Clear Sky Science · pl
Kierunkowo sparametryzowana rekonstrukcja pola świetlnego z modelowaniem krzyżowo-epipolarnym i przestrzennym
Bardziej ostre zdjęcia z wielu kątów
Wyobraź sobie możliwość zmiany ostrości, punktu widzenia, a nawet delikatnego poruszania się w obrębie zdjęcia po jego zrobieniu. To obietnica aparatów pola świetlnego, które rejestrują nie tylko miejsce, w którym światło pada na matrycę, ale też kierunki, z których ono pochodzi. W tym artykule przedstawiono nowy sposób przekształcania niewielkiego zestawu takich skośnych widoków w bogate, szczegółowe pole świetlne, co sprawia, że te elastyczne zdjęcia są bardziej klarowne i użyteczne przy zachowaniu rozsądnych kosztów obliczeniowych.
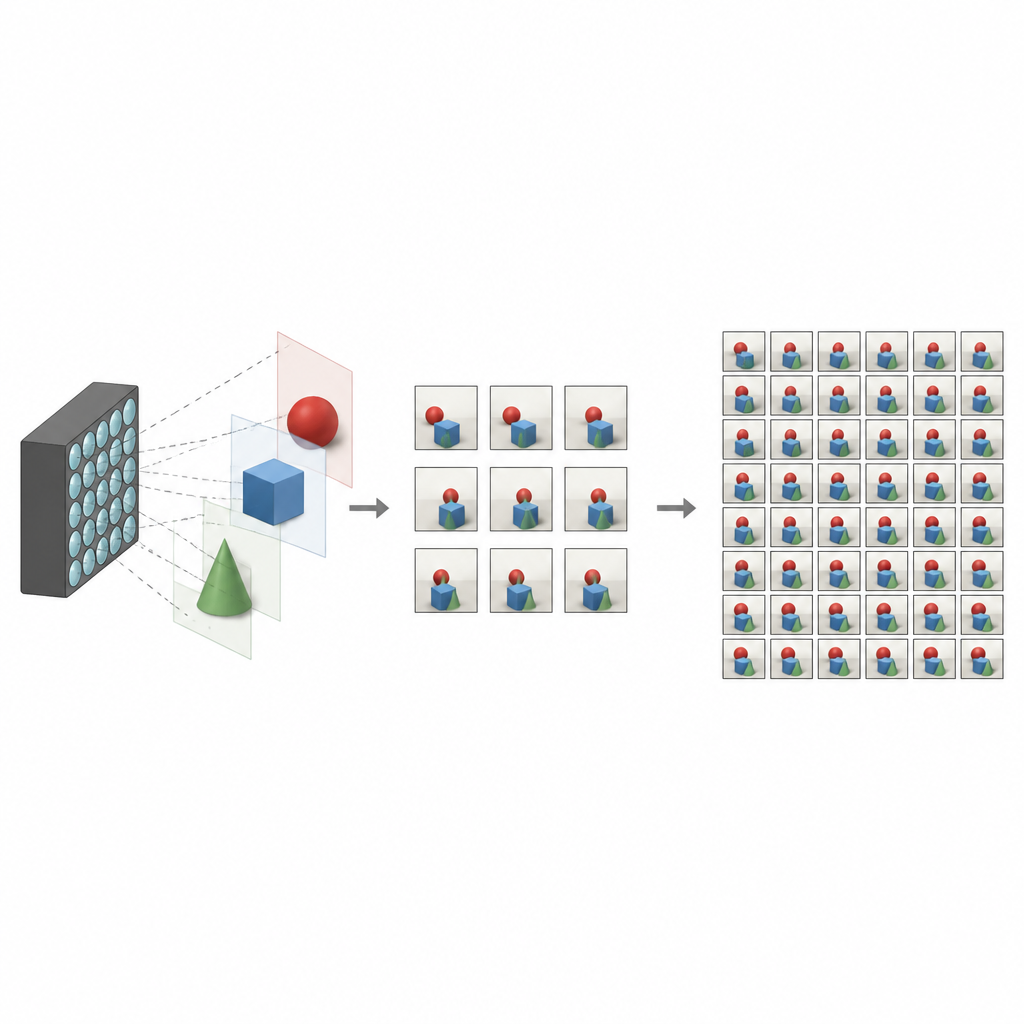
Co wyróżnia zdjęcia pola świetlnego
Tradycyjne aparaty spłaszczają świat do pojedynczego obrazu dwuwymiarowego, mieszając całe światło docierające do każdego piksela. Aparaty pola świetlnego działają inaczej. Rejestrują wiele nieco różnych obrazów tej samej sceny, każdy z nieco przesuniętego punktu widzenia. Razem te widoki kodują głębię i paralaksę — drobne przesunięcia, które obserwujemy, gdy ruszamy głową. Dzięki nim oprogramowanie może przeostrzyć scenę, usuwać niechciane obiekty lub tworzyć immersyjne doświadczenia w wirtualnej rzeczywistości. Wadą jest to, że uchwycenie gęstej siatki widoków zwykle wymaga złożonego sprzętu lub długiego czasu rejestracji, co ogranicza zastosowania tej technologii.
Problem uzupełniania brakujących widoków
Aby uczynić aparaty pola świetlnego praktycznymi, badacze dążą do odtworzenia pełnego, gęstego zestawu widoków z zaledwie kilku rzeczywiście zarejestrowanych. Wcześniejsze metody często opierały się na estymacji szczegółowych map głębokości, a następnie wykorzystywały je do zniekształcania i mieszania obrazów w nowe punkty widzenia. Choć efektywne, podejścia oparte na głębokości są wrażliwe na błędy i mogą być wolne. Inne techniki pomijają głębokość i próbują bezpośrednio nauczyć się relacji między sąsiednimi widokami, ale mogą nie uchwycić długozasięgowych zależności lub mieć problemy w trudnych obszarach, takich jak krawędzie, odbicia czy miejsca, gdzie jeden obiekt zasłania inny.

Nowy sposób odczytu struktury w widokach
Autorzy proponują DFCNet, system uczenia głębokiego dopasowany do geometrii pól świetlnych. Zamiast traktować każdy mały obraz osobno, przearanżowują dane w układ makropikseli, który grupuje razem piksele z tej samej pozycji w różnych widokach. Ten układ pozwala sieci badać, jak cechy przemieszczają się między punktami widzenia w poziomie i pionie, co jest ściśle powiązane z głębokością sceny. Specjalne bloki dzielą przetwarzanie na wyraźne ścieżki: niektóre koncentrują się na zmianach wzdłuż pojedynczej linii widoków, inne przechwytują interakcje między liniami, na przykład tam, gdzie obiekty nakładają się lub odsłaniają ukryte obszary. Oddzielna ścieżka wyostrza detale w obrębie każdego widoku, a etap ważenia kanałów uczy sieć, które cechy są najważniejsze.
Od przybliżenia do precyzyjnej sceny wielowidokowej
DFCNet stosuje dwuetapową strategię tworzenia brakujących widoków. Najpierw generuje przybliżony pełny obraz pola świetlnego za pomocą standardowej metody interpolacji, co stabilizuje zadanie uczenia. Następnie udoskonala to przybliżenie, wykorzystując wyuczone cechy i sprytne przearanżowanie danych, które radzi sobie zarówno z prostymi, jak i nietypowymi współczynnikami skalowania. Ten projekt pozwala modelowi działać zarówno w trybie interpolacji, gdzie nowe widoki powstają między zarejestrowanymi, jak i ekstrapolacji, gdzie syntezowane są widoki tuż poza uchwyconą siatką. Na kilku syntetycznych i rzeczywistych zbiorach danych metoda konsekwentnie osiąga wyższe wyniki niż czołowe alternatywy w miarach jakości obrazu i lepiej zachowuje subtelne tekstury oraz gładkie linie geometryczne odzwierciedlające poprawne zależności głębi.
Dlaczego te wyniki są istotne
Dla ogólnego czytelnika kluczowy wniosek jest taki, że autorzy znaleźli inteligentniejszy sposób rekonstrukcji bogatych, wielowidokowych obrazów z ograniczonych danych, dopasowując sieć neuronową do tego, jak światło faktycznie przemieszcza się przez scenę. Ich system, DFCNet, zamienia rzadki zestaw widoków w szczegółowe pole świetlne, które wierniej zachowuje drobne wzory, krawędzie i wskazówki głębi niż wcześniejsze metody, pozostając jednocześnie na tyle wydajnym, by nadawać się do praktycznych zastosowań. To ulepszenie przybliża obrazowanie pola świetlnego do codziennych zastosowań — od ostrzejszych zdjęć z możliwością refokusowania po bardziej przekonujące doświadczenia w wirtualnej i rozszerzonej rzeczywistości — nawet gdy sprzęt lub czas rejestracji są ograniczone.
Cytowanie: Salem, A., Elkady, E., Ibrahem, H. et al. Directionally factorized light field reconstruction with cross-epipolar and spatial modeling. Sci Rep 16, 15755 (2026). https://doi.org/10.1038/s41598-026-53241-9
Słowa kluczowe: obrazowanie pola świetlnego, synthesa widoków, kątowa superrozdzielczość, głęboka sieć neuronowa, rekonstrukcja sceny 3D