Clear Sky Science · zh
通过教学经验改进机器学习开发 pKa 预测器(pKaLearn)
为何要教机器有关酸的知识
从药物到电池的日常产品都依赖分子放弃或接受质子的难易程度,这一特性由熟悉的 pH 标度及其分子对应量 pKa 所体现。在实验室测定 pKa 既耗时又费力,即便是先进的计算方法也可能速度慢或不够可靠。本研究提出了一个简单但意义重大的问题:如果我们像教学生那样教计算机基础化学,然后让它们更快、更准确地预测 pKa,会怎样?
从课堂规则到计算机规则
在化学课堂上,学生按步骤学习。先是原子和简单趋势如电负性,然后是共振、环张力以及近邻基团如何拉或推电子等概念。只有在更后面才处理复杂预测,例如在复杂分子中哪个氢最酸性。作者指出,大多数机器学习模型跳过了这种渐进式学习。它们通常只输入原始结构或抽象指纹,让模型自行发现模式,这可能导致对实例的记忆而非理解根本原因。在此工作中,团队有意将人类教师使用的相同基本思想编码进特征并输入算法。
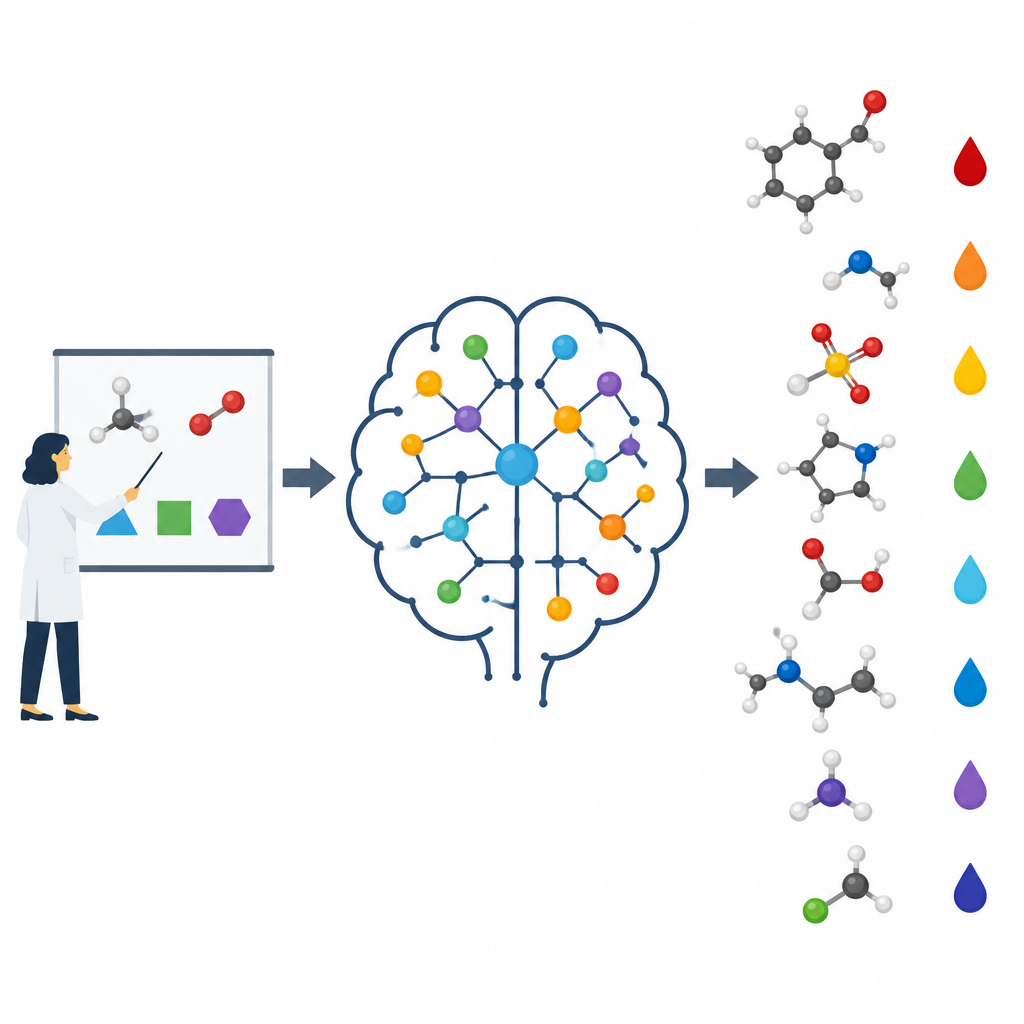
构建像化学家一样思考的模型
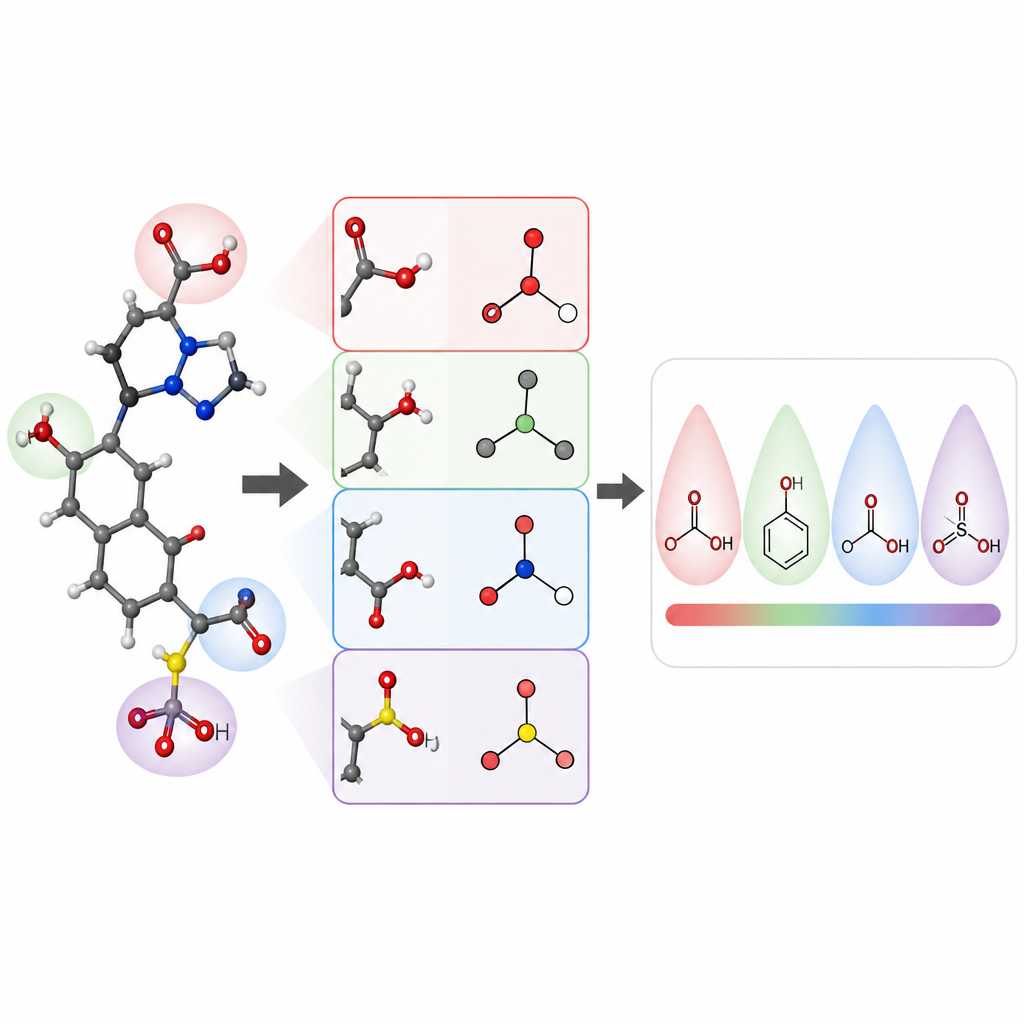
研究人员集中预测小有机分子的 pKa 值,这是药物设计和许多化学领域的核心属性。他们使用图神经网络构建了名为 pKaLearn 的模型,该网络将分子视为由键连接的原子集合。与仅依赖通用结构编码不同,他们加入了直接对应教科书原理的特征:键的极性、带电基团与可电离位点之间相隔的键数、键是否属于环,以及共轭与共振如何分散电荷。他们还衡量了诸如诱导效应等微妙影响沿原子链传播的距离,并将网络设计为使每个可电离位点能够“感知”约七键范围内的环境。
教学、测试与避免简单记忆
为了检验这种教学方式是否真正有助于计算机学习,作者精心收集并清理了约 13,000 个 pKa 值的数据集。他们没有采用通常的随机拆分(这会使训练集与测试集的分子非常相似),而是对分子进行聚类,从而使测试集中包含新的化学家族。这个更难的考验能够揭示模型是学会了一般规则还是仅仅记住了实例。在这些条件下,pKaLearn 的典型误差低于 0.7 pKa 单位,优于基于指纹的传统统计模型,也强于若干现有的机器学习和量子化学预测器。当他们尝试标准捷径,例如仅依赖元素类型或常见软件对共轭键的定义时,性能下降,突显出化学上有意义且定义良好的特征的重要性。
与其他智能预测器的比较
团队将 pKaLearn 与知名 pKa 工具在广泛使用的基准集上进行了比较,基准集包括制药公司提供的分子以及开发过程中答案保密的盲预测挑战。在这些测试中,他们的模型持续匹配或优于结合昂贵量子计算与机器学习的方法,以及其他基于图的神经网络。重要的是,他们还检查了预测出错的情况,常见原因包括遗漏可电离位点、能够在分子内重排质子的难处理互变异构体,或实验数据本身存在歧义。总体而言,仅有少数化合物出现较大误差,且在许多不同的官能团中性能保持稳定。
对化学家及更广领域的意义
这项研究表明,像教学生一样教机器会带来益处。通过将简单但有力的化学概念直接嵌入学习算法,作者创建了一个既准确又比黑箱模型更具可解释性的 pKa 预测器。对实际用户而言,这意味着在更广泛的分子范围内能更快速、更可靠地估计酸碱性,从而为药物设计和其它分子发现工作提供指导。更广泛地说,这项工作为未来工具指明了一条道路:与其让人工智能从零开始重新发现基础科学,不如内建人类专业知识,让模型专注于细化和扩展这些知识。
引用: Genzling, J., Luo, Z., Weiser, B. et al. Development of a pKa predictor (pKaLearn) by leveraging teaching experience to improve machine learning. Commun Chem 9, 181 (2026). https://doi.org/10.1038/s42004-026-01983-y
关键词: pKa 预测, 机器学习, 图神经网络, 计算化学, 药物设计