Clear Sky Science · ru
Мультидисциплинарная экспертная оценка крупных языковых моделей на вопросах, связанных с бариатрической хирургией: сравнительный анализ ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus и Gemini Pro
Почему это важно для людей, рассматривающих операцию по снижению веса
Люди, которые задумываются о бариатрической операции, часто обращаются к интернет-ресурсам и чатботам за быстрыми ответами. В этом исследовании задан простой, но важный вопрос: насколько точны и полны ответы чатботов на базе крупных языковых моделей на типичные вопросы о бариатрической хирургии и могут ли они действительно поддерживать пациентов и врачей?
Современные чатботы в клинической практике
Исследователи изучили четыре широко используемых чатбота на базе крупных языковых моделей: ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus и Gemini Pro. Они сосредоточились на реальных вопросах о бариатрической хирургии: кто подходит для операции, как подготовиться, каких рисков ожидать и какие изменения в образе жизни требуются после операции. Из первоначальной выборки в 200 вопросов, собранных из медицинской литературы, социальных сетей и посещений клиник, отобрали 50, наиболее полно отражающих заботы пациентов. Каждый чатбот ответил на все 50 вопросов, в сумме дав 200 ответов, которые затем были переведены и стандартизированы для рецензирования.
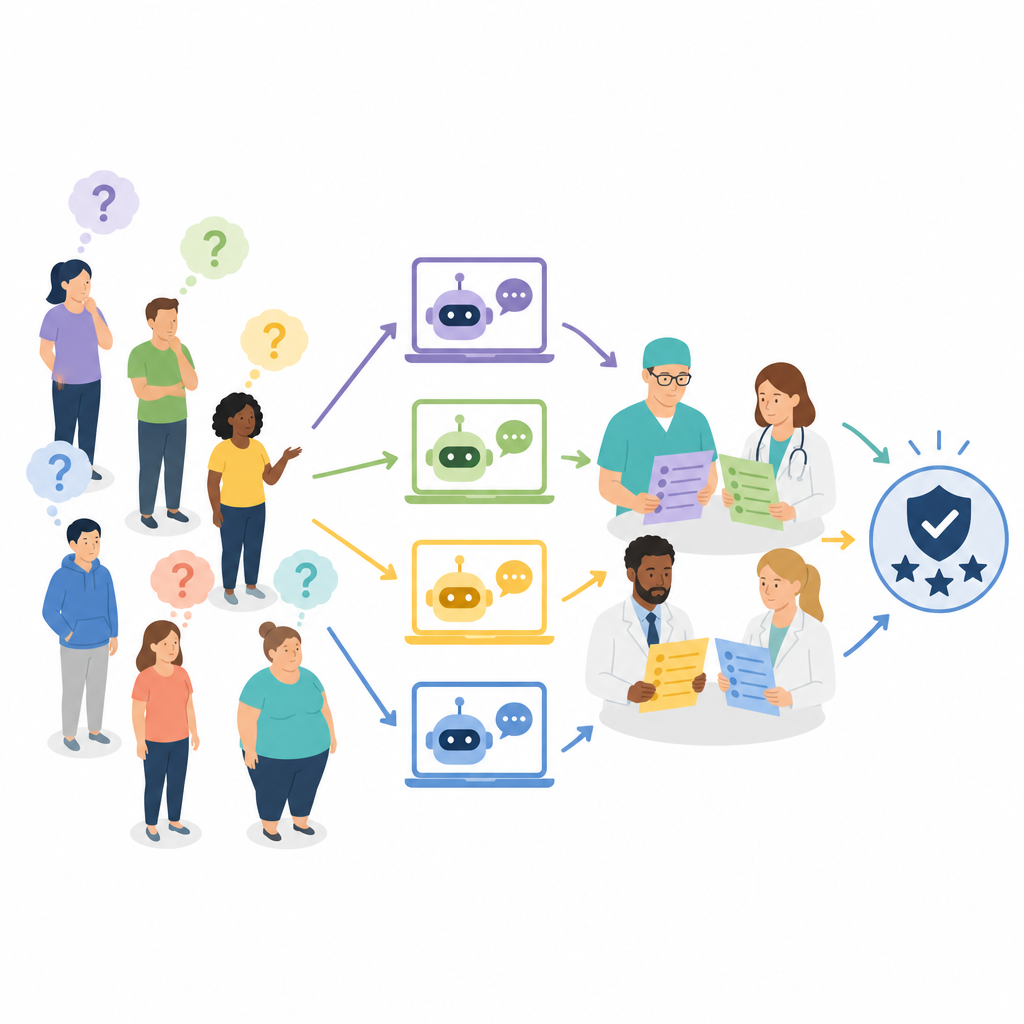
Много экспертов — не одна точка зрения
Вместо того чтобы привлекать только хирургов для оценки ответов, команда собрала мультидисциплинарную комиссию из семи опытных специалистов: четырёх бариатрических хирургов, одного врача-специалиста по ожирению и двух диетологов. Каждый эксперт независимо оценивал точность каждого ответа и, для лучших ответов, их полноту. Точность оценивалась по трёхбалльной шкале — от явно неверного и потенциально вредного до полностью корректного. Полнота оценивалась по пятибалльной шкале, отражающей, насколько ответ охватывает ключевые аспекты, такие как детали процедуры, риски и последующее наблюдение. Процесс оценки был слепым: рецензенты не знали, какой чатбот дал тот или иной ответ; ответы перемешивались и распределялись по нескольким сессиям, чтобы снизить предвзятость.
Как выступили чатботы
В целом четыре чатбота показали смешанные результаты. ERNIE Bot 4.0 получил наивысшую среднюю оценку точности при суммировании всех оценок экспертов, но ChatGPT-4 продемонстрировал наибольшую долю ответов, признанных просто «хорошими», и не получил ни одной плохой оценки. Claude 3 Opus склонялся к самым длинным и подробным ответам, тогда как Gemini Pro заметно отставал по точности: меньше половины его ответов были оценены как хорошие, и несколько получили плохие оценки от большинства рецензентов. Всем чатботам было трудно обеспечить полное покрытие тем: даже лучшие ответы обычно достигали лишь умеренного уровня детализации, и ни один инструмент последовательно не предлагал глубину, необходимую людям для полностью обоснованных решений об операции.
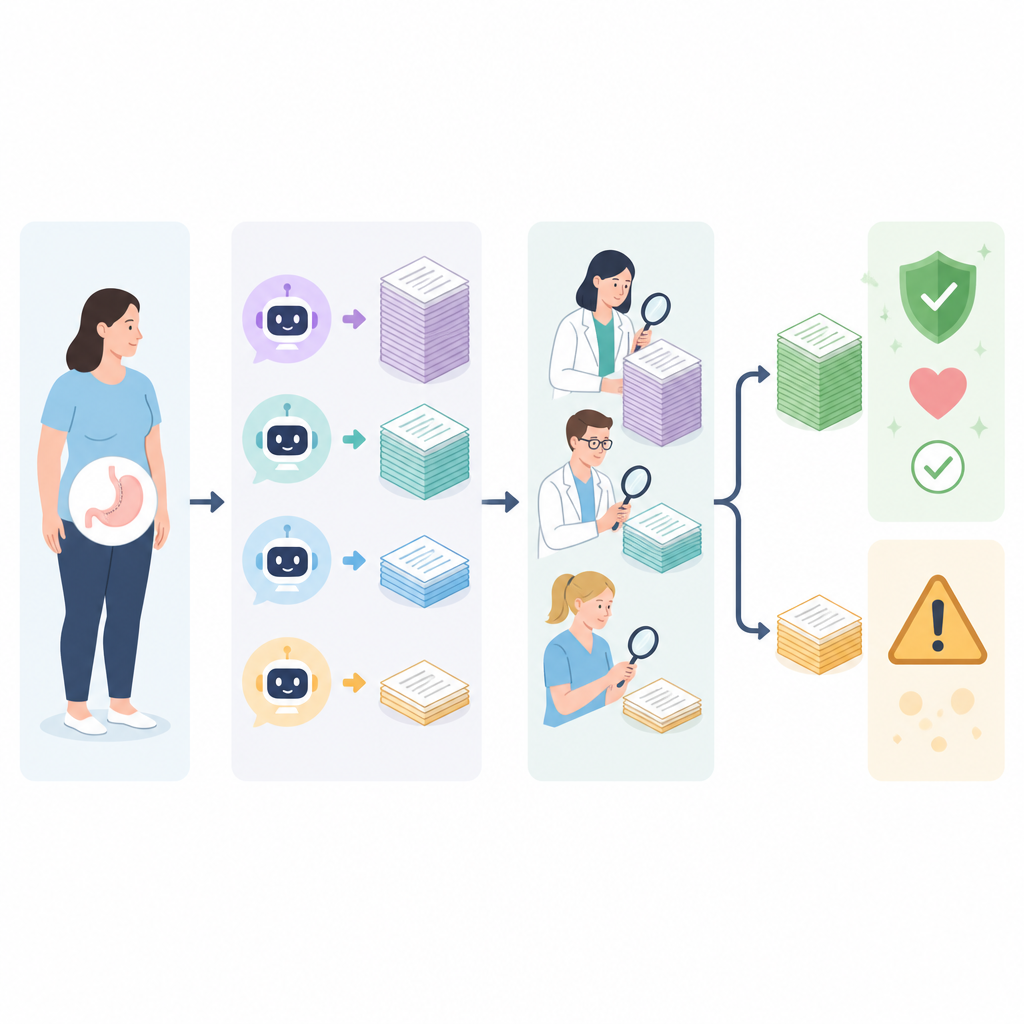
Где ответы уступают
Самой слабой темой для всех чатботов было объяснение восстановления, рисков и осложнений. Эти темы часто включают тонкие компромиссы и долгосрочное наблюдение, которые инструменты склонны упрощать. Некоторые ответы создавали нереалистичные ожидания относительно потери веса или опускали важную информацию о безопасности, в то время как другие давали слишком общие советы, бесполезные для реальных пациентов. Когда эксперты просили чатботов пересмотреть и исправить их худшие ответы, большинство инструментов заметно улучшались, особенно при указании проверить источники на основе доказательств в интернете. Однако даже с самоисправлением и поиском в сети некоторые ответы отдельных моделей оставались неточными, что показывает: доступ в интернет сам по себе не гарантирует надёжные медицинские рекомендации.
Что это означает для пациентов и врачей
На данном этапе исследование предполагает, что чатботы на базе крупных языковых моделей могут быть полезны как образовательные помощники по бариатрической хирургии, особенно для базовых вопросов и первичного поиска информации. Они ещё не готовы заменить профессиональную консультацию или самостоятельно руководить решениями об операции, восстановлении или долгосрочном уходе. Авторы утверждают, что более безопасное использование потребует моделей, адаптированных к бариатрической медицине, основанных на надёжных доказательствах и разработанных с постоянным участием хирургов, врачей, диетологов и медсестёр. При тщательной разработке и строгом контроле эти инструменты в перспективе могут поддерживать более информированные обсуждения между пациентами и их медицинскими командами, а не заменять их.
Цитирование: Cai, J., Chen, J., Yu, T. et al. Multidisciplinary expert evaluation of large language models on questions regarding bariatric surgery: a comparative analysis of ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro. Sci Rep 16, 16043 (2026). https://doi.org/10.1038/s41598-026-46766-6
Ключевые слова: бариатрическая хирургия, операция по снижению веса, медицинские чатботы, крупные языковые модели, образование пациентов