Clear Sky Science · pt
Desenvolvimento de um preditor de pKa (pKaLearn) aproveitando experiência docente para melhorar aprendizado de máquina
Por que ensinar máquinas sobre ácidos importa
Produtos do dia a dia, de medicamentos a baterias, dependem de quão facilmente moléculas doam ou aceitam prótons, uma propriedade capturada pela conhecida escala de pH e sua versão molecular, o pKa. Medir pKa em laboratório demanda tempo e esforço, e mesmo métodos computacionais avançados podem ser lentos ou pouco confiáveis. Este estudo coloca uma pergunta simples com grandes implicações: e se ensinássemos computadores a química básica do modo como ensinamos estudantes, e então lhes pedíssemos para prever valores de pKa de forma mais rápida e precisa?
Das regras de sala de aula para regras de computador
Na aula de química, os alunos aprendem passo a passo. Primeiro vêm os átomos e tendências simples como eletronegatividade, depois ideias como ressonância, tensão de anel e como grupos próximos puxam ou empurram elétrons. Só mais tarde enfrentam previsões difíceis, como qual hidrogênio em uma molécula complexa será o mais ácido. Os autores argumentam que a maioria dos modelos de aprendizado de máquina pula essa progressão. Frequentemente eles recebem apenas estruturas brutas ou impressões digitais abstratas e precisam descobrir padrões sozinhos, o que pode levar à memorização de exemplos em vez de entender as causas subjacentes. Aqui, a equipe codifica deliberadamente as mesmas ideias básicas que professores humanos usam e as alimenta em seus algoritmos.
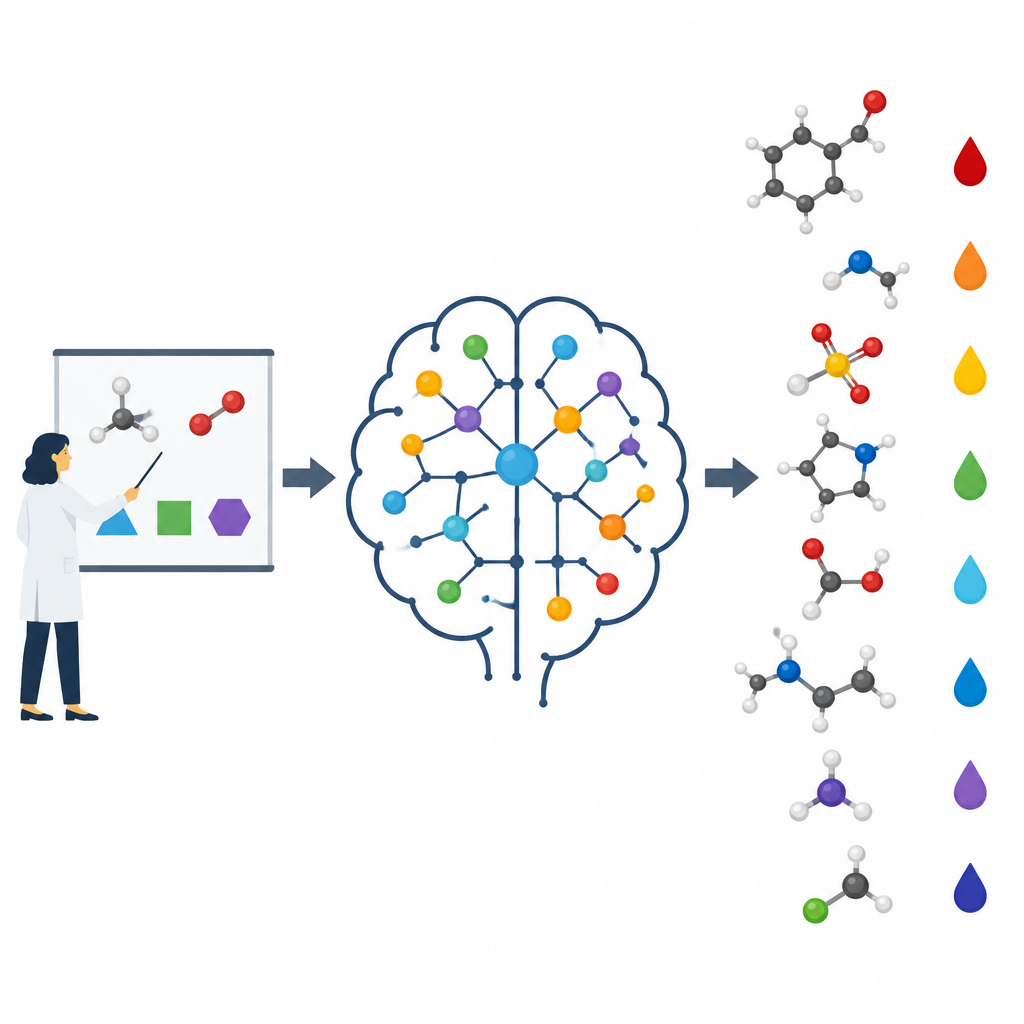
Construindo um modelo que pensa como um químico
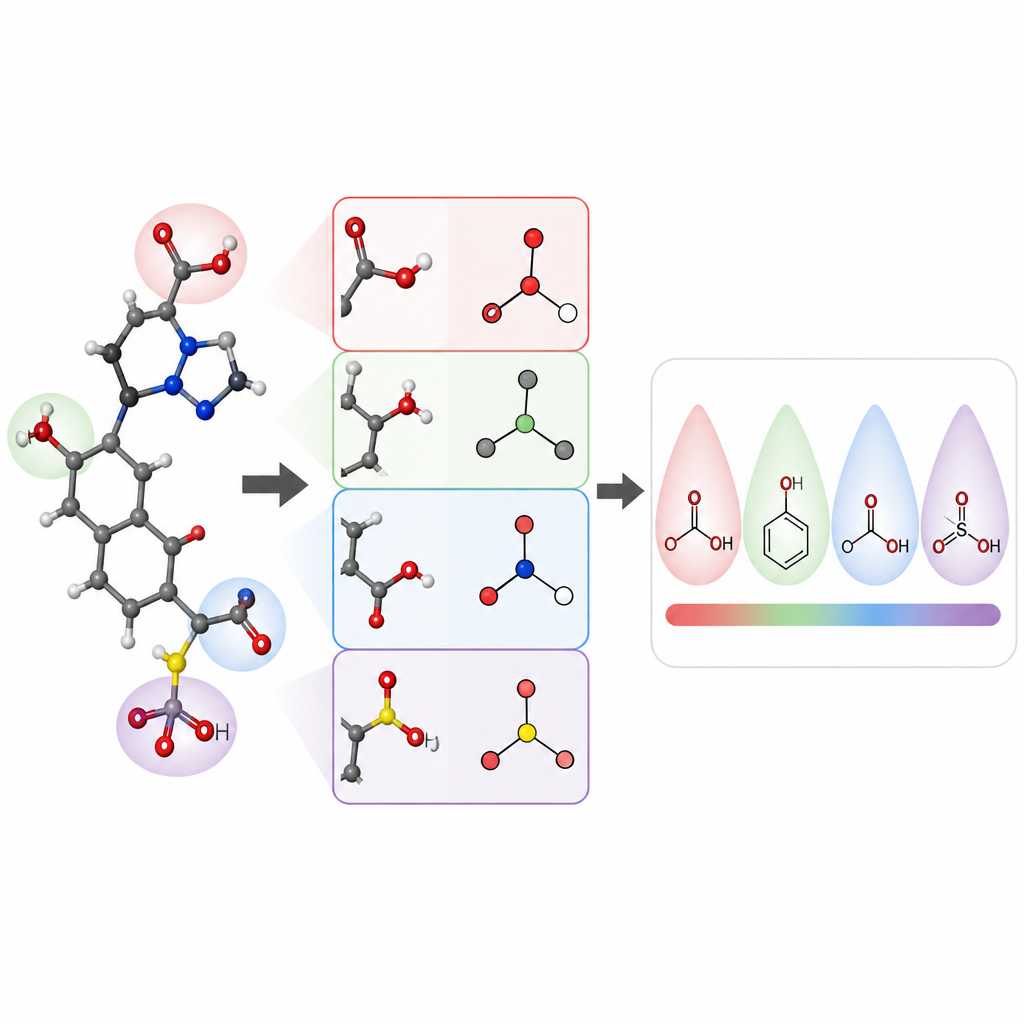
Os pesquisadores concentraram-se em prever valores de pKa de pequenas moléculas orgânicas, uma propriedade central para o design de fármacos e muitas áreas da química. Eles construíram um modelo chamado pKaLearn usando uma rede neural baseada em grafos, que trata a molécula como um conjunto de átomos conectados por ligações. Em vez de depender apenas de códigos estruturais genéricos, adicionaram características ligadas diretamente a princípios de livro-texto: quão polar é uma ligação, quantas ligações separam um grupo carregado de um sítio ionizável, se uma ligação faz parte de um anel e como conjugação e ressonância podem espalhar carga. Também mediram até que distância efeitos sutis, como o puxão indutivo, percorrem ao longo de uma cadeia de átomos e projetaram a rede para que cada sítio ionizável “sinta” seu entorno até cerca de sete ligações de distância.
Ensinando, testando e evitando memorização simples
Para verificar se seu estilo de ensino realmente ajudou o computador a aprender, os autores montaram e limparam cuidadosamente um conjunto de dados de cerca de 13.000 valores de pKa. Em vez da divisão aleatória habitual, que pode tornar as moléculas de treinamento e teste muito semelhantes, eles agruparam as moléculas para que o conjunto de teste contivesse novas famílias químicas. Este exame mais difícil revela se o modelo aprendeu regras gerais ou simplesmente memorizou exemplos. Nessas condições, o pKaLearn alcançou erros típicos abaixo de 0,7 unidades de pKa, superior a modelos estatísticos tradicionais baseados em impressões digitais e melhor do que vários preditores existentes baseados em aprendizado de máquina e química quântica. Quando tentaram atalhos padrão, como confiar apenas em tipos de elementos ou em uma definição comum de software para ligações conjugadas, o desempenho caiu, ressaltando o valor de características quimicamente significativas e bem definidas.
Comparando com outros preditores inteligentes
A equipe comparou o pKaLearn com ferramentas de pKa bem conhecidas em conjuntos de referência amplamente usados, incluindo moléculas de empresas farmacêuticas e desafios de predição às cegas onde as respostas verdadeiras foram ocultas durante o desenvolvimento. Nesses testes, seu modelo consistentemente igualou ou superou métodos que combinam cálculos quânticos pesados com aprendizado de máquina, assim como outras redes neurais baseadas em grafos. Importante, eles também examinaram casos em que as previsões deram errado, frequentemente rastreando-os a sítios ionizáveis ausentes, tautômeros complicados que podem mover prótons dentro de uma molécula, ou dados experimentais que eram eles mesmos ambíguos. No geral, apenas uma pequena fração dos compostos mostrou erros grandes, e o desempenho manteve-se estável através de muitos grupos funcionais diferentes.
O que isso significa para químicos e além
O estudo demonstra que máquinas podem se beneficiar de serem ensinadas como estudantes. Ao incorporar ideias químicas simples, porém poderosas, diretamente em um algoritmo de aprendizado, os autores criaram um preditor de pKa que é ao mesmo tempo preciso e mais interpretável do que modelos caixa-preta. Para usuários práticos, isso significa estimativas de acidez e basicidade mais rápidas e confiáveis em uma ampla gama de moléculas, auxiliando o design de fármacos e outros esforços de descoberta molecular. Mais amplamente, o trabalho sugere um caminho para ferramentas futuras: em vez de pedir à inteligência artificial que redescubra a ciência fundamental do zero, podemos incorporar a expertise humana e deixar que os modelos se concentrem em refinar e ampliar esse conhecimento.
Citação: Genzling, J., Luo, Z., Weiser, B. et al. Development of a pKa predictor (pKaLearn) by leveraging teaching experience to improve machine learning. Commun Chem 9, 181 (2026). https://doi.org/10.1038/s42004-026-01983-y
Palavras-chave: predição de pKa, aprendizado de máquina, rede neural baseada em grafos, química computacional, design de fármacos