Clear Sky Science · zh
通过抽样提升深度神经网络性能
用小小的掷币神经元实现更聪明的 AI
随着人工智能变得更强大,它对能量的需求也猛增。训练和运行现代图像与语言模型消耗的电力有时可与小城镇相当。本文探讨了一个看似反直觉的想法:与其让神经网络变得越来越精确和复杂,不如把其构件做得更简单、更嘈杂——更像抛掷数字硬币——然后用巧妙的抽样方法来获得等效甚至更好的结果,同时节省能量。
从精确电路到概率大脑
当今大多数深度神经网络使用“确定性”单元:输入相同的数据就总会得到相同的输出。作者关注另一种替代方案,称为概率比特(p-bit)。每个 p-bit 的行为像一个带偏置的小硬币,根据输入设定的概率在 0 与 1 之间翻转。通过对同一网络的 p-bit 进行多次采样并平均它们的输出,系统可以在不存储或搬移大量精确数值的情况下,近似实现更丰富的多位行为。这个想法将现代 AI 与早期的伊辛(Ising)和玻尔兹曼机(Boltzmann machines)联系起来,在那些模型中,这类概率单元已被证明在优化和抽样问题上高效。
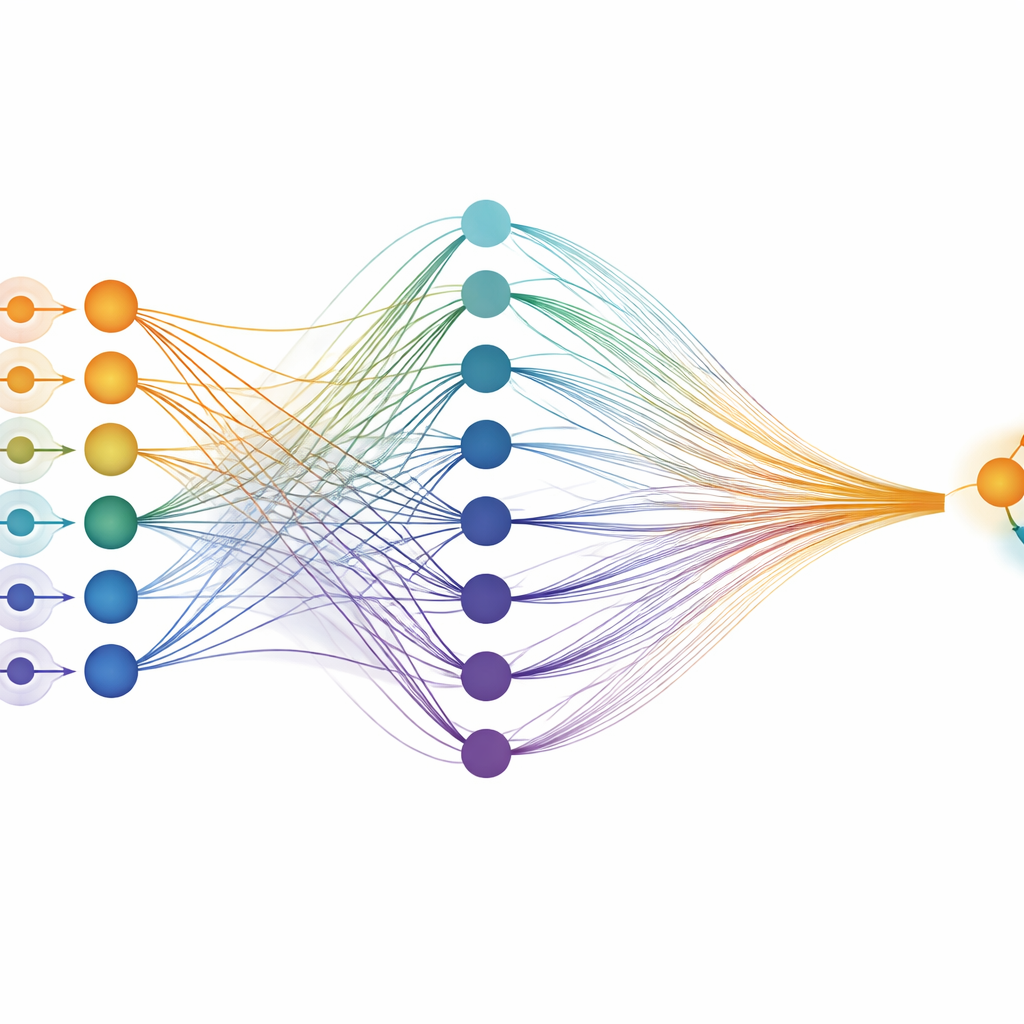
用许多快速猜测替代一次沉重的答案
研究提出了一个简单但务实的问题:如果我们想提高准确性,增加每个神经元的数字精度更划算,还是保持神经元极其简单然后对其进行多次采样更划算?作者建立了一个通用能量公式,将神经网络中一次基本运算的成本分解为四部分:从存储器读取权重、读取和写入激活值、合并输入(突触)以及施加非线性(神经元)。重要的是,权重可以读取一次然后重用以生成多个样本,因此主导成本——存储器访问——可以分摊到多次运行上。这意味着十次采样的成本远低于十倍于一次的成本。
在图像上测试概率网络
为了验证这一权衡在实践中是否奏效,研究者在图像分类(CIFAR-10)和图像生成(CelebA 的人脸与 MNIST 的数字)上测试了概率深度神经网络(p-DNN)。他们用单比特的 p-bit 替换了标准的多位激活信号,并以“样本感知”的方式训练网络,在这种训练中损失函数由多次随机前向传递的平均值计算而得。对于分类任务,他们发现即使采用 1 位激活,仅一次采样就能匹配全精度模型的准确率,两个样本则能超过它。随着样本数增加,1 位 p-DNN 的准确性接近 3 位确定性网络。对于图像生成,直接用 p-bit 替换激活会产生噪点图像,但在包含真实随机性的再训练并谨慎处理最后一层后,生成的人脸图像在标准距离度量下的质量几乎能达到 32 位基线水平。
能量开销与真实硬件
作者不仅做了仿真,还在真实硬件上考察了能量消耗。利用一块为概率电路设计的 65 nm 芯片数据和额外的电路仿真,他们表明大规模现代 AI 工作负载的主导能耗来自存储器,而非算术运算。因为 p-DNN 将主要计算步骤从完整的乘加大幅简化为使用 1 位激活的简单加法,当权重存放在耗电的外部存储器时,为了多次采样增加的额外计算几乎不会显著改变总能量。他们在 FPGA 上实现了一个图像生成网络来验证这些预测:概率版本与标准设计相比,将每次推断的整体能耗降低了约 2.5 倍,同时生成的数字图像质量相当。随机数生成和比较操作的开销相对于存储和基础算术非常小。
可调采样为何重要
概率网络的一个显著好处是可以通过在运行时改变采样次数来调节准确性。单个 1 位 p-DNN 引擎可以根据采样次数表现得像 1 位、2 位或 3 位量化模型,而无需重新设计硬件。这种灵活性对大型语言模型尤为吸引:权重精度已经被压缩到几位,而激活精度很难在不损害质量的情况下大幅降低。本文的框架展示了如何为任何此类模型估算:与提高位宽相比,额外采样是否在能量上划算。
通向高效且灵活 AI 的新途径
通俗地说,论文表明可以利用而非回避“嘈杂”的神经单元。将每一次前向传递视为一次廉价的近似猜测,然后平均少量这些猜测,网络就能在计算大幅简化且能量开销适中的情况下达到接近全精度的性能。由于存储器在能源账单中占主导地位,多次采样的成本较小,尤其是在权重只读取一次并被重用时。这为更节能且可按需适应的 AI 硬件指明了有前景的方向——通过调节采样次数来在精度、续航与速度之间权衡。
引用: Ghantasala, L.A., Li, MC., Jaiswal, R. et al. Improving deep neural network performance through sampling. npj Unconv. Comput. 3, 18 (2026). https://doi.org/10.1038/s44335-026-00063-7
关键词: 概率神经网络, 节能型人工智能, 基于抽样的推断, 低精度计算, 深度学习硬件