Clear Sky Science · ar
تقييم خبراء متعدد التخصصات لنماذج اللغة الكبيرة بشأن أسئلة حول جراحة السمنة: تحليل مقارن لِـ ERNIE Bot 4.0 و ChatGPT-4 و Claude 3 Opus و Gemini Pro
لماذا يهم هذا الأشخاص الذين يفكرون في جراحة إنقاص الوزن
غالبًا ما يلجأ الأشخاص الذين يفكرون في جراحة إنقاص الوزن إلى أدوات ومحادثات على الإنترنت للحصول على إجابات سريعة. تطرح هذه الدراسة سؤالًا بسيطًا لكنه مهمًا: عندما ترد روبوتات المحادثة المبنية على نماذج اللغة الكبيرة على الأسئلة الشائعة حول جراحة السمنة، ما مدى دقة وإتمامية إجاباتها، وهل يمكنها بالفعل دعم المرضى والأطباء؟
روبوتات المحادثة الحديثة تدخل العيادة
فحص الباحثون أربعة روبوتات محادثة مستخدمة على نطاق واسع تعتمد على نماذج لغة كبيرة: ERNIE Bot 4.0 و ChatGPT-4 و Claude 3 Opus و Gemini Pro. ركزوا على أسئلة واقعية حول جراحة السمنة، مثل من هو المؤهل لها، كيف يستعد المريض، ما المخاطر المتوقعة، وما التغييرات في نمط الحياة المطلوبة بعد الجراحة. من مجموعة أولية مكونة من 200 سؤال جمعت من الأدبيات الطبية ووسائل التواصل الاجتماعي وزيارات العيادة، اختاروا 50 سؤالًا تمثّل قلق المرضى بأفضل شكل. أجابت كل روبوتات المحادثة على جميع الأسئلة الخمسين، فنتج 200 إجابة تمت ترجمتها وتوحيدها للمراجعة.
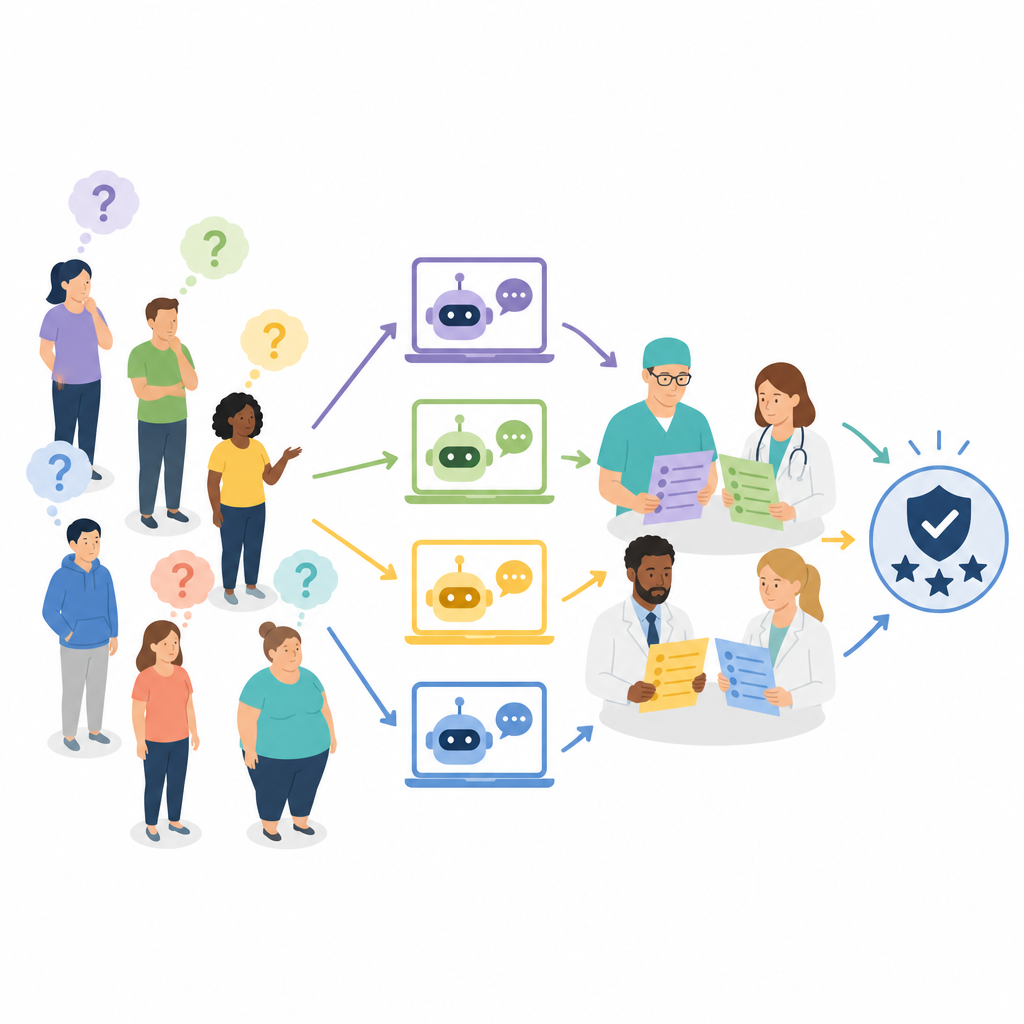
خبراء متعددون، لا وجهة نظر واحدة فقط
بدلاً من طلب حكم الجراحين فقط على الإجابات، شكّل الفريق لجنة متعددة التخصصات مكوّنة من سبعة مهنيين متمرسين: أربعة جراحي سمنة، وطبيب واحد متخصص في السمنة، وأخصائيان تغذية. قام كل خبير بتقييم دقة كل إجابة بشكل مستقل، وللإجابات الأفضل قيّموا أيضًا مدى شموليتها. تم احتساب الدقة على مقياس ثلاثي يتدرج من خطأ واضح ومحتمل الضرر إلى صحيح تمامًا. وسُجِّلت الشمولية على مقياس من خمس درجات يعكس مدى تغطية الإجابة للنقاط الأساسية مثل تفاصيل الإجراء والمخاطر والمتابعة. كانت عملية التقييم عمياء بحيث لم يعرف المقيّمون أي روبوت أنتج أي إجابة، وتم خلط الإجابات وتوزيعها على جلسات متعددة لتقليل التحيز.
كيف أدت روبوتات المحادثة
بشكل عام، أظهرت الروبوتات الأربعة نتائج متباينة. سجل ERNIE Bot 4.0 أعلى متوسط درجات دقة عند جمع تقييمات الخبراء كلها، لكن ChatGPT-4 كان له أعلى نسبة من الإجابات المصنفة ببساطة على أنها جيدة، ولم يتلقَّ أي تقييمات ضعيفة على الإطلاق. ميّزت إجابات Claude 3 Opus بالطول والتفصيل الأعلى، في حين تأخرت Gemini Pro كثيرًا في الدقة، إذ كانت أقل من نصف إجاباتها مصنفة كجيدة وتلقّت عدة إجابات تقييمات ضعيفة من معظم المراجعين. كل الروبوتات واجهت صعوبة في توفير تغطية كاملة للمواضيع: حتى الإجابات الأفضل نادرًا ما وصلت إلى مستويات تفاصيل متقدمة، ولم تقدم أي منها باستمرار العمق الذي يحتاجه الناس لاتخاذ قرارات مستنيرة تمامًا بشأن الجراحة.
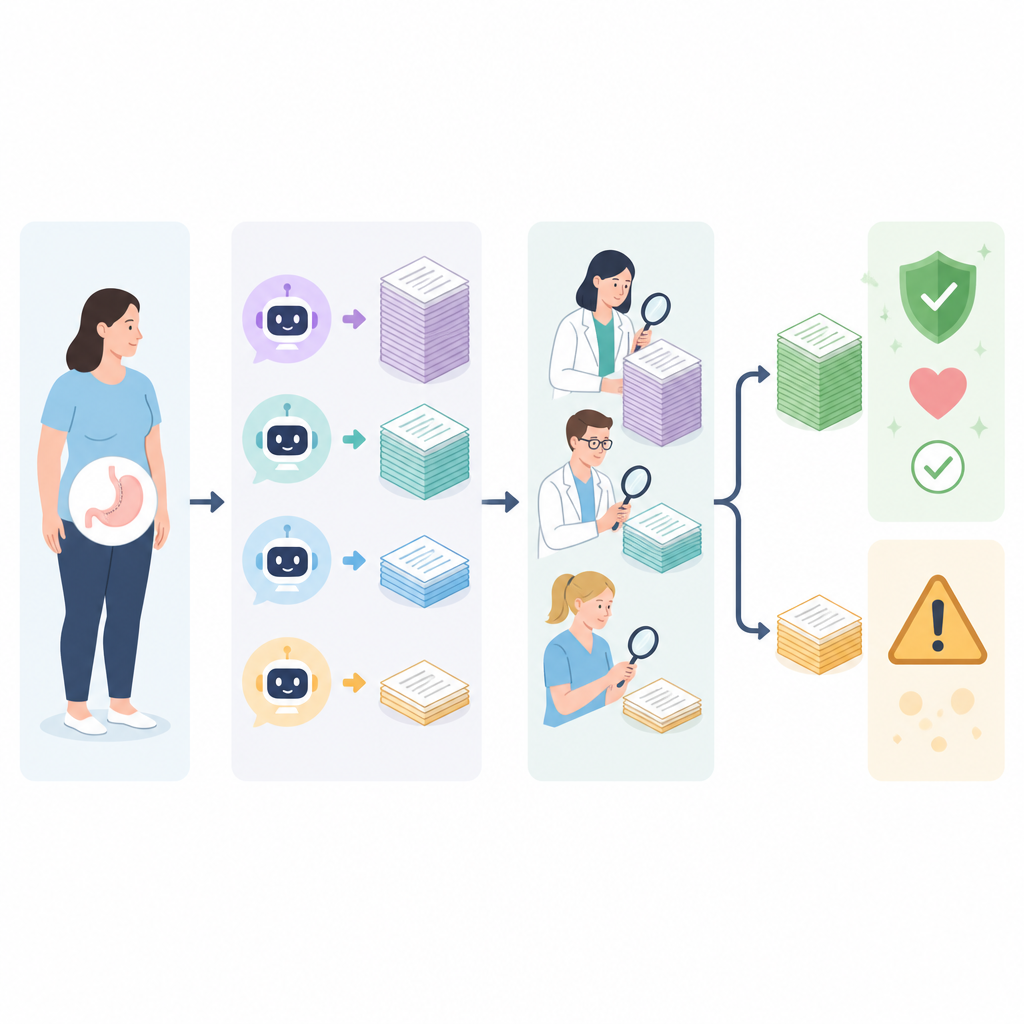
أين تقصر الإجابات
كان أضعف مجال لدى كل روبوت شرح التعافي والمخاطر والمضاعفات. غالبًا ما تنطوي هذه الموضوعات على مفاضلات دقيقة ومتابعة طويلة الأمد، والتي ميّلت الأدوات إلى تبسيطها بشكل مفرط. قدمت بعض الإجابات توقعات غير واقعية حول فقدان الوزن أو أغفلت معلومات سلامة مهمة، بينما قدمت أخرى نصائح عامة جدًا غير مفيدة للمرضى الفعليين. عندما طلب الخبراء من الروبوتات مراجعة وتصحيح أسوأ إجاباتها، تحسنت معظم الأدوات بشكل ملحوظ، خصوصًا عند مطالبتها بالتحقق من مصادر قائمة على الأدلة عبر الإنترنت. ومع ذلك، حتى مع التصحيح الذاتي والبحث على الويب، بقيت بعض الإجابات من نماذج معينة غير دقيقة، مما يبيّن أن الوصول إلى الإنترنت وحده لا يضمن إرشادًا طبيًا موثوقًا.
ماذا يعني هذا للمرضى والأطباء
حتى الآن، توحي الدراسة بأن روبوتات المحادثة المبنية على نماذج اللغة الكبيرة يمكن أن تكون مفيدة كمساعدات تعليمية حول جراحة السمنة، خاصة للأسئلة الأساسية والبحث الأولي عن المعلومات. لكنها غير جاهزة لاستبدال النصيحة المهنية أو لتوجيه قرارات بشأن الجراحة أو التعافي أو الرعاية الطويلة الأمد بمفردها. ويجادل المؤلفون بأن الاستخدام الأكثر أمانًا سيتطلب نماذج مخصّصة لطب السمنة، مبنية على أدلة قوية، ومُطوَّرة بمشاركة مستمرة من الجراحين والأطباء وأخصائيي التغذية والممرضين. مع تصميم دقيق وإشراف صارم، قد تدعم هذه الأدوات في النهاية محادثات أكثر اطلاعًا بين المرضى وفرق الرعاية بدلًا من أن تحل محلها.
الاستشهاد: Cai, J., Chen, J., Yu, T. et al. Multidisciplinary expert evaluation of large language models on questions regarding bariatric surgery: a comparative analysis of ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro. Sci Rep 16, 16043 (2026). https://doi.org/10.1038/s41598-026-46766-6
الكلمات المفتاحية: جراحة السمنة, جراحة إنقاص الوزن, روبوتات المحادثة الطبية, نماذج اللغة الكبيرة, تثقيف المرضى