Clear Sky Science · es
Reconstrucción de campos de luz factorizada direccionalmente con modelado cruz-epipolar y espacial
Fotos más nítidas desde muchos ángulos
Imagina poder cambiar el enfoque, el punto de vista o incluso moverte ligeramente dentro de una foto después de haberla tomado. Esa es la promesa de las cámaras de campo de luz, que capturan no solo dónde la luz incide en el sensor sino también las direcciones desde las que llega. Este artículo presenta una nueva forma de convertir un pequeño conjunto de vistas inclinadas en un campo de luz rico y detallado, haciendo que estas fotos flexibles sean más claras y útiles sin disparar los costes computacionales.
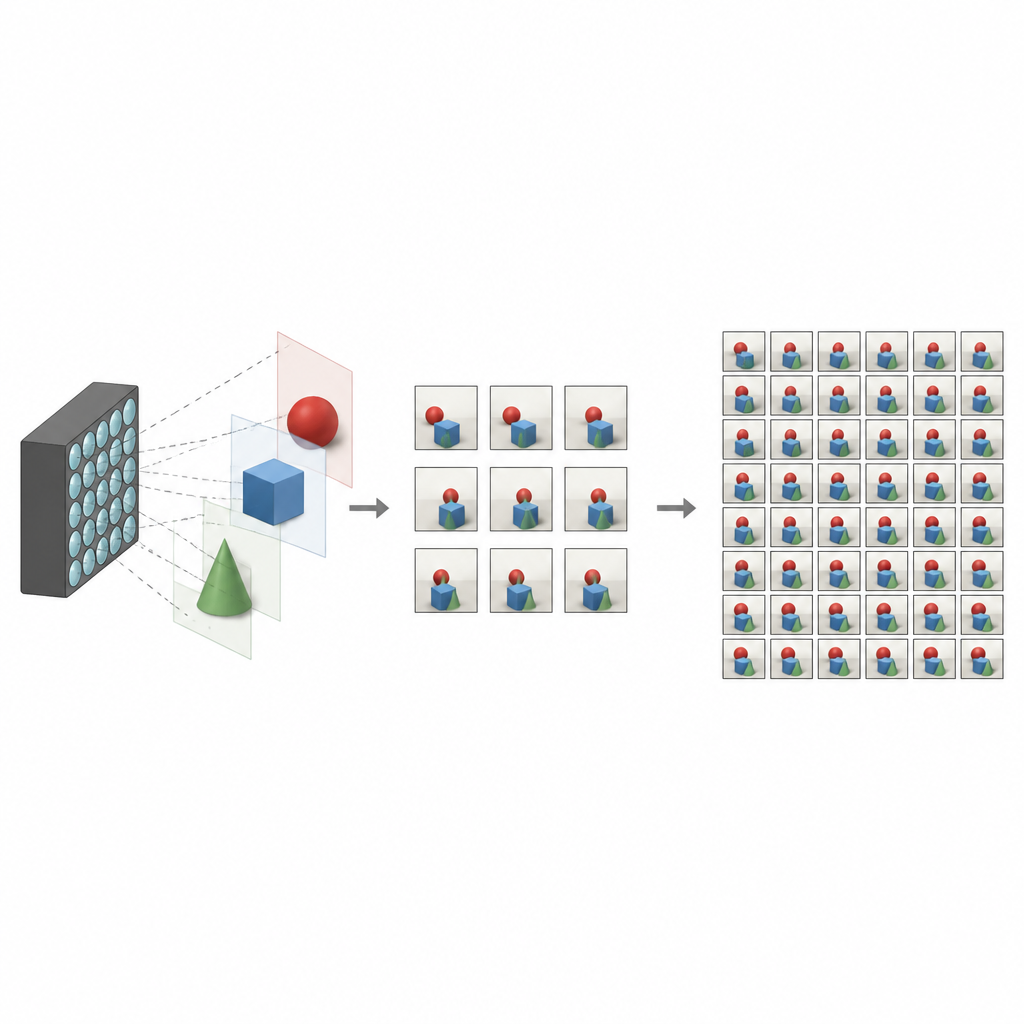
Qué hace especiales a las fotos de campo de luz
Las cámaras tradicionales aplastan el mundo en una sola imagen bidimensional, mezclando toda la luz que llega a cada píxel. Las cámaras de campo de luz funcionan de modo diferente. Registran muchas imágenes ligeramente distintas de la misma escena, cada una desde un punto de vista desplazado. En conjunto, estas vistas codifican la profundidad y el paralaje, los pequeños desplazamientos que se perciben cuando movemos la cabeza. Con ellas, el software puede reenfocar una escena, eliminar objetos no deseados o crear experiencias de realidad virtual envolventes. El problema es que capturar una cuadrícula densa de vistas suele requerir hardware complejo o tiempos de captura largos, lo que limita el uso generalizado de la tecnología.
El reto de rellenar vistas faltantes
Para hacer prácticas las cámaras de campo de luz, los investigadores buscan reconstruir un conjunto completo y denso de vistas a partir de solo unas pocas capturadas. Métodos anteriores a menudo se basaban en estimar mapas de profundidad detallados y luego usarlos para deformar y mezclar imágenes en nuevos puntos de vista. Aunque potentes, estos enfoques basados en profundidad son sensibles a errores y pueden ser lentos. Otras técnicas evitan la profundidad e intentan aprender directamente cómo se relacionan las vistas vecinas, pero pueden perder relaciones a largo alcance o tener dificultades con regiones complicadas como bordes, reflejos y zonas donde un objeto oculta a otro.

Una nueva forma de leer la estructura en las vistas
Los autores proponen DFCNet, un sistema de aprendizaje profundo diseñado según la geometría de los campos de luz. En lugar de tratar cada pequeña imagen por separado, reordenan los datos en una disposición de macropíxeles que agrupa píxeles de la misma posición a través de diferentes vistas. Esta disposición permite a la red examinar cómo se desplazan las características entre puntos de vista en direcciones horizontales y verticales, lo que está estrechamente ligado a la profundidad de la escena. Bloques constructivos especiales dividen el procesamiento en vías claras: algunos se centran en cambios a lo largo de una sola línea de puntos de vista, mientras que otros capturan interacciones entre líneas, como donde los objetos se solapan o revelan áreas ocultas. Una vía separada afina los detalles dentro de cada vista, y un paso de ponderación de canales enseña a la red qué características importan más.
De una estimación aproximada a una escena multivista precisa
DFCNet utiliza una estrategia en dos etapas para crear vistas faltantes. Primero, genera una estimación gruesa del campo de luz completo usando un método de interpolación estándar, lo que estabiliza la tarea de aprendizaje. Después, refina esta estimación usando sus características aprendidas y una inteligente reorganización de datos que puede manejar factores de escalado tanto simples como inusuales. Este diseño permite que el modelo funcione tanto para interpolación, donde se crean vistas nuevas entre las capturadas, como para extrapolación, donde se sintetizan vistas justo fuera de la cuadrícula capturada. En varios conjuntos de datos sintéticos y del mundo real, el método obtiene sistemáticamente puntuaciones superiores a las de las alternativas líderes en medidas de calidad de imagen, y conserva mejor las texturas sutiles y las líneas geométricas suaves que reflejan relaciones de profundidad correctas.
Por qué importan estos resultados
Para un lector general, el mensaje clave es que los autores han encontrado una forma más inteligente de reconstruir imágenes multivista ricas a partir de datos limitados alineando la red neuronal con la manera en que la luz realmente viaja por una escena. Su sistema, DFCNet, convierte un conjunto escaso de vistas en un campo de luz detallado que conserva patrones finos, bordes y pistas de profundidad con más fidelidad que métodos previos, a la vez que resulta lo bastante eficiente para un uso práctico. Esta mejora acerca la imagen de campo de luz a aplicaciones cotidianas, desde fotos reenfocadas más nítidas hasta experiencias de realidad virtual y aumentada más convincentes, incluso cuando el hardware o el tiempo de captura son limitados.
Cita: Salem, A., Elkady, E., Ibrahem, H. et al. Directionally factorized light field reconstruction with cross-epipolar and spatial modeling. Sci Rep 16, 15755 (2026). https://doi.org/10.1038/s41598-026-53241-9
Palabras clave: imagen de campo de luz, síntesis de vistas, superresolución angular, red neuronal profunda, reconstrucción de escenas 3D