Clear Sky Science · en
Directionally factorized light field reconstruction with cross-epipolar and spatial modeling
Sharper photos from many angles
Imagine being able to change the focus, viewpoint, or even slightly move around inside a photo after you have taken it. That is the promise of light field cameras, which capture not only where light hits the sensor but also the directions it comes from. This paper introduces a new way to turn a small set of such angled views into a rich, detailed light field, making these flexible photos clearer and more useful while keeping computing costs under control.
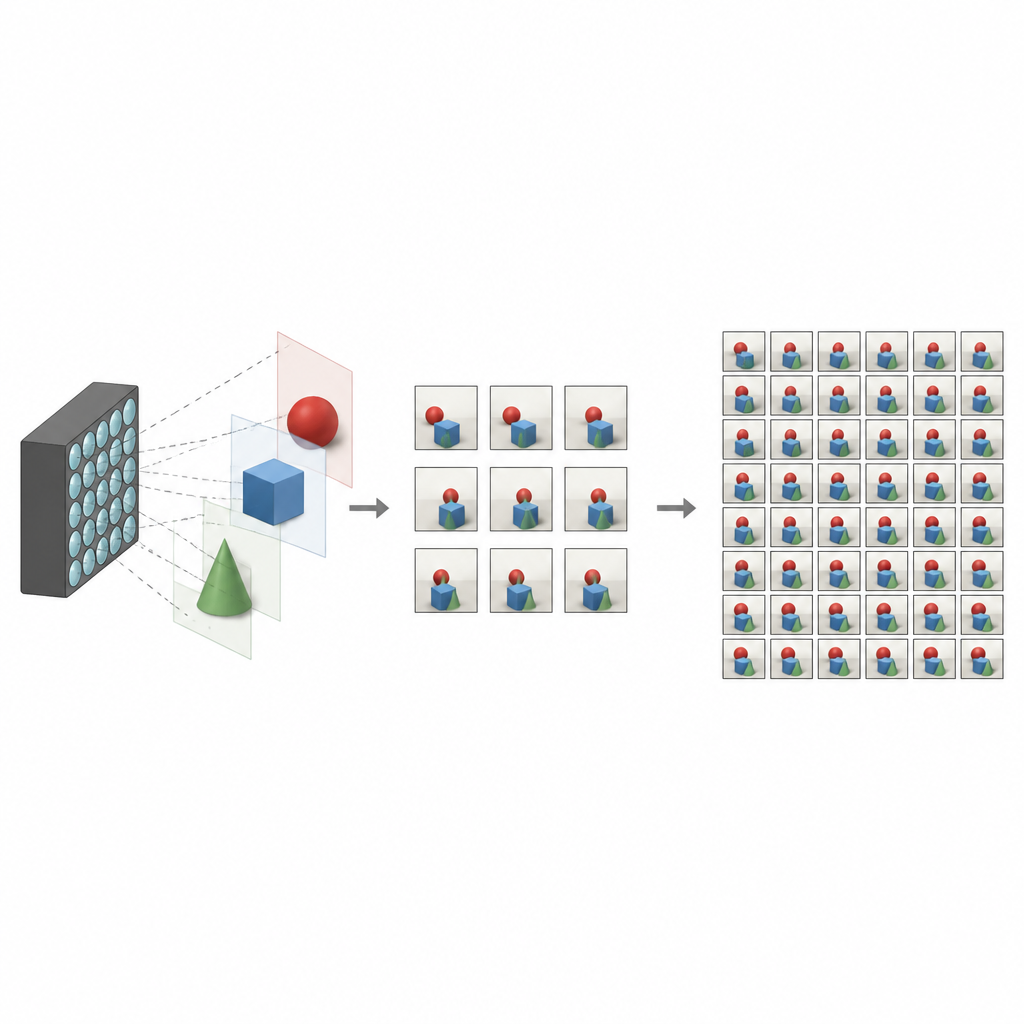
What makes light field photos special
Traditional cameras flatten the world into a single two dimensional image, blending together all the light that arrives at each pixel. Light field cameras work differently. They record many slightly different images of the same scene, each from a slightly shifted viewpoint. Together, these views encode depth and parallax, the tiny shifts you see when you move your head. With them, software can refocus a scene, remove unwanted objects, or create immersive virtual reality experiences. The catch is that capturing a dense grid of views usually demands complex hardware or long capture times, which limits how widely the technology can be used.
The challenge of filling in missing views
To make light field cameras practical, researchers want to reconstruct a full, dense set of views from only a few that are actually captured. Earlier methods often relied on estimating detailed depth maps, then using them to warp and blend images into new viewpoints. While powerful, these depth based approaches are sensitive to errors and can be slow. Other techniques skip depth and try to learn how neighboring views relate directly, but they may miss long range relationships or struggle with tricky regions like edges, reflections, and areas where one object blocks another.

A new way to read structure in the views
The authors propose DFCNet, a deep learning system tailored to the geometry of light fields. Instead of treating each small image separately, they rearrange the data into a macro pixel layout that groups together pixels from the same position across different views. This layout lets the network examine how features move across viewpoints in horizontal and vertical directions, which is closely tied to scene depth. Special building blocks split the processing into clear pathways: some focus on changes along a single line of viewpoints, while others capture interactions between lines, such as where objects overlap or reveal hidden areas. A separate pathway sharpens details inside each view, and a channel weighting step teaches the network which features matter most.
From rough guess to precise multi view scene
DFCNet uses a two stage strategy to create missing views. First, it generates a coarse guess of the full light field using a standard interpolation method, which makes the learning task more stable. Then, it refines this guess using its learned features and a clever rearranging of data that can handle both simple and more unusual upscaling factors. This design allows the model to work for both interpolation, where new views are created between captured ones, and extrapolation, where views just outside the captured grid are synthesized. Across several synthetic and real world datasets, the method consistently scores higher than leading alternatives on image quality measures, and it better preserves subtle textures and smooth geometric lines that reflect correct depth relationships.
Why these results matter
For a general reader, the key message is that the authors have found a smarter way to reconstruct rich, multi view images from limited data by aligning the neural network with how light actually travels through a scene. Their system, DFCNet, turns a sparse set of views into a detailed light field that keeps fine patterns, edges, and depth cues more faithfully than previous methods, while still being efficient enough for practical use. This improvement helps push light field imaging closer to everyday applications, from sharper refocused photos to more convincing virtual and augmented reality experiences, even when hardware or capture time are restricted.
Citation: Salem, A., Elkady, E., Ibrahem, H. et al. Directionally factorized light field reconstruction with cross-epipolar and spatial modeling. Sci Rep 16, 15755 (2026). https://doi.org/10.1038/s41598-026-53241-9
Keywords: light field imaging, view synthesis, angular super resolution, deep neural network, 3D scene reconstruction