Clear Sky Science · pt
Reconstrução de campo de luz fatorizada direcionalmente com modelagem cruzada epipolar e espacial
Fotos mais nítidas a partir de muitos ângulos
Imagine poder mudar o foco, o ponto de vista ou até se deslocar um pouco dentro de uma foto depois de tirá‑la. Essa é a promessa das câmeras de campo de luz, que capturam não apenas onde a luz incide no sensor, mas também as direções de onde ela vem. Este artigo apresenta uma nova forma de transformar um pequeno conjunto dessas vistas anguladas em um campo de luz rico e detalhado, tornando essas fotos flexíveis mais claras e úteis, mantendo os custos computacionais sob controle.
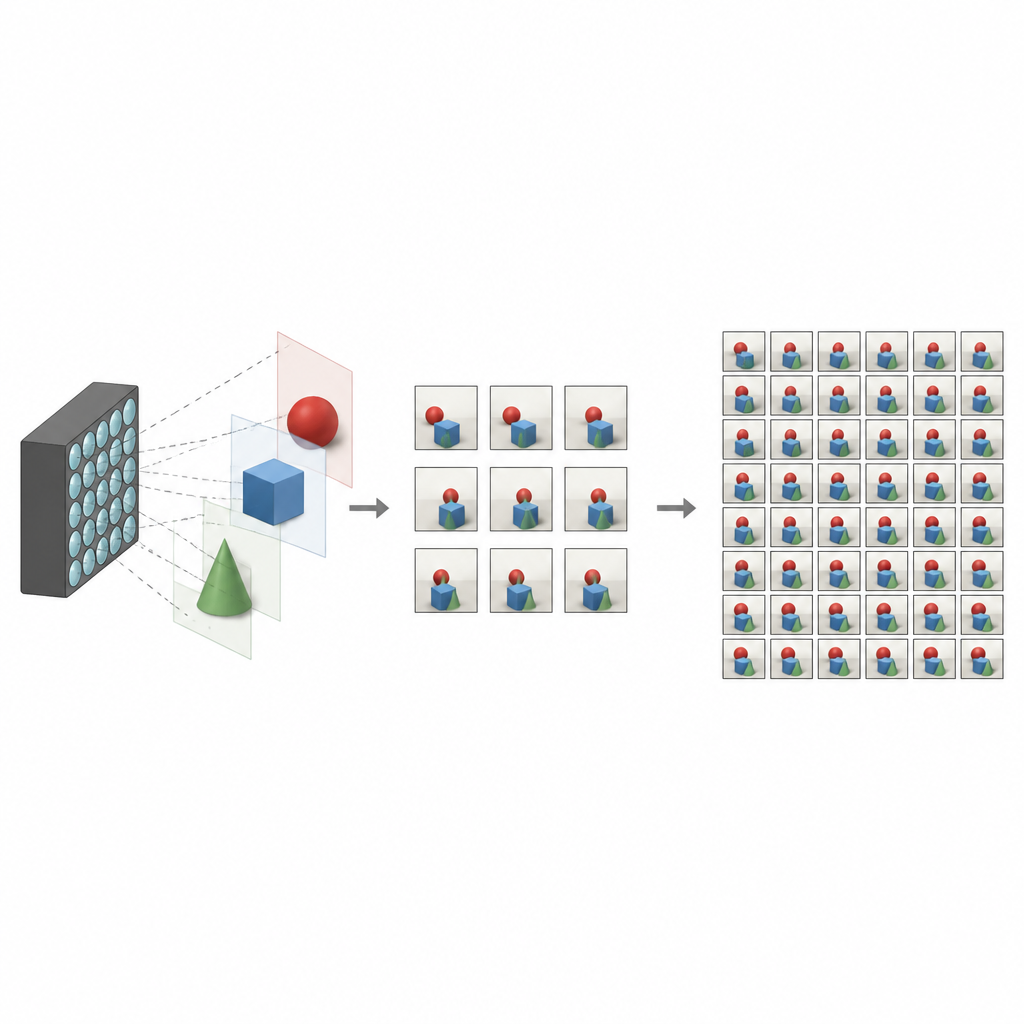
O que torna as fotos de campo de luz especiais
Câmeras tradicionais achatam o mundo em uma única imagem bidimensional, misturando toda a luz que chega a cada pixel. Câmeras de campo de luz funcionam de forma diferente. Elas registram muitas imagens ligeiramente diferentes da mesma cena, cada uma de um ponto de vista um pouco deslocado. Juntas, essas vistas codificam profundidade e paralaxe, os pequenos deslocamentos que você percebe quando move a cabeça. Com elas, softwares podem refocar uma cena, remover objetos indesejados ou criar experiências imersivas de realidade virtual. A limitação é que capturar uma grade densa de vistas geralmente exige hardware complexo ou longos tempos de captura, o que restringe o uso amplo da tecnologia.
O desafio de preencher vistas faltantes
Para tornar as câmeras de campo de luz práticas, pesquisadores buscam reconstruir um conjunto completo e denso de vistas a partir de apenas algumas capturadas. Métodos anteriores frequentemente dependiam de estimativas detalhadas de mapas de profundidade, usando‑as depois para deformar e mesclar imagens em novos pontos de vista. Embora poderosos, esses métodos baseados em profundidade são sensíveis a erros e podem ser lentos. Outras técnicas dispensam profundidade e tentam aprender diretamente como vistas vizinhas se relacionam, mas podem perder relações de longo alcance ou ter dificuldades em regiões problemáticas, como bordas, reflexos e áreas onde um objeto obstrui outro.

Uma nova forma de ler a estrutura nas vistas
Os autores propõem o DFCNet, um sistema de aprendizado profundo ajustado à geometria dos campos de luz. Em vez de tratar cada pequena imagem separadamente, eles reorganizam os dados em um layout de macropixel que agrupa pixels da mesma posição através de diferentes vistas. Esse layout permite que a rede examine como características se movem entre pontos de vista nas direções horizontal e vertical, o que está intimamente ligado à profundidade da cena. Blocos construtivos especiais dividem o processamento em caminhos claros: alguns se concentram em mudanças ao longo de uma única linha de pontos de vista, enquanto outros capturam interações entre linhas, como onde objetos se sobrepõem ou revelam áreas ocultas. Um caminho separado aprimora detalhes dentro de cada vista, e uma etapa de ponderação de canais ensina à rede quais características importam mais.
De um palpite bruto a uma cena multivista precisa
O DFCNet usa uma estratégia em duas etapas para criar vistas faltantes. Primeiro, gera um palpite grosseiro do campo de luz completo usando um método padrão de interpolação, o que torna a tarefa de aprendizado mais estável. Em seguida, refina esse palpite usando suas características aprendidas e uma reorganização inteligente dos dados que pode lidar tanto com fatores de upscaling simples quanto com os mais incomuns. Esse projeto permite que o modelo funcione tanto para interpolação, quando novas vistas são criadas entre as capturadas, quanto para extrapolação, quando vistas fora da grade capturada são sintetizadas. Em vários conjuntos de dados sintéticos e do mundo real, o método apresenta pontuações consistentemente superiores às alternativas líderes em medidas de qualidade de imagem, e preserva melhor texturas sutis e linhas geométricas suaves que refletem relações de profundidade corretas.
Por que esses resultados importam
Para o leitor em geral, a mensagem principal é que os autores encontraram uma maneira mais inteligente de reconstruir imagens ricas e multivista a partir de dados limitados, alinhando a rede neural com a forma como a luz realmente atravessa uma cena. Seu sistema, o DFCNet, transforma um conjunto esparso de vistas em um campo de luz detalhado que mantém padrões finos, bordas e pistas de profundidade com mais fidelidade do que métodos anteriores, sendo ainda eficiente o suficiente para uso prático. Essa melhoria aproxima a imagem de campo de luz de aplicações cotidianas, desde fotos refocadas mais nítidas até experiências de realidade virtual e aumentada mais convincentes, mesmo quando o hardware ou o tempo de captura são restritos.
Citação: Salem, A., Elkady, E., Ibrahem, H. et al. Directionally factorized light field reconstruction with cross-epipolar and spatial modeling. Sci Rep 16, 15755 (2026). https://doi.org/10.1038/s41598-026-53241-9
Palavras-chave: imagem de campo de luz, síntese de vistas, super-resolução angular, rede neural profunda, reconstrução de cena 3D