Clear Sky Science · nl
Ontwikkeling van een pKa-voorspeller (pKaLearn) door leservaring te benutten om machine learning te verbeteren
Waarom het belangrijk is machines over zuren te leren
Alledaagse producten, van medicijnen tot batterijen, berusten op hoe gemakkelijk moleculen protonen afstaan of opnemen, een eigenschap vastgelegd door de bekende pH-schaal en zijn moleculaire evenknie, pKa. Het meten van pKa in het lab kost tijd en moeite, en zelfs geavanceerde rekenmethoden kunnen traag of onbetrouwbaar zijn. Deze studie stelt een eenvoudige vraag met grote gevolgen: wat als we computers basischemie zouden leren op de manier waarop we studenten lesgeven, en hen vervolgens vroegen pKa-waarden sneller en nauwkeuriger te voorspellen?
Van klasregels naar computeregelgeving
In de scheikundeles leren studenten stap voor stap. Eerst komen atomen en eenvoudige trends zoals elektronegativiteit, vervolgens concepten zoals resonantie, ringspanning en hoe nabije groepen elektronen aantrekken of afstoten. Pas later behandelen ze lastige voorspellingen, zoals welke waterstof in een complex molecuul het meest zuur zal zijn. De auteurs betogen dat de meeste machine learning-modellen deze opbouw overslaan. Ze krijgen vaak ruwe structuren of abstracte vingerafdrukken als input en moeten zelf patronen ontdekken, wat ertoe kan leiden dat ze voorbeelden uit het hoofd leren in plaats van de onderliggende oorzaken te begrijpen. Hier codeert het team opzettelijk dezelfde basisideeën die menselijke docenten gebruiken en voeden die in hun algoritmen.
Een model bouwen dat denkt als een chemicus
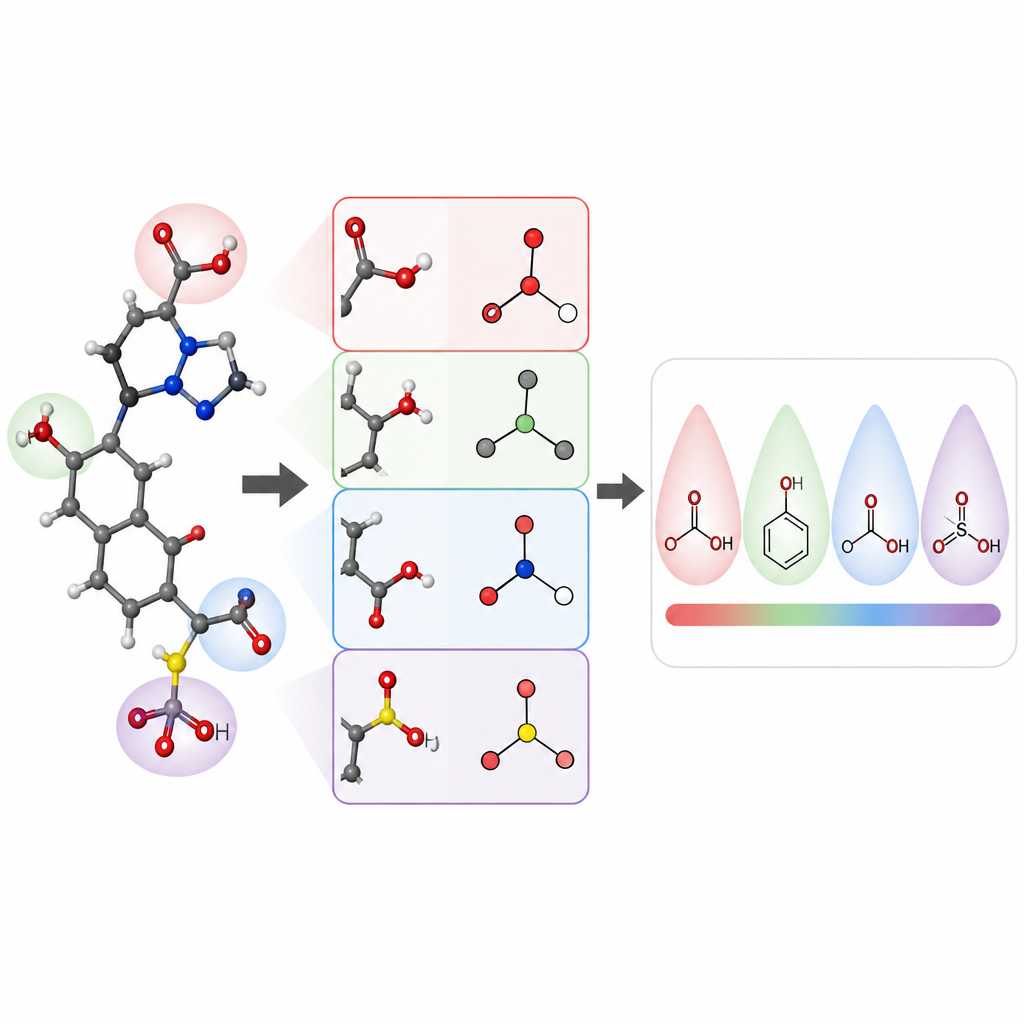
De onderzoekers richtten zich op het voorspellen van pKa-waarden van kleine organische moleculen, een kernEigenschap voor geneesmiddelontwerp en veel gebieden in de chemie. Ze bouwden een model genaamd pKaLearn met behulp van een graaf-neuraal netwerk, dat een molecuul behandelt als een verzameling atomen verbonden door bindingen. In plaats van alleen op generieke structurele codes te vertrouwen, voegden ze kenmerken toe die rechtstreeks verband houden met tekstboekprincipes: hoe polair een binding is, hoeveel bindingen een geladen groep scheiden van een ioniseerbare site, of een binding deel uitmaakt van een ring, en hoe conjugatie en resonantie lading kunnen verspreiden. Ze maten ook hoe ver subtiele effecten zoals inductieve aantrekking door een keten van atomen reizen en ontwierpen het netwerk zodat elke ioniseerbare site zijn omgeving voelt tot ongeveer zeven bindingen afstand.
Lesgeven, testen en eenvoudige memorisatie vermijden
Om te controleren of hun lesmethode de computer echt hielp leren, stelden de auteurs zorgvuldig een dataset van ongeveer 13.000 pKa-waarden samen en schonen die. In plaats van de gebruikelijke willekeurige verdeling, die trainings- en testmoleculen erg op elkaar kan laten lijken, clusterden ze moleculen zodat de testset nieuwe chemische families bevatte. Dit zwaardere examen onthult of het model algemene regels heeft geleerd of simpelweg voorbeelden heeft onthouden. Onder deze omstandigheden behaalde pKaLearn typische fouten onder 0,7 pKa-eenheden, beter dan traditionele statistische modellen gebaseerd op vingerafdrukken en sterker dan verschillende bestaande machine learning- en quantumchemie-voorspellers. Toen ze standaardverkortingen probeerden, zoals alleen vertrouwen op elementtypen of een gangbare softwaredefinitie van geconjugeerde bindingen, daalde de prestatie, wat de waarde onderstreept van chemisch betekenisvolle, goed gedefinieerde kenmerken.
Vergelijken met andere slimme voorspellers
Het team vergeleek pKaLearn met bekende pKa-tools op veelgebruikte benchmarksets, inclusief moleculen van farmaceutische bedrijven en blinde voorspellingsuitdagingen waarbij de werkelijke antwoorden tijdens ontwikkeling verborgen waren. In deze tests kwam hun model consequent overeen met of presteerde beter dan methoden die zware quantumberekeningen met machine learning combineren, evenals andere graafgebaseerde neurale netwerken. Belangrijk is dat ze ook gevallen onderzochten waarin voorspellingen fout gingen, vaak terug te voeren op ontbrekende ioniseerbare sites, lastige tautomeren die protonen binnen een molecuul kunnen verschuiven, of experimentele data die zelf ambigu waren. Over het geheel genomen vertoonde slechts een klein deel van de verbindingen grote fouten en bleef de prestatie stabiel over veel verschillende functionele groepen.
Wat dit betekent voor chemici en daarbuiten
De studie laat zien dat machines kunnen profiteren van lesmethoden die lijken op hoe we studenten onderwijzen. Door eenvoudige maar krachtige chemische ideeën rechtstreeks in een leeralgoritme in te bouwen, creëerden de auteurs een pKa-voorspeller die zowel nauwkeurig als beter interpreteerbaar is dan black-box-modellen. Voor praktische gebruikers betekent dit snellere, betrouwbaardere schattingen van zuurtegraad en basiteit voor een breed scala aan moleculen, wat helpt bij het sturen van geneesmiddelontwerp en andere inspanningen voor moleculaire ontdekking. Algemeen suggereert het werk een pad voor toekomstige tools: in plaats van kunstmatige intelligentie fundamentele wetenschap van nul te laten herontdekken, kunnen we menselijke expertise inbouwen en modellen laten focussen op het verfijnen en uitbreiden van die kennis.
Bronvermelding: Genzling, J., Luo, Z., Weiser, B. et al. Development of a pKa predictor (pKaLearn) by leveraging teaching experience to improve machine learning. Commun Chem 9, 181 (2026). https://doi.org/10.1038/s42004-026-01983-y
Trefwoorden: pKa-voorspelling, machine learning, graaf-neuraal netwerk, computationele chemie, geneesmiddelontwerp