Clear Sky Science · nl
Toegankelijke voorspelling van geneesmiddelbijwerkingen in het centrale zenuwstelsel via biologisch geïnformeerd grafneuraal netwerk
Waarom verborgen geneesmiddelrisico’s ertoe doen
Veel medicijnen die onze hersenen helpen, kunnen ze ook ongemerkt schaden. Duizeligheid, verwarring, aanvallen of depressie kunnen pas optreden nadat een geneesmiddel algemeen is gebruikt. Traditionele laboratorium‑ en klinische tests zijn te traag en te duur om elk mogelijk probleem vóór goedkeuring te detecteren, vooral voor het centrale zenuwstelsel, waar bijwerkingen subtiel maar levensveranderend kunnen zijn. Deze studie introduceert een nieuw computermodel dat grote biologische datasets doorzoekt om vroegtijdig waarschijnlijke hersengerelateerde bijwerkingen aan te geven en de keten van moleculaire gebeurtenissen te tonen die ze mogelijk veroorzaken.
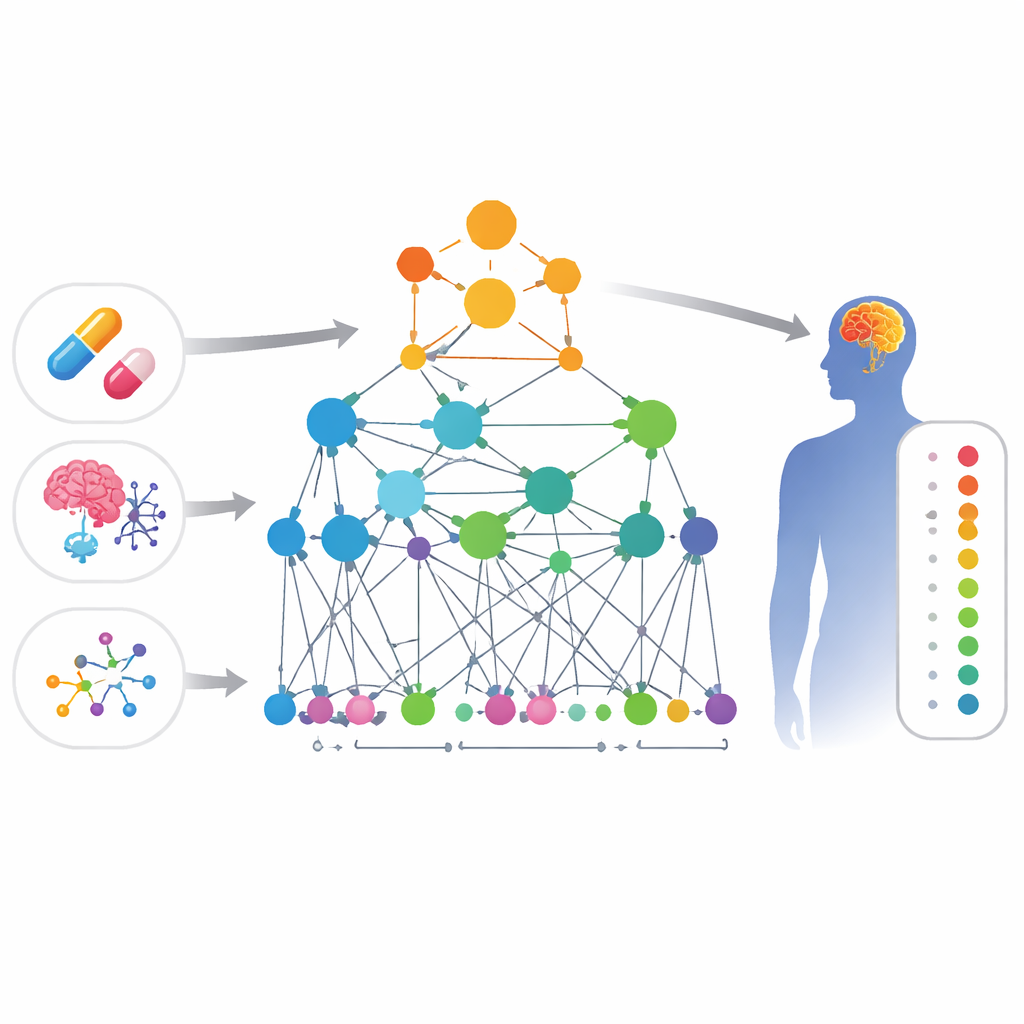
De verbanden leggen tussen medicijnen en symptomen
De onderzoekers bouwden een grote “kaart” van biologische kennis die vier soorten entiteiten koppelt: geneesmiddelen, bijwerkingen, genen en genfuncties. In deze kaart is elk item een punt en lijnen tussen punten geven bewijs dat ze gerelateerd zijn — bijvoorbeeld twee genen die fysiek met elkaar interageren, twee geneesmiddelen met vergelijkbare chemische structuren, of een geneesmiddel waarvan bekend is dat het een bepaalde bijwerking veroorzaakt. Omdat klachten van het centrale zenuwstelsel zowel veelvoorkomend als vaak over het hoofd gezien worden, richtte het team deze kaart op hersengerelateerde problemen zoals stemmingsveranderingen, bewegingsstoornissen en andere neurologische symptomen.
Een slim netwerk dat biologie leert
Bovenop deze kaart ontwierpen de auteurs een gespecialiseerde vorm van kunstmatige intelligentie: een grafneuraal netwerk. In tegenstelling tot een standaardmodel dat elk geneesmiddel geïsoleerd bekijkt, kijkt deze benadering naar het web van verbindingen rond elk geneesmiddel en elke bijwerking. Het model, HHAN‑DSI genoemd, is “biologisch geïnformeerd”: het mag alleen informatie doorgeven langs paden die biologisch logisch zijn — bijvoorbeeld van het ene gen naar een gen waarmee het direct interageert, van een gen naar een geneesmiddel dat het target, en vervolgens van dat geneesmiddel naar bijwerkingen die gezien zijn bij soortgelijke geneesmiddelen. Door meer gewicht te geven aan de meest informatieve paden, leert het systeem compacte wiskundige vingerafdrukken voor elk geneesmiddel en elke bijwerking en beoordeelt het hoe waarschijnlijk het is dat een bepaald paar verbonden is.
Het model op de proef stellen
Om te beoordelen of deze voorspellingen overeenkomen met de werkelijkheid, trainde het team het model op een gecureerde database van bijwerkingen die in officiële productinformatie zijn gerapporteerd en testte het vervolgens tegen zowel deze bron als een aparte set post‑marketing veiligheidsrapporten. Deze externe rapporten vangen problemen op die pas aan het licht kwamen nadat geneesmiddelen algemeen werden gebruikt. Het model onderscheidde niet alleen echte geneesmiddel–bijwerkingparen van valse, maar plaatste, nog belangrijker, de meest zorgwekkende effecten hoog in zijn ranglijsten. Het presteerde beter dan verschillende bestaande machine‑learningmethoden bij deze rangschikkingstaak, vooral wanneer gegevens schaars waren, zoals typisch is voor nieuwe geneesmiddelen. In veel gevallen waarin het model ‘fout’ leek omdat een voorspelde bijwerking ontbrak in de gecureerde database, verscheen dezelfde geneesmiddel–symptoomkoppeling in de real‑world veiligheidsrapporten, wat suggereert dat het model over het hoofd geziene risico’s had gevonden.
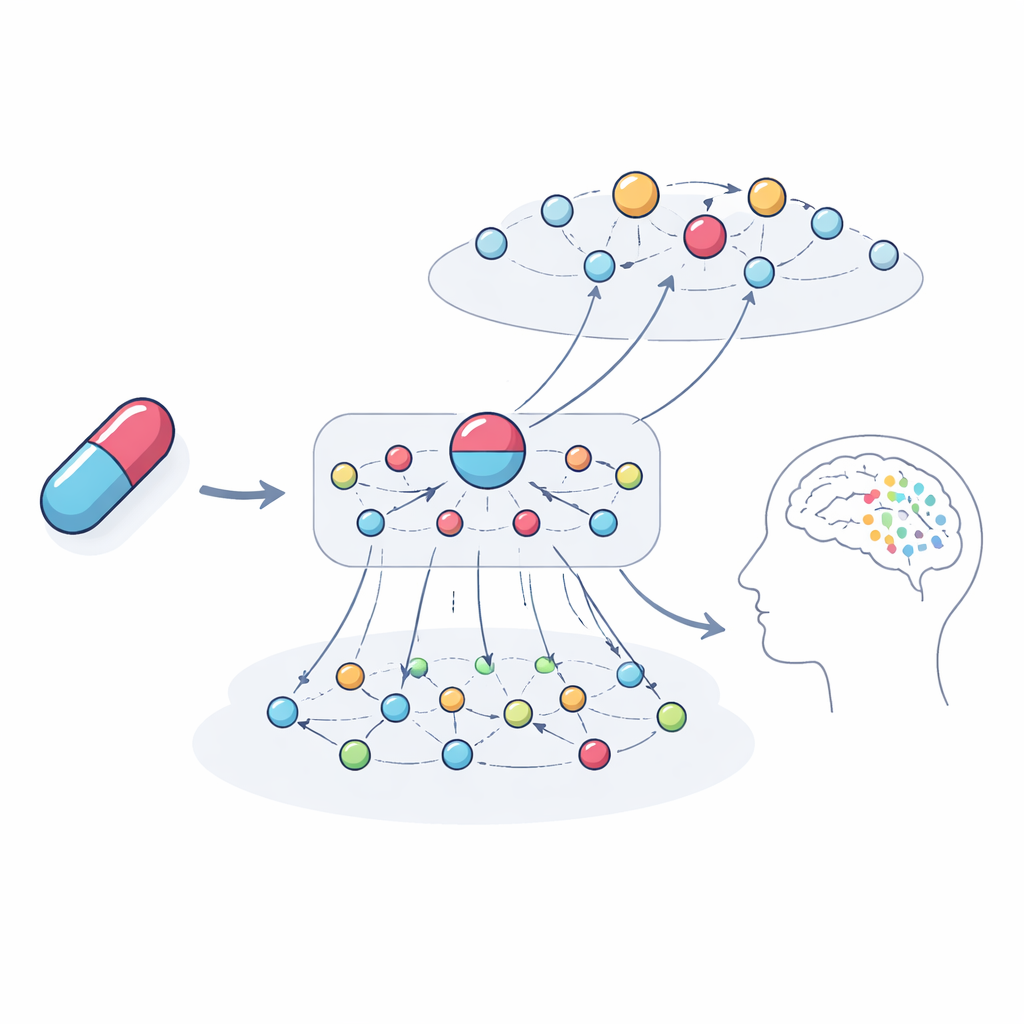
In de zwarte doos kijken
Een belangrijk doel was niet alleen problemen voorspellen maar ze ook verklaren. De auteurs traceerden de meest invloedrijke ketens van verbindingen die het model gebruikte voor concrete voorbeelden. Voor het anestheticum en antidepressivum ketamine benadrukte het systeem netwerken van genen en gerelateerde geneesmiddelen die wijzen op hallucinaties en depressie als mogelijke uitkomsten. Deze paden betrokken genfamilies die verbonden zijn met dopamine‑ en serotoninesignalering, immuun‑ en hormonale routes, en geneesmiddelen met vergelijkbare doelen die case‑rapporten hebben van soortgelijke problemen. Toen het team de door het model benadrukte genen analyseerde, vonden ze dat deze sterk verrijkt waren voor processen die al bekend zijn als bepalend voor hersenfunctie en psychiatrische symptomen, wat versterkt dat de verklaringen biologisch zinvol zijn in plaats van willekeurig.
Wat dit betekent voor patiënten en toekomstige geneesmiddelen
Simpel gezegd toont dit werk aan dat het mogelijk is bestaande biologische en veiligheidsgegevens te gebruiken om een vroegwaarschuwingssysteem voor hersengerelateerde bijwerkingen te bouwen — en om te laten zien waarom die waarschuwingen ontstaan. HHAN‑DSI is niet bedoeld ter vervanging van artsen of klinische proeven, maar om onderzoekers en veiligheidsexperts te helpen prioriteren welke potentiële bijwerkingen onderzocht en gemonitord moeten worden, vooral voor nieuwe geneesmiddelen met weinig directe ervaring. Door licht te werpen op de moleculaire paden die medicijnen met ongewenste symptomen verbinden, kan de benadering veiliger geneesmiddelenontwerp, gerichtere surveillance en uiteindelijk betere bescherming bieden voor patiënten die afhankelijk zijn van behandelingen die op de hersenen werken.
Bronvermelding: Huang, T., Lin, KH., Machado-Vieira, R. et al. Explainable drug side effect prediction in central neural system via biologically informed graph neural network. Transl Psychiatry 16, 205 (2026). https://doi.org/10.1038/s41398-026-03971-1
Trefwoorden: geneesmiddelbijwerkingen, centraal zenuwstelsel, grafneurale netwerken, farmacovigilantie, verklaarbare AI