Clear Sky Science · de
Richtungsfaktorielle Rekonstruktion von Lichtfeldern mit cross-epipolarer und räumlicher Modellierung
Schärfere Fotos aus vielen Blickwinkeln
Stellen Sie sich vor, Sie könnten nach der Aufnahme noch den Fokus ändern, die Perspektive wechselnd oder sich leicht im Bild bewegen. Das versprechen Lichtfeldkameras, die nicht nur registrieren, wo Licht auf den Sensor trifft, sondern auch, aus welchen Richtungen es kommt. Dieses Paper stellt eine neue Methode vor, um aus einer kleinen Menge solcher schrägen Ansichten ein reiches, detailliertes Lichtfeld zu erzeugen, wodurch diese flexiblen Fotos klarer und nützlicher werden, während die Rechenkosten beherrschbar bleiben.
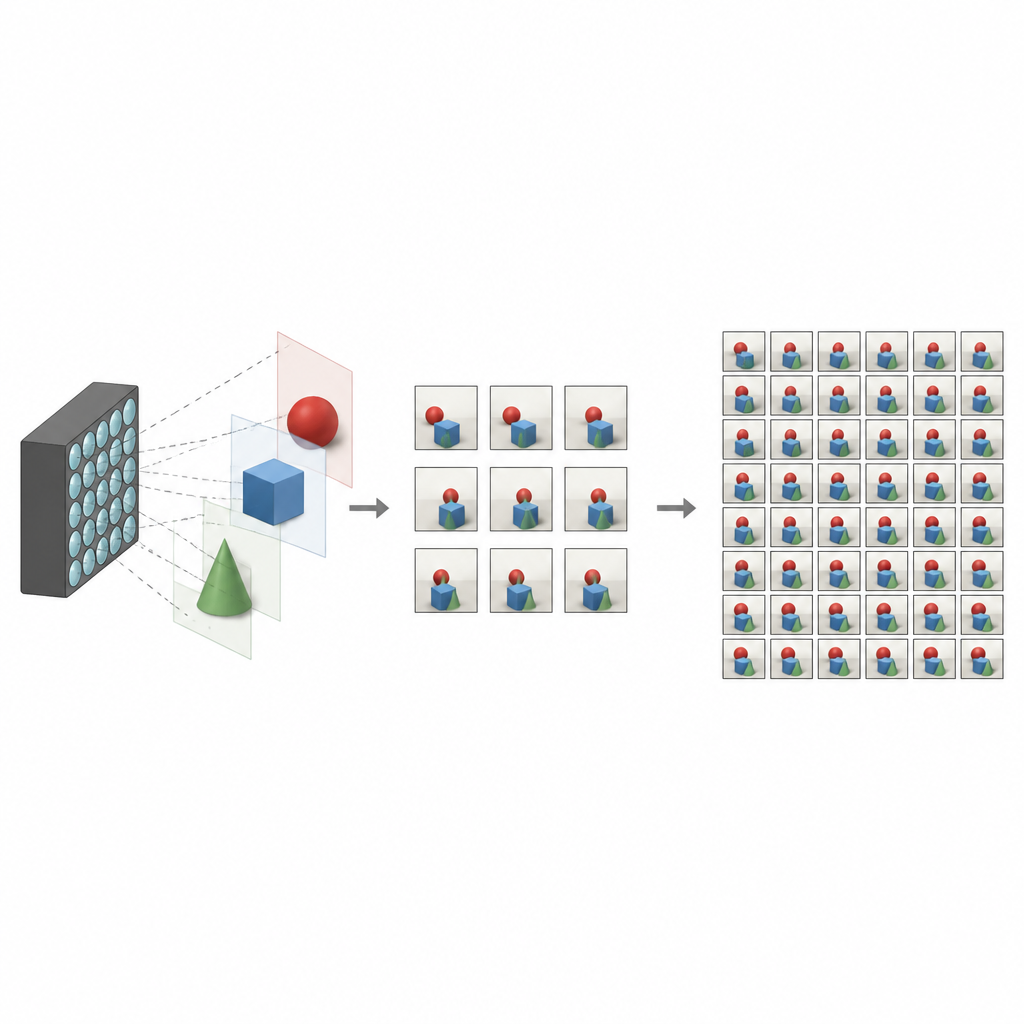
Was Lichtfeldfotos besonders macht
Konventionelle Kameras reduzieren die Welt auf ein zweidimensionales Bild und vermischen das Licht, das an jedem Pixel ankommt. Lichtfeldkameras funktionieren anders: Sie zeichnen viele leicht unterschiedliche Bilder derselben Szene auf, jeweils aus leicht verschobenen Blickwinkeln. Zusammen kodieren diese Ansichten Tiefe und Parallaxe — die kleinen Verschiebungen, die man sieht, wenn man den Kopf bewegt. Mit diesen Daten kann Software eine Szene neu fokussieren, unerwünschte Objekte entfernen oder eindrucksvolle Virtual-Reality-Erlebnisse erzeugen. Der Haken ist, dass das Erfassen eines dichten Sichtgitter oft komplexe Hardware oder lange Aufnahmezeiten erfordert, was die Verbreitung einschränkt.
Die Herausforderung, fehlende Ansichten zu ergänzen
Um Lichtfeldkameras praktikabel zu machen, wollen Forscher aus nur wenigen tatsächlich aufgenommenen Ansichten ein vollständiges, dichtes Blickfeld rekonstruieren. Frühere Methoden beruhten oft auf der Schätzung detaillierter Tiefenkarten, mit denen Bilder in neue Blickrichtungen gewarpt und gemischt wurden. Solche tiefenbasierten Ansätze sind wirkungsvoll, aber empfindlich gegenüber Fehlern und können langsam sein. Andere Verfahren verzichten auf Tiefe und versuchen stattdessen, direkt zu lernen, wie benachbarte Ansichten zusammenhängen; sie können jedoch weiträumige Beziehungen übersehen oder in schwierigen Bereichen wie Kanten, Spiegelungen und sich überlappenden Objekten Probleme haben.

Eine neue Art, Struktur in den Ansichten zu lesen
Die Autoren schlagen DFCNet vor, ein Deep-Learning-System, das auf die Geometrie von Lichtfeldern zugeschnitten ist. Anstatt jede kleine Aufnahme separat zu behandeln, ordnen sie die Daten in einem Makropixel-Layout neu, das Pixel derselben Position über verschiedene Ansichten gruppiert. Dieses Layout lässt das Netzwerk untersuchen, wie sich Merkmale in horizontaler und vertikaler Richtung über die Blickwinkel hinweg bewegen — ein Vorgang, der eng mit der Szenentiefe verbunden ist. Spezielle Bausteine teilen die Verarbeitung in klar abgegrenzte Pfade: Einige konzentrieren sich auf Änderungen entlang einer einzigen Blicklinienachse, andere erfassen Interaktionen zwischen Linien, etwa dort, wo Objekte überlappen oder verdeckte Bereiche sichtbar werden. Ein separater Pfad schärft Details innerhalb jeder Ansicht, und ein Kanalgewichtungs-Schritt lehrt das Netzwerk, welche Merkmale am wichtigsten sind.
Von groben Vermutungen zu präzisen Mehransichten-Szenen
DFCNet nutzt eine zweistufige Strategie zur Erzeugung fehlender Ansichten. Zuerst erzeugt es eine grobe Schätzung des vollständigen Lichtfelds mit einer standardmäßigen Interpolationsmethode, was die Lernaufgabe stabilisiert. Anschließend verfeinert es diese Schätzung mithilfe gelernter Merkmale und einer cleveren Umordnung der Daten, die sowohl einfache als auch ungewöhnlichere Hochskalierungsfaktoren verarbeiten kann. Dieses Design ermöglicht es dem Modell, sowohl bei Interpolation — also Erzeugung neuer Ansichten zwischen aufgenommenen — als auch bei Extrapolation — Synthese von Ansichten außerhalb des aufgenommenen Gitters — zu arbeiten. Über mehrere synthetische und reale Datensätze hinweg erzielt die Methode durchgängig bessere Werte bei Bildqualitätsmaßen und bewahrt subtile Texturen sowie glatte geometrische Linien, die korrekte Tiefenbeziehungen widerspiegeln.
Warum diese Ergebnisse wichtig sind
Für eine allgemeine Leserschaft ist die Kernbotschaft, dass die Autoren einen klügeren Weg gefunden haben, aus begrenzten Daten reiche Mehransichtsbilder zu rekonstruieren, indem sie das neuronale Netzwerk an die tatsächliche Lichtgeometrie anpassen. Ihr System DFCNet verwandelt eine spärliche Menge an Ansichten in ein detailliertes Lichtfeld, das feine Muster, Kanten und Tiefenhinweise treuer bewahrt als frühere Methoden, und das gleichzeitig effizient genug für praktische Anwendungen bleibt. Diese Verbesserung bringt die Lichtfeldbildgebung näher an den Alltag — von schärferen nachträglich fokussierbaren Fotos bis zu überzeugenderen Virtual- und Augmented-Reality-Erlebnissen, selbst wenn Hardware oder Aufnahmezeit begrenzt sind.
Zitation: Salem, A., Elkady, E., Ibrahem, H. et al. Directionally factorized light field reconstruction with cross-epipolar and spatial modeling. Sci Rep 16, 15755 (2026). https://doi.org/10.1038/s41598-026-53241-9
Schlüsselwörter: Lichtfeldbildgebung, Ansichtssynthese, winkelige Superauflösung, tiefes neuronales Netzwerk, 3D-Szenenrekonstruktion