Clear Sky Science · zh
多学科专家对围绕减重手术问题的大型语言模型进行评估:ERNIE Bot 4.0、ChatGPT-4、Claude 3 Opus 与 Gemini Pro 的比较分析
这对考虑减重手术的人为何重要
考虑减重手术的人经常求助于在线工具和聊天机器人以获取快速答案。本研究提出一个简单但重要的问题:当大型语言模型聊天机器人回答关于减重手术的常见问题时,它们的回复在多大程度上准确且完整,能否真正支持患者与临床医师?
现代聊天机器人走进临床
研究人员考察了四款基于大型语言模型的常用聊天机器人:ERNIE Bot 4.0、ChatGPT-4、Claude 3 Opus 与 Gemini Pro。他们关注的是与减重手术相关的真实问题,如谁有资格手术、如何准备、可预期的风险以及术后需要哪些生活方式改变。从最初从医学文献、社交媒体和门诊访问收集的 200 个问题中,筛选出 50 个最能代表患者关切的问题。每个聊天机器人回答所有 50 个问题,共产生 200 条回答,随后这些回答被翻译并标准化以供评审。
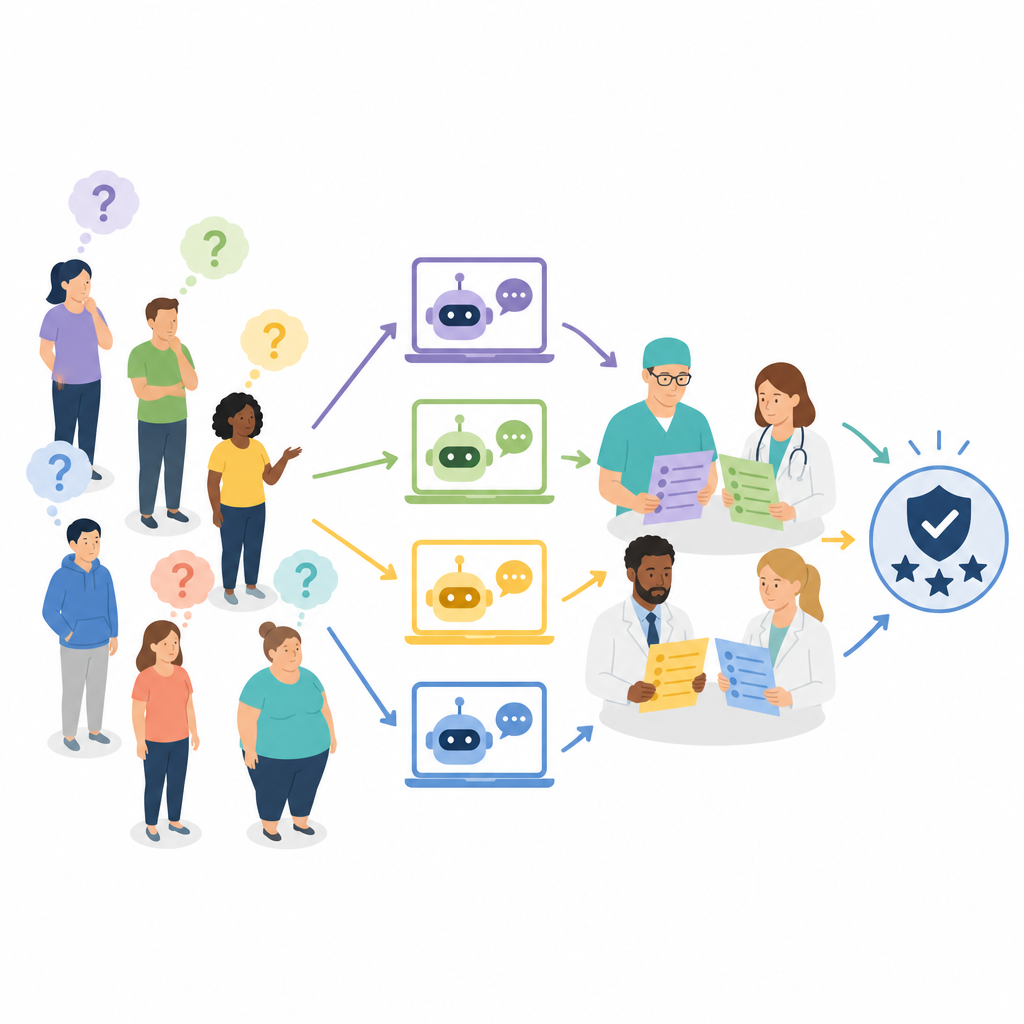
多位专家,而非单一视角
研究团队没有仅邀请外科医生来评判回复,而是组建了一支由七位资深专业人员组成的多学科小组:四名减重外科医生、一名肥胖病学医生和两名营养师。每位专家独立对每个回答的准确性进行评分,并对较好的回答评估其全面性。准确性采用三级评分,从明显错误且可能有害到完全正确。全面性采用五级评分,反映回答在手术细节、风险与随访护理等关键点上的覆盖程度。评分过程为盲审,评审者不知道哪些回答来自哪个聊天机器人,且回答被打乱并分散到多个评审会话以减少偏见。
聊天机器人的表现
总体而言,这四款聊天机器人的表现参差不齐。综合所有专家评分后,ERNIE Bot 4.0 的平均准确性得分最高,但 ChatGPT-4 在被评为“良好”回答的比例上最高,且没有收到任何“差”的评分。Claude 3 Opus 倾向于给出最长且最详尽的回答,而 Gemini Pro 在准确性方面明显落后,其被评为“良好”的回答不足一半,且多数评审对其若干回答给出了“差”的评分。所有聊天机器人都难以提供完整覆盖的内容:即便是较好的回答通常也仅达到中等的细节水平,且没有一款能持续提供人们在就手术做出充分知情决定时所需的深度。
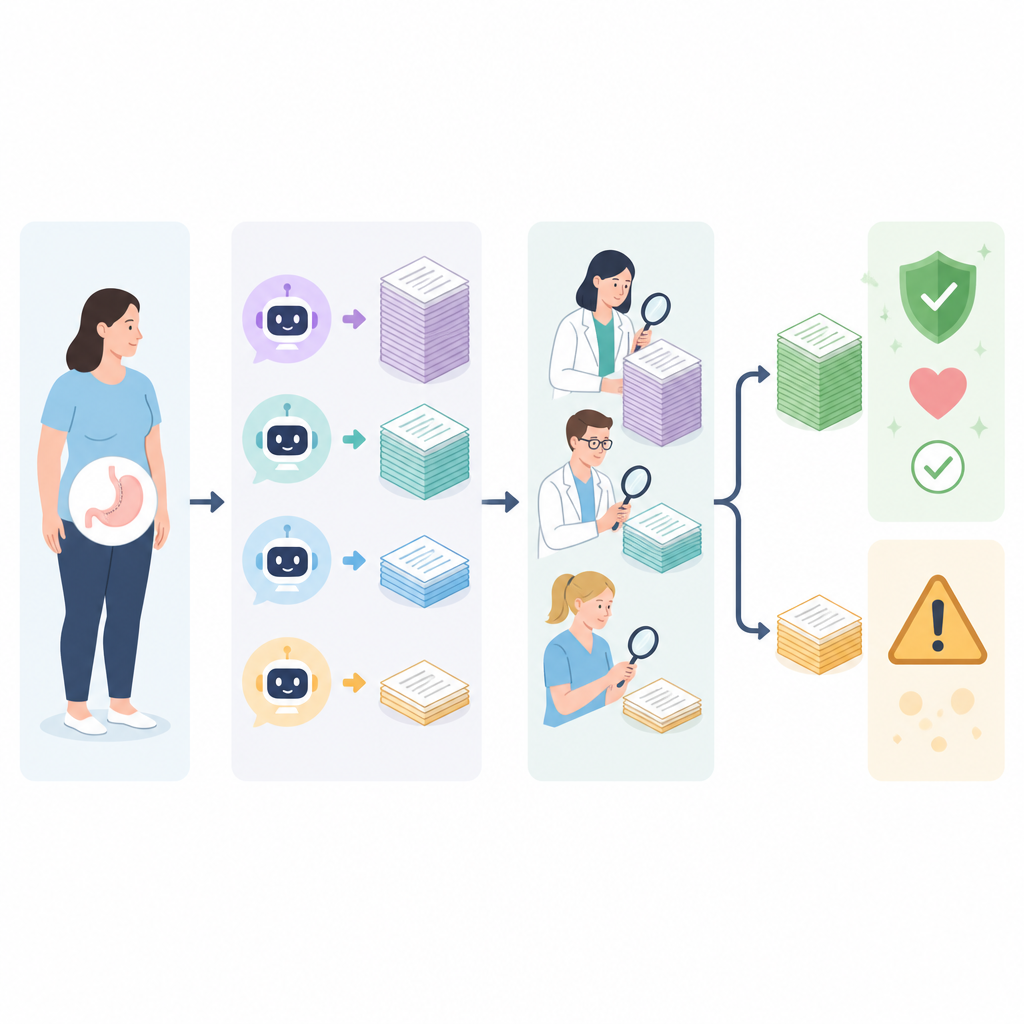
回答的不足之处
每款聊天机器人最薄弱的领域均为解释恢复、风险与并发症。这些主题常涉及微妙的权衡和长期随访,工具往往过度简化。有些回答给出不切实际的减重预期或遗漏了重要的安全信息,而另一些则过于笼统,对真实患者而言缺乏实用性。当专家要求聊天机器人审查并纠正其最差的回答时,大多数工具都有明显改进,尤其是在被提示检索循证资料时。然而,即便在自我纠正与联网检索后,某些模型的部分回答仍然不准确,表明仅有互联网访问并不能保证可靠的医疗指导。
这对患者与临床医师意味着什么
目前,研究表明大型语言模型聊天机器人在减重手术的教育性辅助方面可以发挥一定作用,尤其适用于基础问题与早期信息搜寻。但它们尚不足以替代专业建议,也不应单独用于指导关于手术、恢复或长期护理的决策。作者主张,要实现更安全的使用,需要开发专门针对减重医学、基于坚实证据并在外科医生、临床医生、营养师与护士持续参与下迭代的模型。通过谨慎设计与严格监管,这些工具终有可能在患者与其护理团队之间促成更有信息的对话,而非取而代之。
引用: Cai, J., Chen, J., Yu, T. et al. Multidisciplinary expert evaluation of large language models on questions regarding bariatric surgery: a comparative analysis of ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro. Sci Rep 16, 16043 (2026). https://doi.org/10.1038/s41598-026-46766-6
关键词: 减重手术, 体重减轻手术, 医疗聊天机器人, 大型语言模型, 患者教育