Clear Sky Science · it
Ricostruzione di campi di luce fattorizzata in modo direzionale con modellazione cross-epipolare e spaziale
Foto più nitide da molte angolazioni
Immaginate di poter cambiare la messa a fuoco, il punto di vista o perfino muovervi leggermente all’interno di una foto dopo averla scattata. Questa è la promessa delle fotocamere per campi di luce, che catturano non solo dove la luce colpisce il sensore ma anche le direzioni da cui proviene. Questo articolo introduce un nuovo modo per trasformare un piccolo insieme di tali viste angolate in un campo di luce ricco e dettagliato, rendendo queste foto flessibili più chiare e utili mantenendo sotto controllo i costi computazionali.
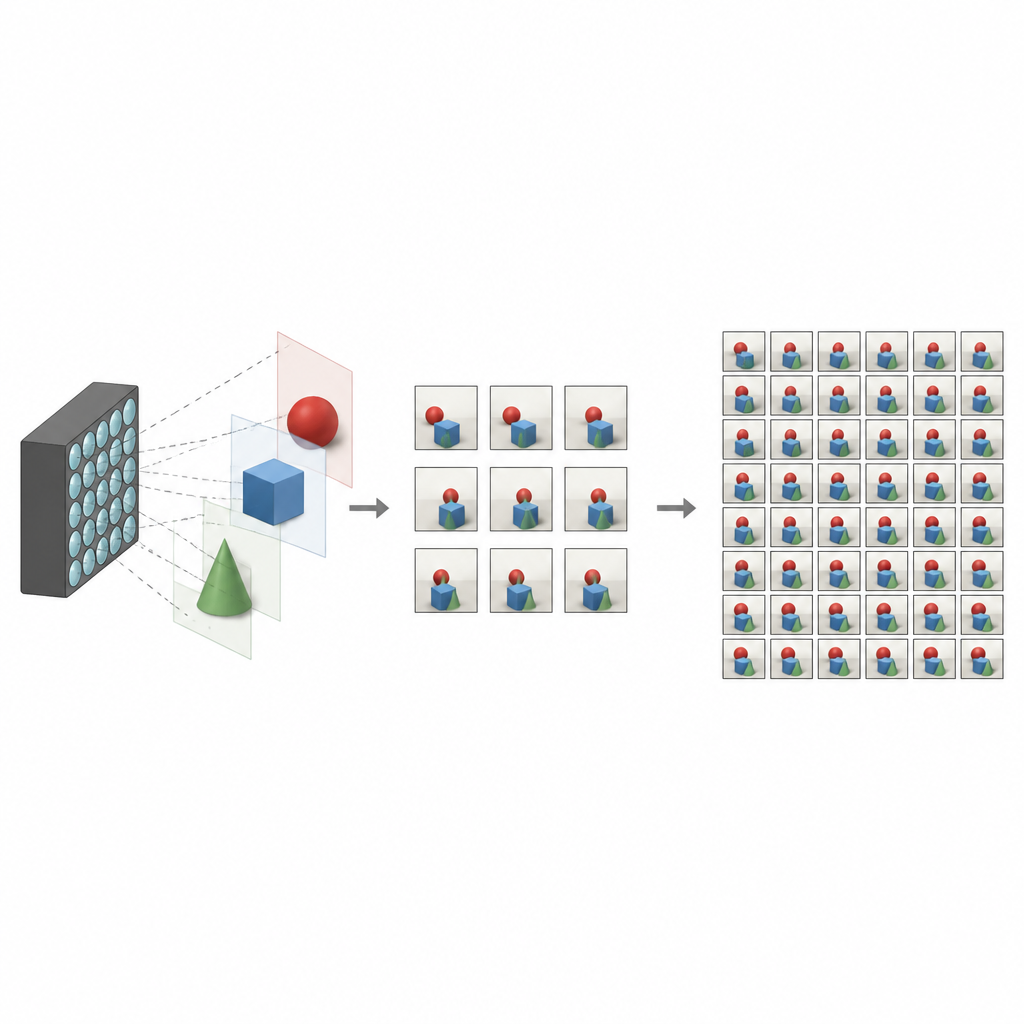
Ciò che rende speciali le foto di campo di luce
Le fotocamere tradizionali appiattiscono il mondo in una singola immagine bidimensionale, fondendo tutta la luce che arriva in ogni pixel. Le fotocamere per campi di luce funzionano diversamente. Registrano molte immagini leggermente diverse della stessa scena, ciascuna da un punto di vista leggermente spostato. Insieme, queste viste codificano la profondità e la parallasse, i piccoli spostamenti che si osservano muovendo la testa. Con queste informazioni, il software può ri-focalizzare una scena, rimuovere oggetti indesiderati o creare esperienze di realtà virtuale immersive. Il problema è che catturare una griglia densa di viste di solito richiede hardware complesso o tempi di acquisizione lunghi, il che limita la diffusione della tecnologia.
La sfida di ricostruire viste mancanti
Per rendere pratiche le fotocamere per campi di luce, i ricercatori cercano di ricostruire un insieme completo e denso di viste a partire da poche effettivamente catturate. Metodi precedenti spesso si basavano sulla stima di mappe di profondità dettagliate, quindi le usavano per deformare e fondere immagini in nuovi punti di vista. Pur essendo potenti, questi approcci basati sulla profondità sono sensibili agli errori e possono essere lenti. Altre tecniche evitano la profondità e cercano di apprendere direttamente come si relazionano le viste vicine, ma possono perdere relazioni a lungo raggio o avere difficoltà con regioni complicate come bordi, riflessi e aree in cui un oggetto ne copre un altro.

Un nuovo modo di leggere la struttura nelle viste
Gli autori propongono DFCNet, un sistema di deep learning progettato sulla geometria dei campi di luce. Invece di trattare ogni piccola immagine separatamente, riorganizzano i dati in un layout di macro-pixel che raggruppa insieme i pixel della stessa posizione attraverso le diverse viste. Questo layout permette alla rete di esaminare come le caratteristiche si muovono fra i punti di vista in direzione orizzontale e verticale, aspetto strettamente legato alla profondità della scena. Blocchi costitutivi speciali dividono l’elaborazione in percorsi chiari: alcuni si concentrano sui cambiamenti lungo una singola linea di viste, mentre altri catturano le interazioni tra linee, per esempio dove gli oggetti si sovrappongono o rivelano aree nascoste. Un percorso separato affina i dettagli all’interno di ciascuna vista e un passaggio di pesatura dei canali insegna alla rete quali feature sono più importanti.
Da una stima grezza a una scena multi-vista precisa
DFCNet usa una strategia in due fasi per creare le viste mancanti. Prima genera una stima grezza del campo di luce completo usando un metodo di interpolazione standard, che rende il compito di apprendimento più stabile. Poi affina questa stima utilizzando le feature apprese e una riorganizzazione intelligente dei dati che può gestire sia fattori di upscaling semplici che più insoliti. Questo progetto permette al modello di funzionare sia per l’interpolazione, dove nuove viste vengono create tra quelle catturate, sia per l’estrapolazione, dove vengono sintetizzate viste appena fuori dalla griglia catturata. Su diversi dataset sintetici e del mondo reale, il metodo ottiene costantemente punteggi superiori rispetto alle alternative di punta nelle misure di qualità dell’immagine e preserva meglio texture sottili e linee geometriche morbide che riflettono relazioni di profondità corrette.
Perché questi risultati contano
Per il lettore generale, il messaggio chiave è che gli autori hanno trovato un modo più intelligente per ricostruire immagini ricche e multi-vista da dati limitati allineando la rete neurale a come la luce viaggia realmente attraverso una scena. Il loro sistema, DFCNet, trasforma un insieme sparso di viste in un campo di luce dettagliato che conserva motivi fini, bordi e indizi di profondità in modo più fedele rispetto ai metodi precedenti, restando comunque sufficientemente efficiente per l’uso pratico. Questo miglioramento avvicina l’imaging del campo di luce a applicazioni quotidiane, dalle foto rifocalizzate più nitide a esperienze di realtà virtuale e aumentata più convincenti, anche quando l’hardware o i tempi di acquisizione sono limitati.
Citazione: Salem, A., Elkady, E., Ibrahem, H. et al. Directionally factorized light field reconstruction with cross-epipolar and spatial modeling. Sci Rep 16, 15755 (2026). https://doi.org/10.1038/s41598-026-53241-9
Parole chiave: imaging del campo di luce, sintesi di viste, super-risoluzione angolare, rete neurale profonda, ricostruzione di scene 3D