Anstatt neun separate Modelle zu trainieren – eines für jede Antibiotikagruppe – nutzten sie eine Strategie namens Multi‑Task‑Learning, die es einem einzigen Modell erlaubt, mehrere verwandte Vorhersageaufgaben gleichzeitig zu lernen. Getestet wurden zwei Varianten: eine mit einem geteilten Kern, der in separate Ausgänge für jede Antibiotikagruppe verzweigt (hard sharing), und eine, in der die Aufgaben lockerer verknüpft sind (soft sharing).
Das Problem unvollständiger Laborergebnisse lösen
Echte Krankenhausdaten sind unordentlich: Nicht jeder Patient wird gegen jedes Antibiotikum getestet. Frühere Studien schlossen solche teilweise beschrifteten Fälle häufig aus, wodurch Datensätze schrumpften und Muster, die verschiedene Wirkstoffe verbanden, verloren gingen. Die Forschenden passten hier die Lernregel des Modells so an, dass fehlende Laborergebnisse bei der Berechnung des Trainingsfehlers einfach übersprungen werden. Dadurch konnten sie nahezu alle Patientinnen und Patienten in der Analyse behalten, selbst wenn für einige Antibiotika Ergebnisse fehlten. Besonders das Hard‑Sharing‑Modell profitierte von diesem Vorgehen, weil es gemeinsame Signale für Resistenz lernen und zugleich seine Vorhersagen für jede Wirkstoffgruppe feinabstimmen konnte.
Wie gut haben die Modelle abgeschnitten?
Bei Tests an Daten aus zuvor ungesehenen Krankenhäusern übertrafen die Multi‑Task‑Modelle im Allgemeinen traditionellere Verfahren wie logistische Regression und Standard‑Boosting‑Algorithmen. Im Mittel zeigte das Hard‑Sharing‑Modell die beste Balance aus Genauigkeit und Stabilität über die neun Antibiotikaklassen hinweg und war besonders stark für Wirkstoffgruppen mit den geringsten Datenmengen, etwa Aminoglykoside. Eine separate Analyse zur Interpretierbarkeit ergab, dass frühere Resistenz eines Patienten gegenüber einem Antibiotikum der einzel wichtigste Faktor war, gefolgt von Resistenz oder Nutzung verwandter Wirkstoffe sowie Alter und Aufenthaltsdauer. Subgruppenanalysen zeigten, dass Hard Sharing am besten funktionierte, wenn frühere Kulturresultate für ein bestimmtes Antibiotikum vorlagen, während Soft Sharing besser abschnitt, wenn eine solche Vorgeschichte fehlte.
Was das für Patientinnen, Patienten und Kliniker bedeutet
Die Studie legt nahe, dass eine intelligente Nutzung von Krankenhausdaten frühe, relativ verlässliche Vorhersagen zur Antibiotikaresistenz über mehrere wichtige Wirkstofffamilien liefern kann. Selbst moderate Verbesserungen der Vorhersagegenauigkeit, angewandt auf viele Patientinnen und Patienten, könnten Ärztinnen und Ärzten helfen, früher gezieltere und schmaler wirkende Antibiotika zu wählen und mit größerer Sicherheit von breiten Wirkstoffen abzusteigen. Das könnte Komplikationen verringern, Krankenhausaufenthalte verkürzen und die Ausbreitung von Resistenzen bremsen. Die Autorinnen und Autoren warnen jedoch, dass ihr Modell noch reale Tests und Feinabstimmungen benötigt, besonders wenn frühere Kulturdaten fehlen; dennoch sehen sie im Multi‑Task‑Learning einen vielversprechenden Weg, unvollständige medizinische Daten besser zu nutzen und umsichtigeren Antibiotikaeinsatz zu unterstützen.
Zitation: Kim, Y., Jeong, I., Park, JH. et al. Multi task learning based early prediction model for antibiotic resistance using multi institutional cohort data. Sci Rep 16, 11891 (2026). https://doi.org/10.1038/s41598-026-41185-z
Schlüsselwörter: Antibiotikaresistenz, klinische Entscheidungsunterstützung, elektronische Gesundheitsakten, maschinelles Lernen, Multi-Task-Learning