Clear Sky Science · pl
Poprawa wydajności głębokich sieci neuronowych przez próbkowanie
Sprytniejsza SI z maleńkimi neuronami jak rzut monetą
W miarę jak sztuczna inteligencja staje się potężniejsza, rośnie też jej apetyt na energię. Trenowanie i uruchamianie współczesnych modeli obrazowych i językowych może pobierać tyle prądu, co małe miasteczka. Artykuł bada kontrintuicyjną ideę: zamiast robić bloki sieci neuronowych coraz bardziej precyzyjnymi i złożonymi, można uprościć ich elementy i uczynić je bardziej „hałaśliwymi” — bardziej przypominającymi rzut cyfrową monetą — a następnie zastosować sprytne próbkowanie, by osiągnąć równoważne lub lepsze wyniki przy mniejszym zużyciu energii.
Od precyzyjnych układów do probabilistycznych mózgów
Większość dzisiejszych głębokich sieci neuronowych używa jednostek „deterministycznych”: podając te same dane wejściowe, zawsze otrzymujesz ten sam wynik. Autorzy skupiają się na alternatywie zwanej bitami probabilistycznymi, czyli p-bitami. Każdy p-bit zachowuje się jak mała, niewyważona moneta, która przełącza się między 0 a 1 zgodnie z prawdopodobieństwami ustalonymi przez jego wejścia. Pobierając kilka próbek z tej samej sieci p-bitów i uśredniając ich wyjścia, system może przybliżać bogatsze, wielobitowe zachowanie bez przechowywania czy manipulowania tak wieloma precyzyjnymi wartościami. Pomysł ten łączy nowoczesną SI z wcześniejszymi maszynami Isinga i Boltzmanna, gdzie jednostki probabilistyczne już były uznawane za efektywne w zadaniach optymalizacji i próbkowania.
Wiele szybkich zgadywek zamiast jednej ciężkiej odpowiedzi
Badanie stawia proste, ale praktyczne pytanie: jeśli chcemy lepszej dokładności, czy taniej jest zwiększyć precyzję każdego neuronu, czy utrzymać neurony ekstremalnie prostymi i zamiast tego pobierać z nich wiele próbek? Autorzy formułują ogólny wzór energetyczny, który rozkłada koszt jednej podstawowej operacji w sieci neuronowej na cztery części: odczyt wag z pamięci, odczyt i zapis aktywacji, łączenie wejść (synapsa) oraz zastosowanie nieliniowości (neuron). Co ważne, wagi można odczytać raz i potem użyć do wygenerowania wielu próbek, więc dominujący koszt — dostęp do pamięci — można rozłożyć na wiele przebiegów. Oznacza to, że dziesięć próbek jest znacznie tańsze niż dziesięć razy koszt jednej próbki.
Testowanie sieci probabilistycznych na obrazach
Aby sprawdzić, czy ten kompromis opłaca się w praktyce, badacze testują probabilistyczne głębokie sieci neuronowe (p-DNN) w zadaniach klasyfikacji obrazów (CIFAR-10) oraz generowania obrazów (twarze z CelebA i cyfry z MNIST). Zastępują standardowe wielobitowe sygnały aktywacji pojedynczymi bitami p-bit i trenują sieci w sposób „świadomy próbkowania”, gdzie funkcja straty jest obliczana na podstawie średniej z kilku stochastycznych przebiegów w przód. W zadaniach klasyfikacji okazuje się, że nawet przy aktywacjach 1-bitowych jedna próbka może dorównać dokładności modelu o pełnej precyzji, a dwie próbki przewyższają go. Przy większej liczbie próbek 1-bitowe p-DNN zbliżają się do dokładności sieci deterministycznych o precyzji 3 bitów. W generowaniu obrazów prosta zamiana aktywacji na p-bity daje szumne obrazy, ale ponowne trenowanie z uwzględnieniem rzeczywistych stochastycznych elementów i staranna obsługa warstwy wyjściowej pozwalają uzyskać twarze o jakości niemal równej bazie 32-bitowej, mierzonej standardowym metrykiem odległości.
Koszty energetyczne i rzeczywisty sprzęt
Autorzy wykraczają poza symulacje i analizują zużycie energii na rzeczywistym sprzęcie. Wykorzystując dane z układu 65 nm zaprojektowanego do obwodów probabilistycznych oraz dodatkowe symulacje obwodów, pokazują, że współczesne duże obciążenia AI są zdominowane przez energię pamięci, a nie operacje arytmetyczne. Ponieważ p-DNN znacząco upraszczają główny krok obliczeniowy — z pełnych mnożeń i akumulacji do prostych dodawań z aktywacjami 1-bitowymi — dodatkowe obliczenia potrzebne do pobrania kilku próbek prawie nie zmieniają całkowitego zużycia energii, gdy wagi przechowywane są w energochłonnej pamięci zewnętrznej. Potwierdzają te prognozy na implementacji FPGA sieci generującej obrazy: wersja probabilistyczna zmniejsza całkowitą energię na jedno wnioskowanie około 2,5 razy w porównaniu ze standardowym projektem, przy uzyskaniu porównywalnych obrazów cyfr. Narzut związany z generowaniem liczb losowych i porównaniami jest znikomy w porównaniu z kosztem pamięci i podstawowych operacji arytmetycznych.
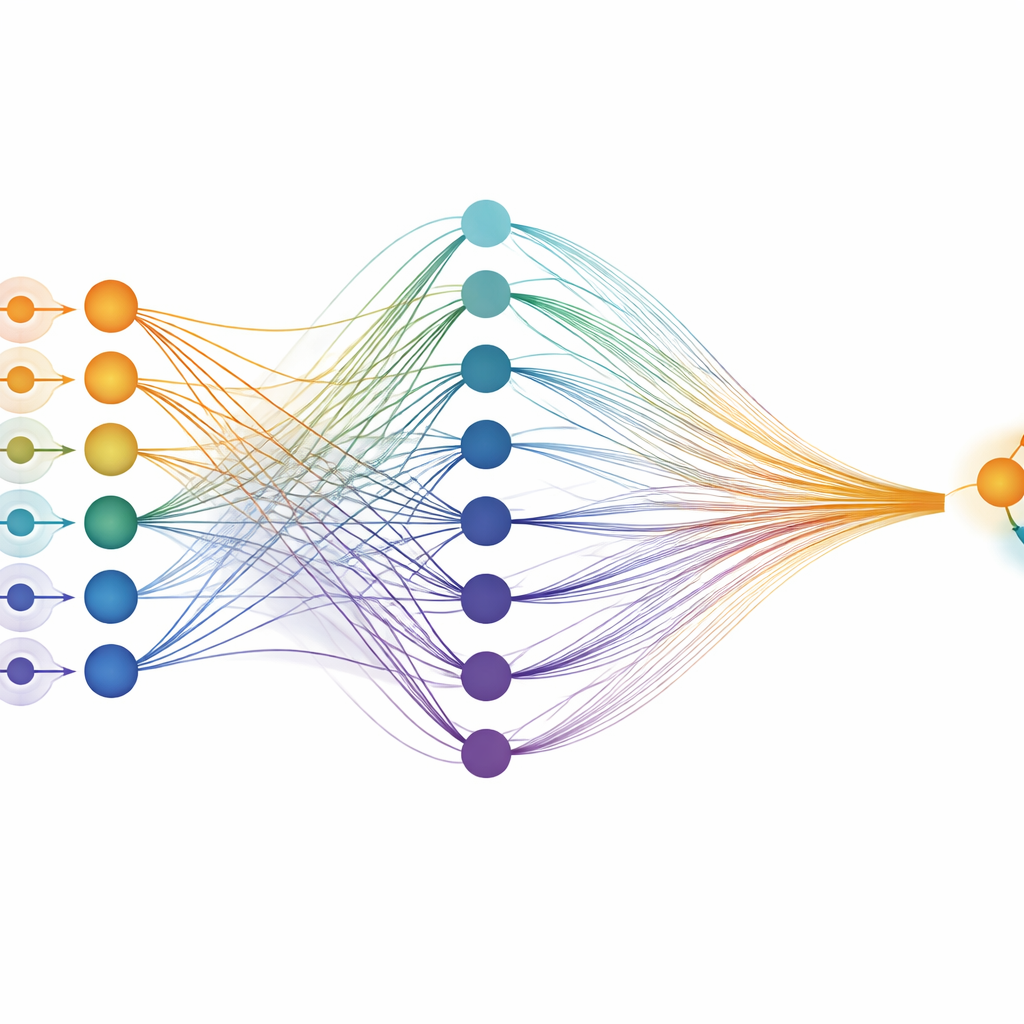
Dlaczego regulowane próbkowanie ma znaczenie
Wyraźną zaletą sieci probabilistycznych jest to, że dokładność można dopasować podczas działania przez zmianę liczby próbek. Jedno 1-bitowe silnik p-DNN może zachowywać się jak model skwantowany do 1, 2 lub 3 bitów w zależności od liczby pobranych próbek, bez konieczności przeprojektowywania sprzętu. Ta elastyczność jest szczególnie atrakcyjna dla dużych modeli językowych, gdzie precyzja wag jest już redukowana do kilku bitów, ale precyzja aktywacji trudniej jest obniżyć bez pogorszenia jakości. Ramy przedstawione w artykule pokazują, jak oszacować dla dowolnego takiego modelu, czy pobranie dodatkowych próbek opłaca się energetycznie w porównaniu ze zwiększeniem szerokości bitowej.
Nowa ścieżka do wydajnej, elastycznej SI
Mówiąc prosto, artykuł pokazuje, że „hałaśliwe” jednostki neuronowe można wykorzystać zamiast ich unikać. Traktując każdy przebieg w przód jako tani, przybliżony strzał i uśredniając niewielką liczbę takich strzałów, sieci mogą osiągać wydajność zbliżoną do pełnej precyzji przy znacznie prostszych obliczeniach i umiarkowanym narzucie energetycznym. Ponieważ to pamięć dominuje rachunek energetyczny, koszt dodatkowego próbkowania jest niewielki, zwłaszcza gdy wagi odczytuje się raz i wykorzystuje wielokrotnie. To sugeruje obiecującą drogę do sprzętu AI, który nie tylko jest bardziej energooszczędny, ale też adaptowalny w locie — zwiększając lub zmniejszając liczbę próbek, by wymienić dokładność na żywotność baterii lub szybkość działania w zależności od potrzeb.
Cytowanie: Ghantasala, L.A., Li, MC., Jaiswal, R. et al. Improving deep neural network performance through sampling. npj Unconv. Comput. 3, 18 (2026). https://doi.org/10.1038/s44335-026-00063-7
Słowa kluczowe: probabilistyczne sieci neuronowe, energooszczędna sztuczna inteligencja, wnioskowanie oparte na próbkowaniu, obliczenia niskiej precyzji, sprzęt do uczenia głębokiego