Clear Sky Science · zh
具有交叉极线和空间建模的方向因式光场重建
来自多角度的更清晰照片
想象拍完照后还能改变焦点、视角,甚至在照片中稍微移动位置。光场相机能实现这一点:它不仅记录光线落在传感器的位置,还记录光线来的方向。本文提出了一种新方法,可以将少量这样有角度的视图转换为丰富且细节清晰的光场,使这些灵活的照片更清楚、更实用,同时将计算开销控制在合理范围内。
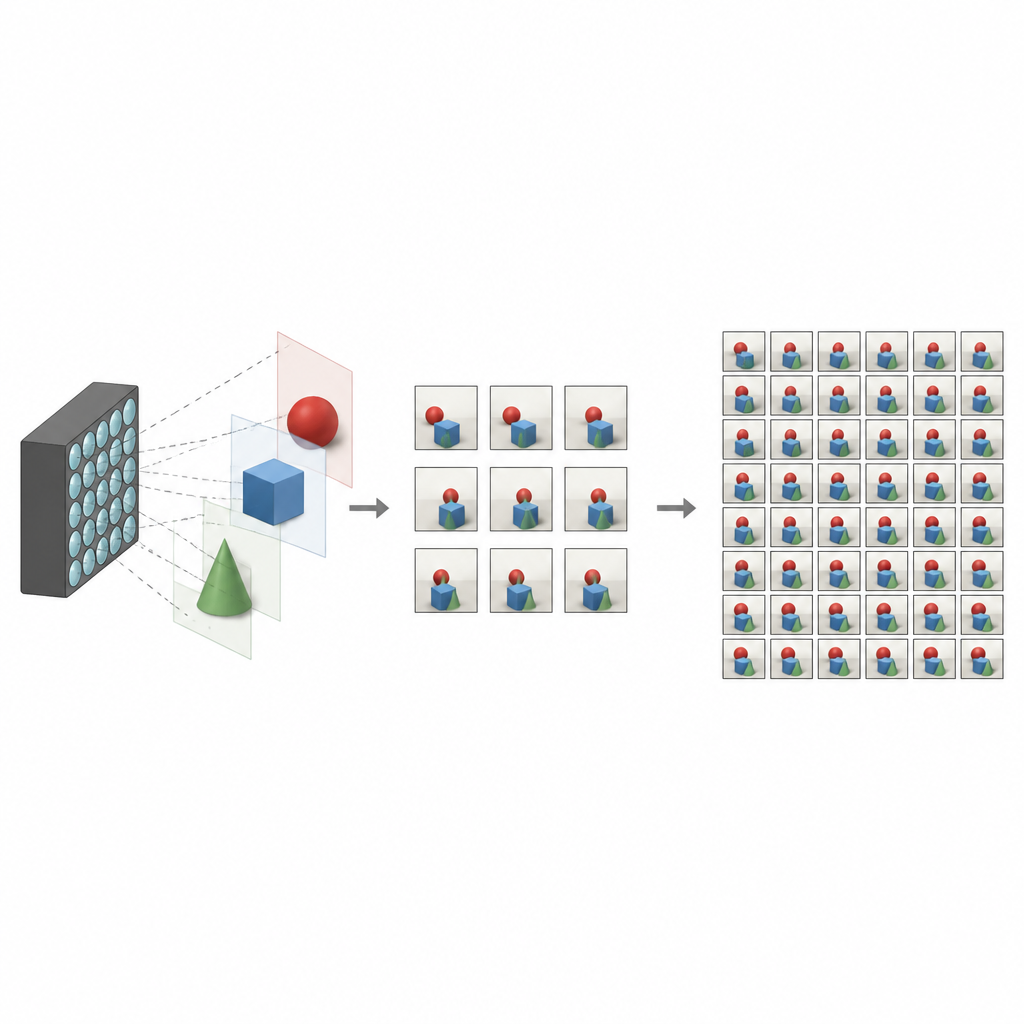
光场照片的特殊之处
传统相机将世界展平为二维图像,将到达每个像素的所有光混合在一起。光场相机则不同:它记录同一场景的许多略有差异的图像,每张图像来自稍有位移的视点。这些视图共同编码了深度和视差,即你移动头部时观察到的微小位移。借助这些信息,软件可以重新对焦场景、移除不需要的物体,或创建沉浸式虚拟现实体验。但问题是,捕获致密的视图网格通常需要复杂的硬件或较长的拍摄时间,这限制了该技术的普及。
填补缺失视图的挑战
为了让光场相机更实用,研究人员希望只用少数实际拍摄的视图重建完整的致密视图集。早期方法通常依赖估计精细的深度图,然后利用这些深度进行图像扭曲和融合以生成新视点。虽然有效,但基于深度的方法对错误敏感且可能较慢。其他技术则跳过深度估计,尝试直接学习相邻视图之间的关系,但它们可能遗漏远距离的相关性,或在处理边缘、反射以及前后遮挡等复杂区域时遇到困难。

读取视图结构的新方法
作者提出了 DFCNet,一种针对光场几何结构设计的深度学习系统。他们没有把每个小图像单独处理,而是将数据重排为宏像素布局,把来自不同视图但同一像素位置的像素聚合在一起。这种布局使网络可以检查特征在水平和垂直视点之间的移动方式,这与场景深度密切相关。特殊的构建模块将处理分成明确的通路:一些模块关注单条视点线上的变化,而另一些则捕捉视点线之间的相互作用,例如物体重叠或揭示被遮挡区域的情况。另一路径负责在每个视图内部锐化细节,通道加权步骤教会网络哪些特征更重要。
从粗略猜测到精确的多视图场景
DFCNet 采用两阶段策略来生成缺失视图。首先,使用标准插值方法生成完整光场的粗略估计,这使学习任务更稳定。然后利用学习到的特征和一种巧妙的数据重排方式对该估计进行精炼,该方式可以处理简单或更不寻常的放大因子。这种设计使模型既能用于插值(在已捕获视图之间创建新视图),也能用于外推(合成捕获网格外部的视图)。在多个合成和真实世界数据集上,该方法在图像质量指标上持续优于领先替代方法,并且更好地保留了微妙纹理和平滑的几何线条,这些都反映了正确的深度关系。
这些结果为何重要
对普通读者来说,关键是在于作者找到了一种更智能的方式,通过让神经网络与光在场景中传播的方式对齐,从有限数据重建出丰富的多视图图像。他们的系统 DFCNet 能将稀疏视图集转化为保留细微图案、边缘和深度线索的详细光场,比以往方法更忠实,同时效率也足够实用。这一改进有助于将光场成像推进到日常应用中——从更清晰的可重新对焦照片到更真实的虚拟与增强现实体验,即使在硬件或拍摄时间受限的情况下亦然。
引用: Salem, A., Elkady, E., Ibrahem, H. et al. Directionally factorized light field reconstruction with cross-epipolar and spatial modeling. Sci Rep 16, 15755 (2026). https://doi.org/10.1038/s41598-026-53241-9
关键词: 光场成像, 视图合成, 角度超分辨率, 深度神经网络, 三维场景重建