Clear Sky Science · it
CREsted: modellare enhancer genomici e sintetici specifici per tipo cellulare attraverso tessuti e specie
Perché contano i piccoli interruttori nel DNA
Ogni cellula del tuo corpo porta lo stesso DNA, eppure le cellule cerebrali, del sangue e muscolari si comportano in modo molto diverso. Una ragione importante è uno strato nascosto di controllo composto da brevi interruttori di DNA chiamati enhancer, che decidono quando e dove i geni si attivano. Questo articolo presenta CREsted, un toolkit software che usa l’intelligenza artificiale moderna per leggere questi interruttori direttamente dal DNA e persino progettarne di nuovi. Il lavoro mostra come si possa passare dal semplice elenco di parti genetiche alla comprensione attiva e all’ingegneria di tali elementi attraverso tessuti e specie.
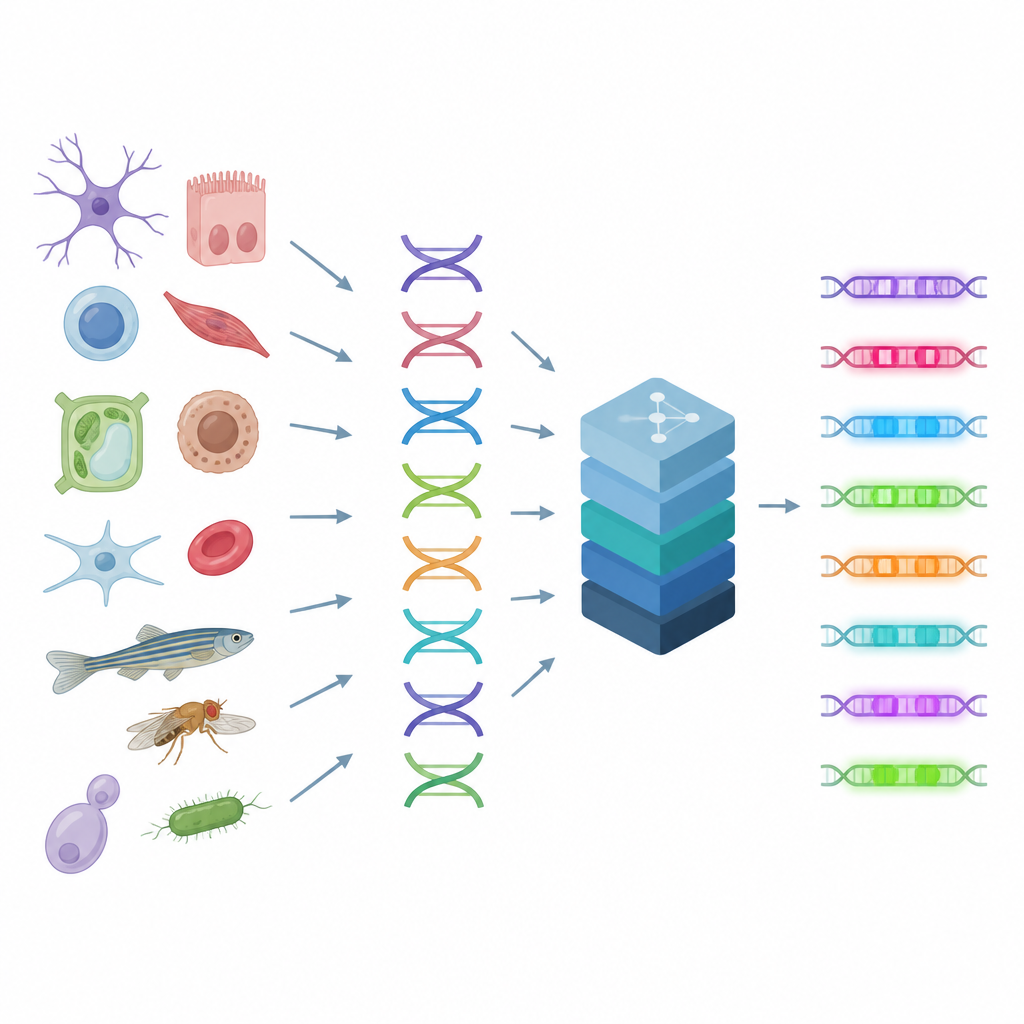
Leggere gli interruttori di controllo della cellula
Gli enhancer funzionano come manopole su una consolle, combinando segnali da molte proteine per mettere a punto l’attività genica in ogni tipo cellulare. Poiché più pattern di DNA possono produrre risultati simili, le regole che governano gli enhancer sono complesse e difficili da intuire a occhio nudo. Gli autori si basano su una tecnica che misura quanto ogni tratto di DNA è aperto o chiuso in migliaia di singole cellule, un indizio che rivela dove si trovano gli enhancer attivi nel genoma. CREsted prende queste misure, le collega alle sequenze di DNA sottostanti e addestra modelli di deep learning per prevedere quanto ogni regione sarà accessibile in molti tipi cellulari contemporaneamente. Questo trasforma la sequenza grezza in una mappa dell’attività regolatoria.
Un toolkit dai dati all’intuizione
CREsted è più di un singolo modello: è una pipeline end-to-end. Prima pulisce e rimodella i dati single-cell in una forma che riduce i bias tecnici tra i tipi cellulari. Poi addestra reti neurali flessibili che possono classificare regioni attive o prevedere valori graduati di accessibilità. Importante, CREsted non si ferma alla previsione. Può approfondire per identificare quali singole lettere del DNA contano di più per un dato tipo cellulare, raggruppare pattern ricorrenti e associare questi pattern a probabili proteine regolatrici usando database esistenti e dati di espressione genica. Infine, include strumenti di progettazione che “evolvono” iterativamente sequenze di DNA sintetiche in modo che il modello predica un’alta attività in un tipo cellulare scelto e poca attività altrove.
Testare il toolkit nel cervello, nel sangue, nel cancro e nel pesce
Gli autori dimostrano CREsted su diversi dataset ricchi. nella corteccia motoria del topo, i loro modelli prevedono con alta accuratezza quali regioni del DNA sono aperte in diversi tipi di neuroni e cellule di supporto, superando un quadro di riferimento generalista. Evidenziando pattern chiave di sequenza, CREsted recupera proteine regolatrici note per classi neuronali specifiche e può persino spiegare come una singola variazione di lettera in un motivo possa spostare l’attività tra sottotipi neuronali. Nelle cellule del sangue umano, un modello correlato riscopre molti siti di legame precedentemente testati in enhancer immunitari classici e si allinea bene con esperimenti indipendenti di binding proteico, a supporto del fatto che i pattern di sequenza appresi sono biologicamente significativi.
CREsted esplora anche questioni più applicate. Nel cancro, confronta uno stato cellulare “mesenchimale-like” che appare sia nel melanoma sia nel glioblastoma, usando modelli addestrati su linee cellulari e su campioni tumorali dei pazienti. I pattern degli enhancer mostrano temi condivisi ma anche differenze importanti, come motivi specifici presenti solo nei tumori. In un altro test, gli autori si chiedono se modelli “foundation” specializzati e addestrati su vasti dataset genomici sovraperformino davvero modelli più piccoli focalizzati sul compito. Dopo un fine tuning accurato, questi grandi modelli faticano ancora a eguagliare la risoluzione specifica per tipo cellulare dell’architettura di CREsted, suggerendo che l’addestramento dedicato su dati single-cell di alta qualità resta cruciale.
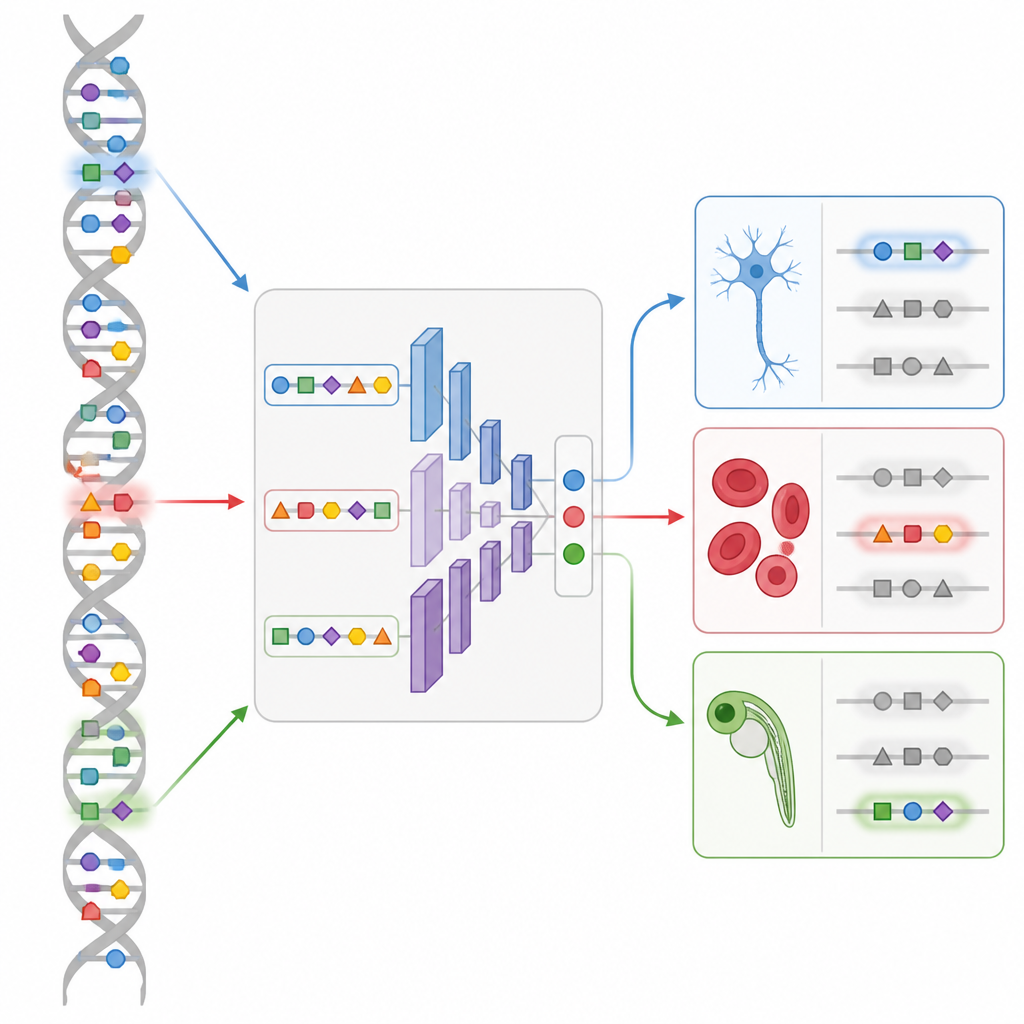
Progettare nuovi interruttori in un embrione vivente
La dimostrazione più sorprendente proviene dallo sviluppo della zebra fish. Utilizzando una mappa single-cell dell’accessibilità del DNA attraverso molti stadi embrionali, il team addestra un modello CREsted chiamato DeepZebrafish. Successivamente il modulo di progettazione genera enhancer completamente sintetici predetti per attivarsi solo nel muscolo cardiaco, solo nel muscolo scheletrico, solo nell’endotelio vascolare, o in combinazioni controllate di cuore e muscolo. Quando queste sequenze artificiali sono poste davanti a un reporter fluorescente e iniettate nelle uova di pesce, molte si illuminano esattamente nei tessuti desiderati. L’analisi delle loro sequenze rivela pattern riconoscibili per i principali regolatori dello sviluppo, confermando che il modello ha catturato una “grammatica” significativa piuttosto che stranezze casuali.
Cosa significa per la comprensione e l’ingegneria dei genomi
Per un non specialista, CREsted può essere visto come un microscopio per lo strato regolatorio del genoma e uno strumento di progettazione per nuove parti genetiche. Traduce tratti di DNA in previsioni su quali tipi cellulari li useranno, indica le lettere e i motivi chiave che guidano quel comportamento e può suggerire nuove sequenze che dovrebbero comportarsi in modo desiderato. Lavorando attraverso cervello, sangue, cancro e organismi in sviluppo, lo studio mostra che un approccio unificato può rivelare regole condivise e specifiche per tipo cellulare del controllo genico. A lungo termine, tali strumenti potrebbero aiutare i ricercatori a costruire marcatori genetici più precisi, migliorare i modelli di malattia e comprendere meglio come piccole variazioni nel DNA possano propagarsi attraverso cellule e tessuti.
Citazione: Kempynck, N., De Winter, S., Blaauw, C.H. et al. CREsted: modeling genomic and synthetic cell-type-specific enhancers across tissues and species. Nat Methods 23, 946–959 (2026). https://doi.org/10.1038/s41592-026-03057-2
Parole chiave: modellazione degli enhancer, genomica con deep learning, cromatina single-cell, elementi regolatori cis, enhancer sintetici