Clear Sky Science · de
Multidisziplinäre Expertenbewertung großer Sprachmodelle zu Fragen der bariatrischen Chirurgie: eine vergleichende Analyse von ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus und Gemini Pro
Warum das für Menschen, die eine Gewichtsverlustoperation in Erwägung ziehen, wichtig ist
Menschen, die über eine Gewichtsverlustoperation nachdenken, wenden sich häufig an Online‑Hilfen und Chatbots, um schnelle Antworten zu bekommen. Diese Studie stellt eine einfache, aber wichtige Frage: Wie genau und vollständig sind die Antworten großer Sprachmodell‑Chatbots auf häufige Fragen zur bariatrischen Chirurgie, und können sie Patienten und Kliniker wirklich unterstützen?
Moderne Chatbots auf dem Weg in die Klinik
Die Forschenden untersuchten vier weit verbreitete Chatbots auf Basis großer Sprachmodelle: ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus und Gemini Pro. Sie konzentrierten sich auf praxisnahe Fragen zur bariatrischen Chirurgie, etwa wer dafür infrage kommt, wie man sich vorbereitet, welche Risiken zu erwarten sind und welche Lebensstiländerungen danach erforderlich sind. Aus einem anfänglichen Pool von 200 Fragen, gesammelt aus medizinischer Literatur, sozialen Medien und Klinikbesuchen, wählten sie 50 aus, die die Anliegen von Patientinnen und Patienten am besten repräsentierten. Jeder Chatbot beantwortete alle 50 Fragen, womit 200 Antworten entstanden, die anschließend für die Begutachtung übersetzt und standardisiert wurden.
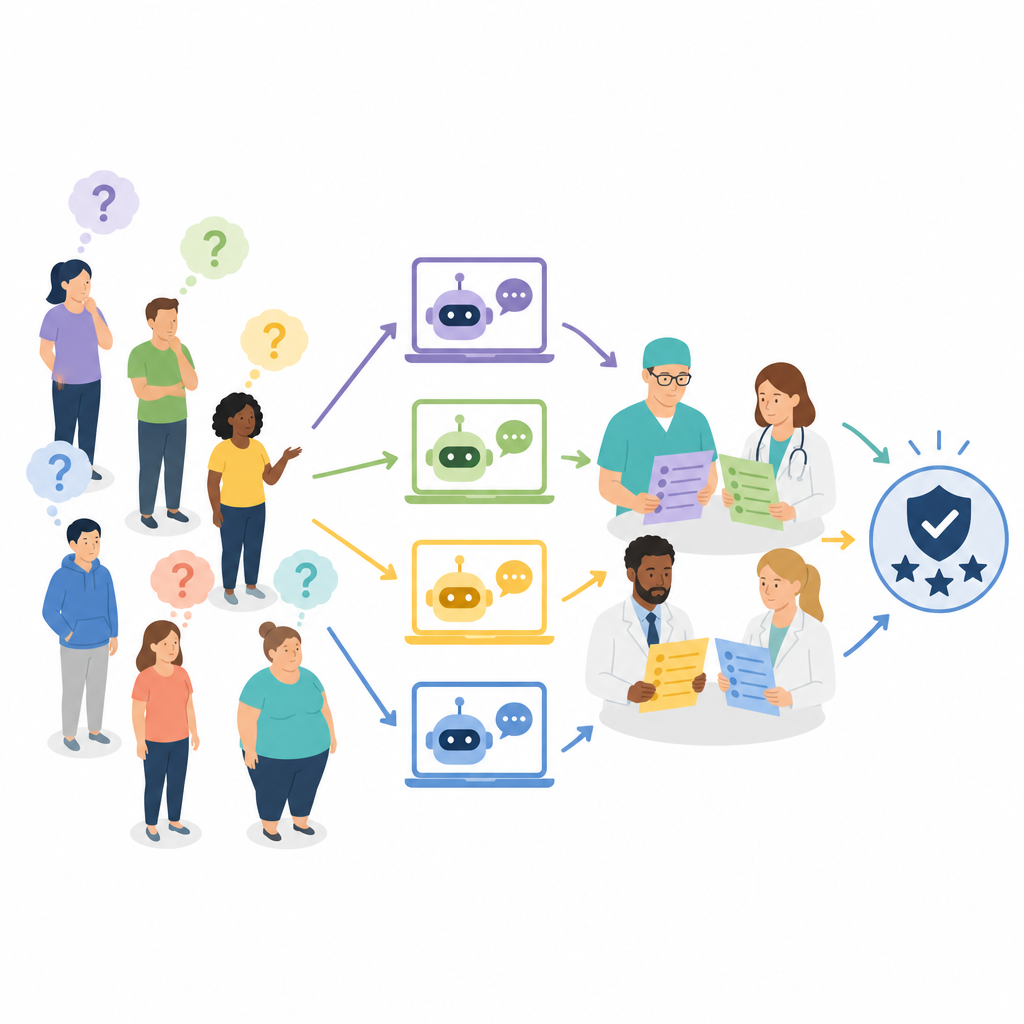
Viele Expertinnen und Experten, nicht nur eine Sichtweise
Statt nur Chirurgen die Antworten bewerten zu lassen, stellte das Team ein multidisziplinäres Gremium aus sieben erfahrenen Fachpersonen zusammen: vier bariatrische Chirurgen, eine Adipositasärztin bzw. ein Adipositasarzt und zwei Diätassistentinnen/Diätassistenten. Jede Expertin und jeder Experte beurteilte unabhängig, wie korrekt jede Antwort war und, bei den besseren Antworten, wie gründlich sie war. Die Genauigkeit wurde auf einer dreistufigen Skala bewertet, die von eindeutig falsch und potenziell schädlich bis hin zu vollständig korrekt reichte. Die Vollständigkeit wurde auf einer fünfstufigen Skala bewertet, die widerspiegelte, wie gut eine Antwort zentrale Punkte wie Verfahrensdetails, Risiken und Nachsorge abdeckte. Der Bewertungsprozess war verblindet, so dass die Gutachter nicht wussten, welcher Chatbot welche Antwort geliefert hatte; die Antworten wurden durchmischt und über mehrere Sitzungen verteilt, um Verzerrungen zu verringern.
Wie die Chatbots abschnitten
Insgesamt zeigten die vier Chatbots gemischte Ergebnisse. ERNIE Bot 4.0 erzielte die höchste durchschnittliche Genauigkeitswertung, wenn alle Expert*innenbewertungen zusammengefasst wurden, während ChatGPT-4 den höchsten Anteil an als „gut“ bewerteten Antworten hatte und keine schlechten Bewertungen erhielt. Claude 3 Opus neigte dazu, die längsten und detailliertesten Antworten zu geben, während Gemini Pro deutlich in der Genauigkeit zurückblieb: Weniger als die Hälfte seiner Antworten wurde als gut bewertet und mehrere Antworten wurden von den meisten Gutachtern als schlecht eingestuft. Alle Chatbots hatten Schwierigkeiten, Themen vollständig abzudecken: Selbst die besseren Antworten erreichten meist nur ein mittleres Detailniveau, und keiner bot durchgängig die Tiefe, die für vollständig informierte Entscheidungen über eine Operation erforderlich wäre.
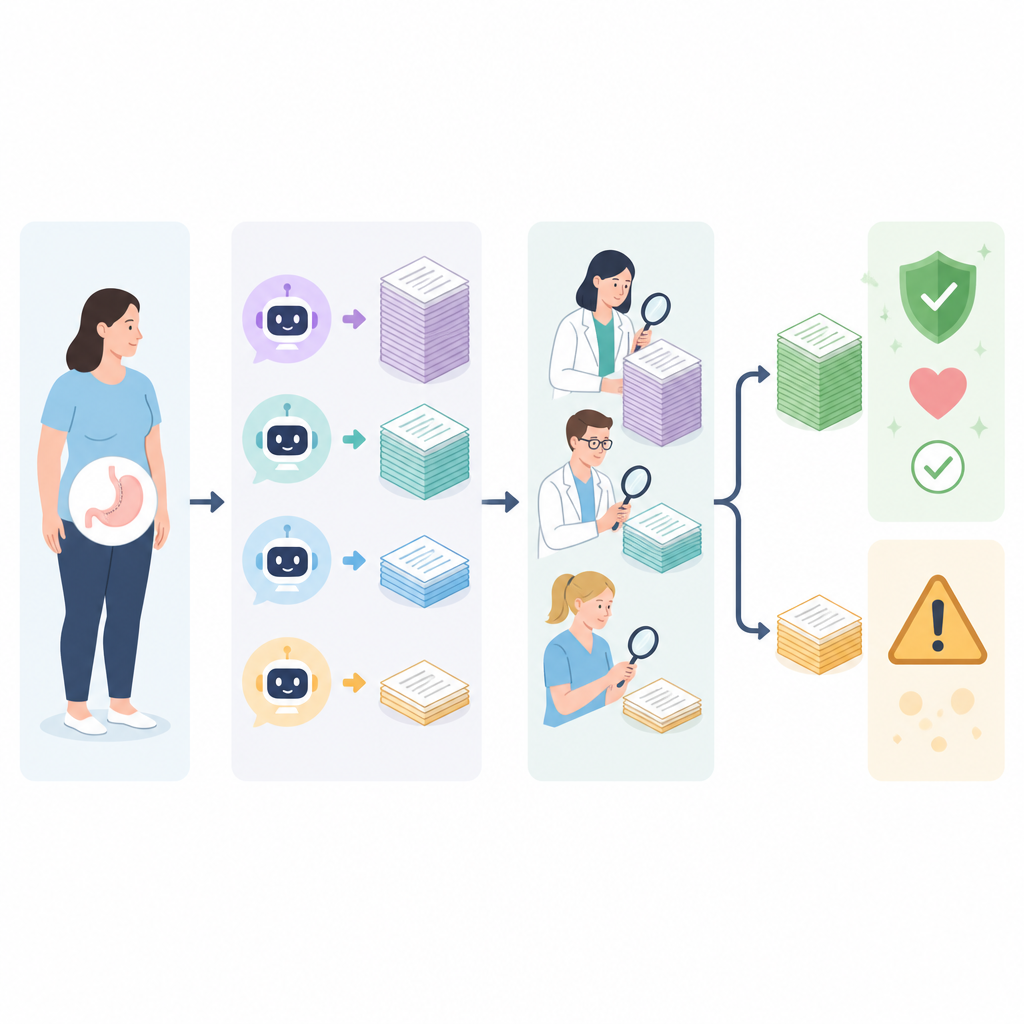
Wo die Antworten Lücken haben
Am schwächsten waren die Chatbots bei Erklärungen zur Erholungsphase, zu Risiken und zu Komplikationen. Diese Themen beinhalten häufig subtile Abwägungen und langfristige Nachsorge, die die Tools zu vereinfachen tendierten. Einige Antworten weckten unrealistische Erwartungen hinsichtlich des Gewichtsverlusts oder ließen wichtige Sicherheitsinformationen aus, während andere Ratschläge zu allgemein waren, um für reale Patientinnen und Patienten nützlich zu sein. Als die Expertinnen und Experten die Chatbots baten, ihre schlechtesten Antworten zu überprüfen und zu korrigieren, verbesserten sich die meisten Tools spürbar, besonders wenn sie aufgefordert wurden, evidenzbasierte Quellen online zu prüfen. Dennoch blieben selbst mit Selbstkorrektur und Websuche einige Antworten bestimmter Modelle ungenau, was zeigt, dass Internetzugang allein keine verlässliche medizinische Beratung garantiert.
Was das für Patientinnen, Patienten und Kliniker bedeutet
Derzeit legt die Studie nahe, dass Chatbots auf Basis großer Sprachmodelle als pädagogische Hilfsmittel zur bariatrischen Chirurgie nützlich sein können, insbesondere für Basisfragen und frühe Informationssuche. Sie sind jedoch nicht bereit, professionelle Beratung zu ersetzen oder eigenständig Entscheidungen über Operationen, Erholung oder Langzeitversorgung zu treffen. Die Autorinnen und Autoren plädieren dafür, dass sichere Nutzung spezialisierte Modelle erfordert, die auf bariatrischer Medizin beruhen, auf soliden Evidenzen aufbauen und mit kontinuierlichem Input von Chirurgen, Ärztinnen und Ärzten, Diätassistentinnen/Diätassistenten und Pflegenden entwickelt werden. Mit sorgfältigem Design und strenger Aufsicht könnten diese Werkzeuge letztlich dazu beitragen, besser informierte Gespräche zwischen Patientinnen, Patienten und ihren Behandlungsteams zu unterstützen, statt sie zu ersetzen.
Zitation: Cai, J., Chen, J., Yu, T. et al. Multidisciplinary expert evaluation of large language models on questions regarding bariatric surgery: a comparative analysis of ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro. Sci Rep 16, 16043 (2026). https://doi.org/10.1038/s41598-026-46766-6
Schlüsselwörter: bariatrische Chirurgie, Gewichtsverlustchirurgie, medizinische Chatbots, große Sprachmodelle, Patientenaufklärung