Clear Sky Science · fr
Reconstruction de champs lumineux factorisée directionnellement avec modélisation croisée épipolaire et spatiale
Des photos plus nettes depuis de nombreux angles
Imaginez pouvoir changer la mise au point, le point de vue, ou même vous déplacer légèrement à l'intérieur d'une photo après l'avoir prise. C'est la promesse des caméras de champ lumineux, qui capturent non seulement l'endroit où la lumière frappe le capteur, mais aussi les directions d'où elle provient. Cet article présente une nouvelle façon de transformer un petit ensemble de telles vues angulaires en un champ lumineux riche et détaillé, rendant ces photos flexibles plus claires et plus utiles tout en maintenant les coûts de calcul sous contrôle.
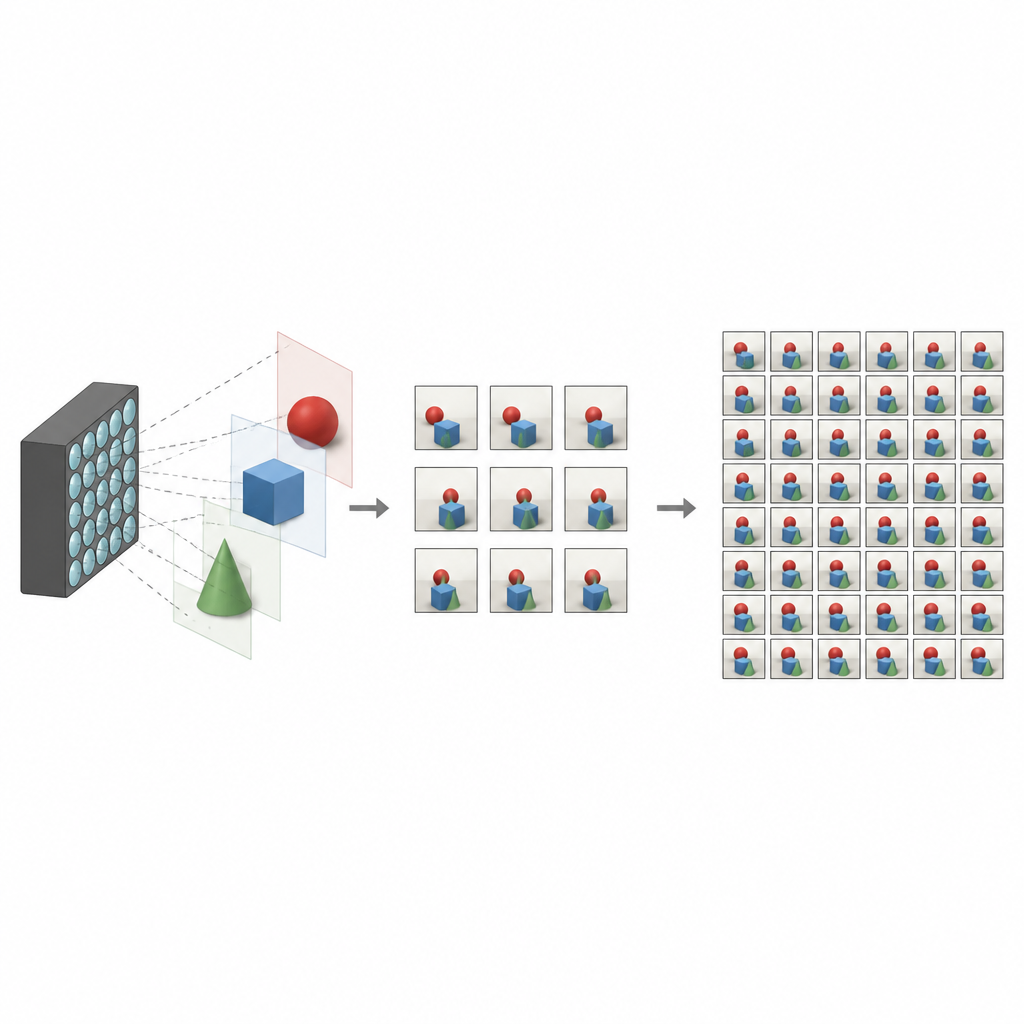
Ce qui rend les photos de champ lumineux particulières
Les appareils photo traditionnels aplatissent le monde en une seule image bidimensionnelle, fusionnant toute la lumière qui arrive sur chaque pixel. Les caméras de champ lumineux fonctionnent différemment. Elles enregistrent plusieurs images légèrement différentes d'une même scène, chacune depuis un point de vue légèrement décalé. Ensemble, ces vues codent la profondeur et le parallaxe, ces petits décalages que l'on perçoit quand on bouge la tête. Avec elles, un logiciel peut refocaliser une scène, supprimer des objets indésirables ou créer des expériences de réalité virtuelle immersives. Le problème, c'est que capturer une grille dense de vues exige généralement du matériel complexe ou des temps de capture longs, ce qui limite la diffusion de la technologie.
Le défi de combler les vues manquantes
Pour rendre les caméras de champ lumineux pratiques, les chercheurs cherchent à reconstruire un ensemble complet et dense de vues à partir de quelques-unes seulement qui sont réellement capturées. Les méthodes antérieures reposaient souvent sur l'estimation de cartes de profondeur détaillées, puis sur leur utilisation pour remettre en géométrie et mixer des images vers de nouveaux points de vue. Bien que puissantes, ces approches basées sur la profondeur sont sensibles aux erreurs et peuvent être lentes. D'autres techniques évitent la profondeur et tentent d'apprendre directement les relations entre vues voisines, mais elles peuvent manquer des relations à longue portée ou peiner sur des régions difficiles comme les bords, les réflexions et les zones où un objet en cache un autre.

Une nouvelle façon de lire la structure dans les vues
Les auteurs proposent DFCNet, un système d'apprentissage profond conçu pour la géométrie des champs lumineux. Plutôt que de traiter chaque petite image séparément, ils réarrangent les données en une disposition de macro‑pixels qui regroupe les pixels d'une même position à travers différentes vues. Cette disposition permet au réseau d'examiner comment les caractéristiques se déplacent entre les points de vue dans les directions horizontale et verticale, ce qui est étroitement lié à la profondeur de la scène. Des blocs constructifs spéciaux divisent le traitement en voies claires : certaines se concentrent sur les changements le long d'une ligne de points de vue, tandis que d'autres capturent les interactions entre lignes, par exemple là où des objets se chevauchent ou dévoilent des zones cachées. Une voie séparée affine les détails à l'intérieur de chaque vue, et une étape de pondération des canaux apprend au réseau quelles caractéristiques comptent le plus.
D'une estimation grossière à une scène multi‑vue précise
DFCNet utilise une stratégie en deux étapes pour créer les vues manquantes. D'abord, il génère une estimation grossière du champ lumineux complet en utilisant une méthode d'interpolation standard, ce qui stabilise la tâche d'apprentissage. Ensuite, il affine cette estimation en s'appuyant sur ses caractéristiques apprises et un réarrangement astucieux des données capable de gérer à la fois des facteurs d'agrandissement simples et inhabituels. Cette conception permet au modèle de fonctionner aussi bien pour l'interpolation, où de nouvelles vues sont créées entre des vues capturées, que pour l'extrapolation, où des vues juste en dehors de la grille capturée sont synthétisées. Sur plusieurs jeux de données synthétiques et réels, la méthode obtient systématiquement de meilleurs scores que les alternatives de pointe sur les mesures de qualité d'image, et préserve mieux les textures subtiles et les lignes géométriques lisses qui reflètent des relations de profondeur correctes.
Pourquoi ces résultats comptent
Pour un lecteur général, le message clé est que les auteurs ont trouvé une manière plus intelligente de reconstruire des images multi‑vues riches à partir de données limitées en alignant le réseau neuronal sur la façon dont la lumière voyage réellement dans une scène. Leur système, DFCNet, transforme un ensemble clairsemé de vues en un champ lumineux détaillé qui conserve plus fidèlement les motifs fins, les contours et les indices de profondeur que les méthodes précédentes, tout en restant suffisamment efficace pour une utilisation pratique. Cette amélioration rapproche l'imagerie de champ lumineux des applications quotidiennes, des photos refocalisées plus nettes aux expériences de réalité virtuelle et augmentée plus convaincantes, même lorsque le matériel ou le temps de capture sont limités.
Citation: Salem, A., Elkady, E., Ibrahem, H. et al. Directionally factorized light field reconstruction with cross-epipolar and spatial modeling. Sci Rep 16, 15755 (2026). https://doi.org/10.1038/s41598-026-53241-9
Mots-clés: imagerie de champ lumineux, synthèse de vues, sur‑échantillonnage angulaire, réseau neuronal profond, reconstruction de scène 3D