Clear Sky Science · fr
Évaluation multidisciplinaire d’experts des grands modèles linguistiques sur des questions concernant la chirurgie bariatrique : analyse comparative d’ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus et Gemini Pro
Pourquoi cela compte pour les personnes qui envisagent une chirurgie de perte de poids
Les personnes qui envisagent une chirurgie de perte de poids se tournent souvent vers des outils en ligne et des chatbots pour obtenir des réponses rapides. Cette étude pose une question simple mais importante : lorsque des chatbots basés sur de grands modèles linguistiques répondent aux questions courantes sur la chirurgie bariatrique, dans quelle mesure leurs réponses sont-elles exactes et complètes, et peuvent-elles véritablement soutenir les patients et les cliniciens ?
Des chatbots modernes qui entrent dans la sphère clinique
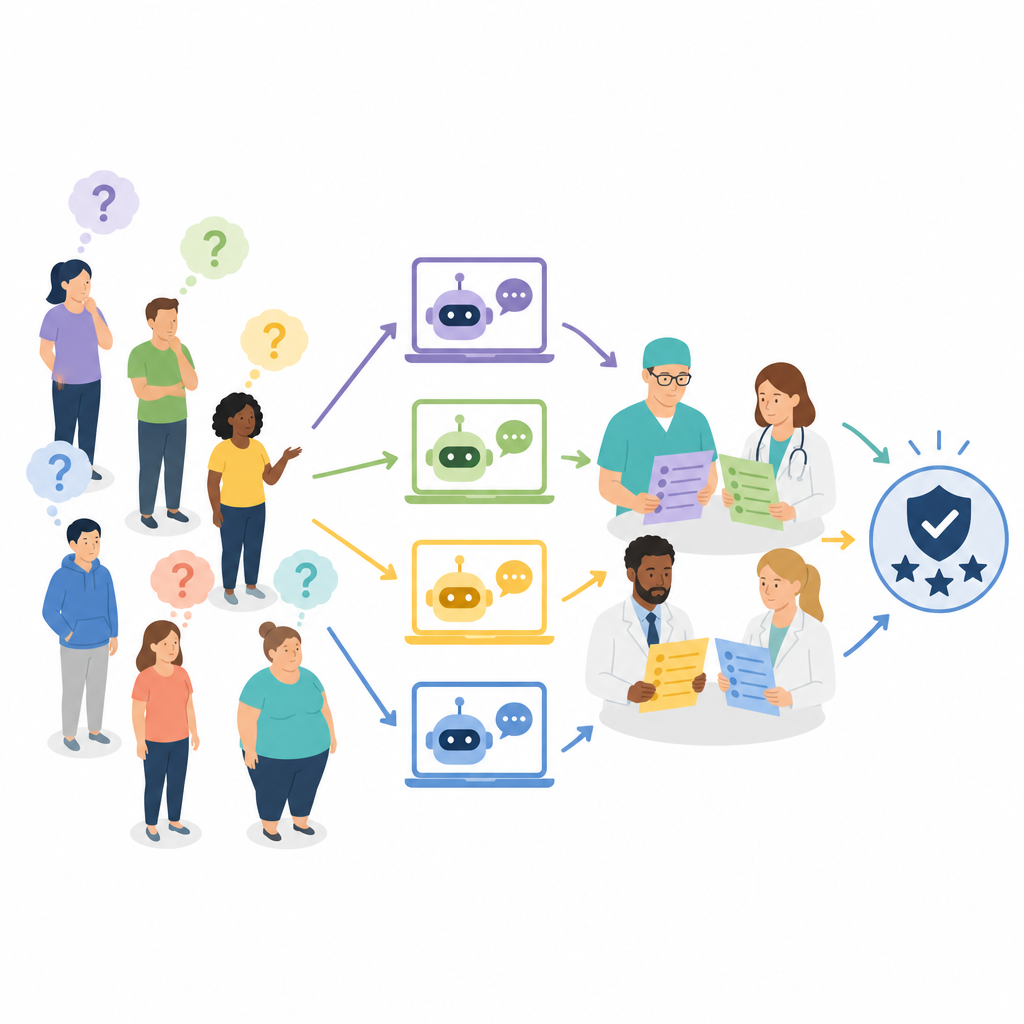
Les chercheurs ont examiné quatre chatbots largement utilisés fondés sur de grands modèles linguistiques : ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus et Gemini Pro. Ils se sont concentrés sur des questions concrètes portant sur la chirurgie bariatrique, comme qui est éligible, comment se préparer, quels risques attendre et quels changements de mode de vie sont nécessaires par la suite. À partir d’un ensemble initial de 200 questions recueillies dans la littérature médicale, sur les réseaux sociaux et lors de consultations, ils ont sélectionné 50 questions représentant le mieux les préoccupations des patients. Chaque chatbot a répondu aux 50 questions, produisant 200 réponses au total qui ont ensuite été traduites et normalisées pour l’examen.
De nombreux experts, pas un seul point de vue
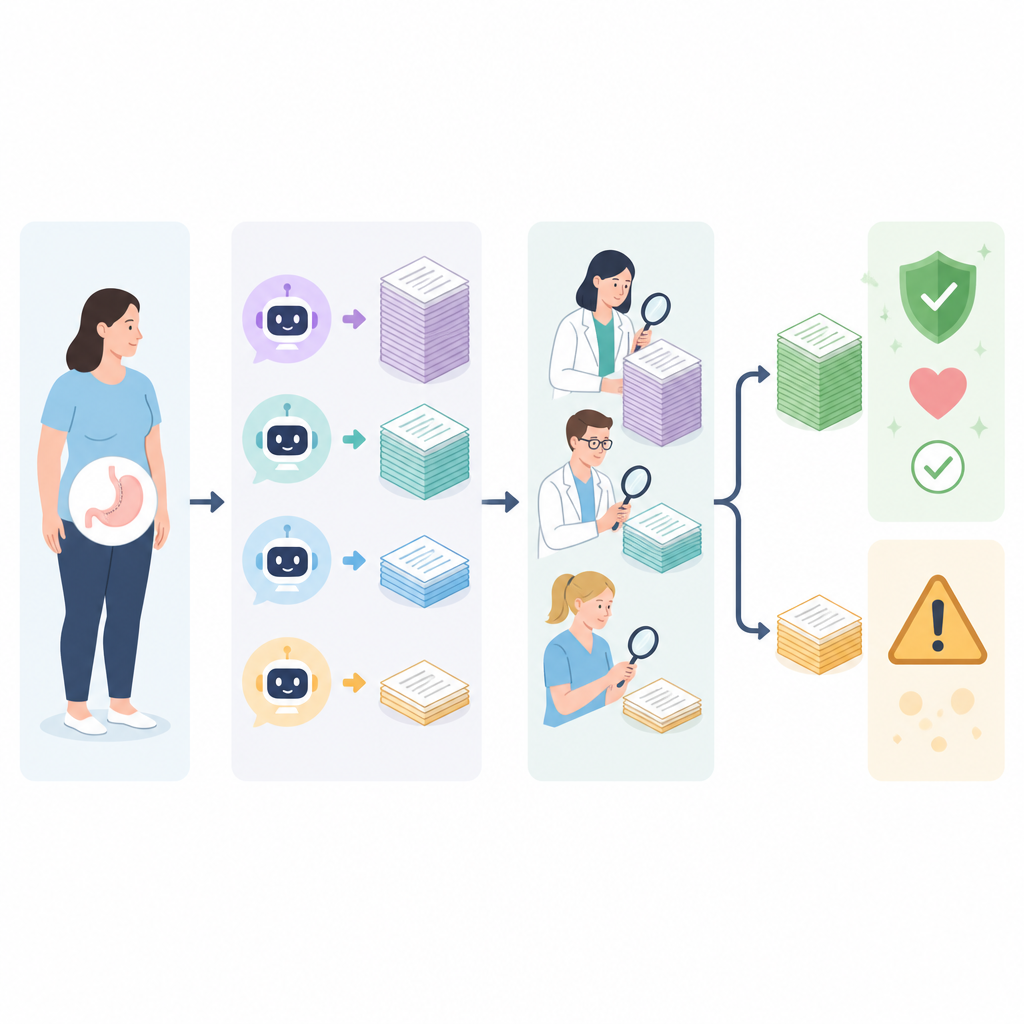
Plutôt que de ne demander qu’à des chirurgiens de juger les réponses, l’équipe a constitué un panel multidisciplinaire de sept professionnels expérimentés : quatre chirurgiens bariatriques, un médecin spécialisé en obésité et deux diététiciennes. Chaque expert a évalué de manière indépendante la précision de chaque réponse et, pour les meilleures réponses, leur exhaustivité. La précision a été notée sur une échelle en trois niveaux allant de clairement erronée et potentiellement nocive à entièrement correcte. L’exhaustivité a été notée sur une échelle en cinq niveaux reflétant à quel point une réponse couvrait des points clés tels que les détails de la procédure, les risques et le suivi. Le processus de notation était en aveugle pour que les évaluateurs ne sachent pas quel chatbot avait produit quelle réponse, et les réponses ont été mélangées et réparties sur plusieurs sessions pour réduire les biais.
Performance des chatbots
Globalement, les quatre chatbots ont montré des résultats mitigés. ERNIE Bot 4.0 a obtenu le score moyen de précision le plus élevé lorsque l’on a additionné toutes les notes des experts, mais ChatGPT-4 a obtenu la plus grande part de réponses jugées simplement « bonnes », et il n’a reçu aucune note « pauvre ». Claude 3 Opus avait tendance à fournir les réponses les plus longues et les plus détaillées, tandis que Gemini Pro était nettement en retrait en termes de précision, avec moins de la moitié de ses réponses notées comme bonnes et plusieurs jugées pauvres par la plupart des évaluateurs. Tous les chatbots ont eu des difficultés à couvrir complètement les sujets : même les réponses les mieux notées atteignaient généralement seulement un niveau de détail modéré, et aucune n’a offert de façon constante la profondeur nécessaire aux décisions pleinement éclairées concernant une chirurgie.
Les limites des réponses
Le point le plus faible pour chaque chatbot concernait l’explication de la récupération, des risques et des complications. Ces sujets impliquent souvent des arbitrages subtils et un suivi à long terme, que les outils ont tendance à simplifier excessivement. Certaines réponses ont donné des attentes irréalistes concernant la perte de poids ou omis des informations de sécurité importantes, tandis que d’autres proposaient des conseils trop génériques pour être utiles aux patients réels. Lorsque les experts ont demandé aux chatbots de revoir et corriger leurs pires réponses, la plupart des outils se sont nettement améliorés, en particulier lorsqu’on leur a demandé de vérifier des sources fondées sur des preuves en ligne. Cependant, même avec l’auto-correction et la recherche web, certaines réponses de certains modèles sont restées inexactes, montrant que l’accès à Internet seul ne garantit pas des conseils médicaux fiables.
Ce que cela signifie pour les patients et les cliniciens
Pour l’instant, l’étude suggère que les chatbots basés sur de grands modèles linguistiques peuvent être utiles comme outils pédagogiques pour la chirurgie bariatrique, en particulier pour les questions de base et la recherche d’information préliminaire. Ils ne sont pas prêts à remplacer les conseils professionnels ni à guider seuls les décisions relatives à la chirurgie, à la récupération ou aux soins à long terme. Les auteurs soutiennent qu’une utilisation plus sûre nécessitera des modèles adaptés à la médecine bariatrique, fondés sur des preuves solides et développés avec la participation continue de chirurgiens, de médecins, de diététiciens et d’infirmiers. Avec une conception attentive et une supervision stricte, ces outils pourraient à terme soutenir des conversations mieux informées entre patients et équipes de soins plutôt que de se substituer à elles.
Citation: Cai, J., Chen, J., Yu, T. et al. Multidisciplinary expert evaluation of large language models on questions regarding bariatric surgery: a comparative analysis of ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro. Sci Rep 16, 16043 (2026). https://doi.org/10.1038/s41598-026-46766-6
Mots-clés: chirurgie bariatrique, chirurgie de perte de poids, chatbots médicaux, grands modèles linguistiques, éducation des patients