Clear Sky Science · en
Multidisciplinary expert evaluation of large language models on questions regarding bariatric surgery: a comparative analysis of ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro
Why this matters for people considering weight loss surgery
People who are thinking about weight loss surgery often turn to online tools and chatbots for quick answers. This study asks a simple but important question: when large language model chatbots answer common questions about bariatric surgery, how accurate and complete are their replies, and can they truly support patients and clinicians?
Modern chatbots stepping into the clinic
The researchers examined four widely used chatbots based on large language models: ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro. They focused on real-world questions about bariatric surgery, such as who is eligible, how to prepare, what risks to expect, and what lifestyle changes are needed afterward. From an initial pool of 200 questions collected from medical literature, social media, and clinic visits, they selected 50 that best represented the concerns of patients. Each chatbot answered all 50 questions, producing 200 responses in total that were then translated and standardized for review.
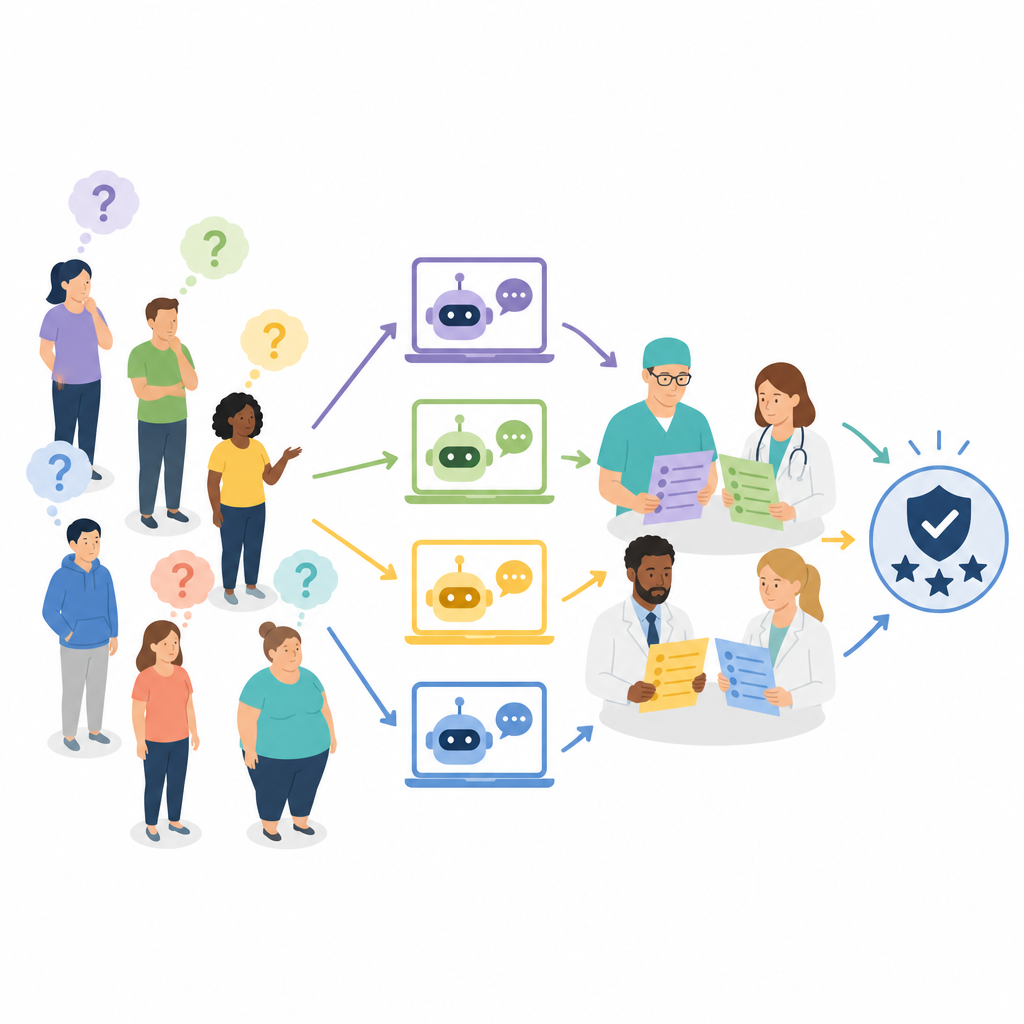
Many experts, not just one point of view
Instead of asking only surgeons to judge the replies, the team assembled a multidisciplinary panel of seven seasoned professionals: four bariatric surgeons, one obesity physician, and two dietitians. Each expert independently rated how accurate each answer was and, for the better answers, how thorough it was. Accuracy was scored on a three-step scale ranging from clearly wrong and potentially harmful to fully correct. Comprehensiveness was scored on a five-step scale that reflected how well an answer covered key points such as procedure details, risks, and follow-up care. The grading process was blinded so that reviewers did not know which chatbot produced which answer, and responses were shuffled and spread across several sessions to reduce bias.
How the chatbots performed
Overall, the four chatbots showed mixed results. ERNIE Bot 4.0 achieved the highest average accuracy score when all expert ratings were added together, but ChatGPT-4 had the highest share of responses judged simply as good, and it did not receive any poor ratings at all. Claude 3 Opus tended to give the longest and most detailed answers, while Gemini Pro lagged far behind in accuracy, with fewer than half of its responses rated as good and several graded as poor by most reviewers. All of the chatbots struggled to provide complete coverage of topics: even the better answers usually reached only moderate levels of detail, and none consistently offered the kind of depth that people need for fully informed decisions about surgery.
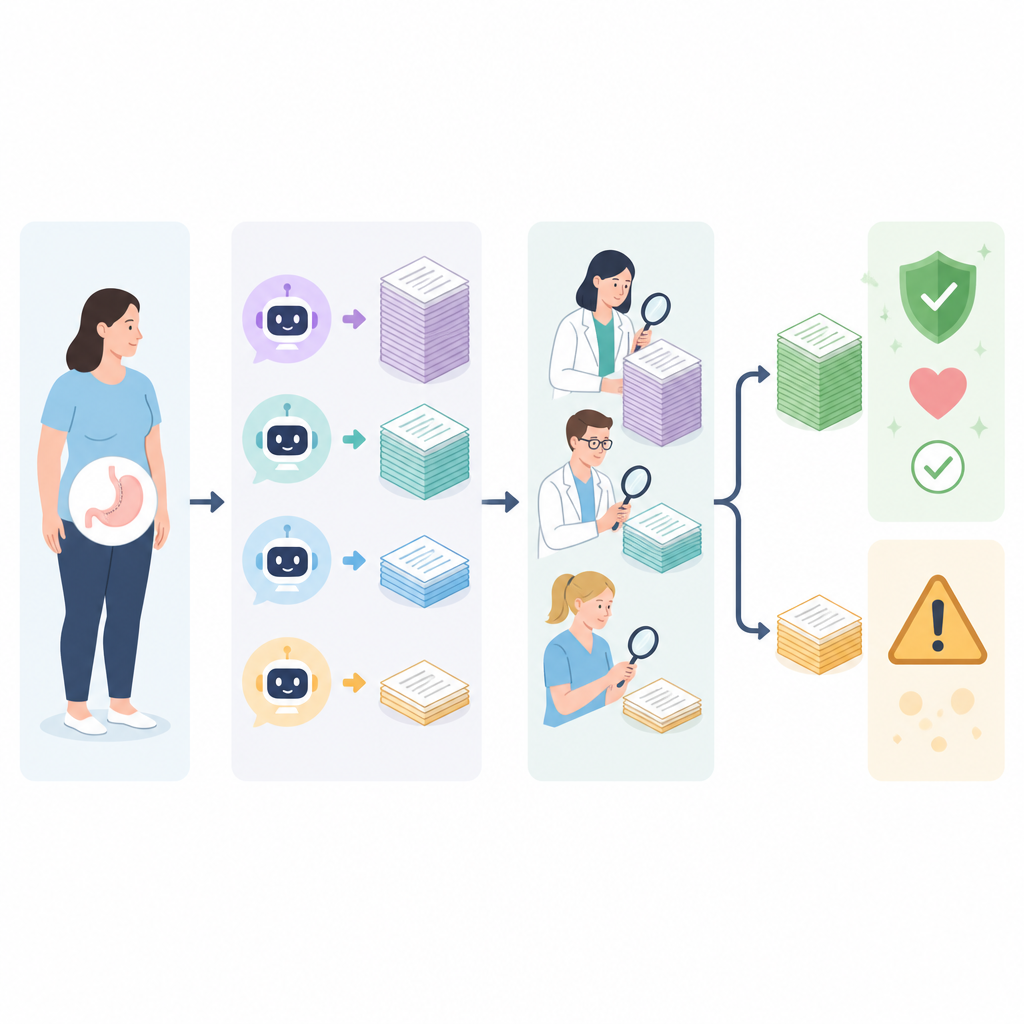
Where the answers fall short
The weakest area for every chatbot was explaining recovery, risks, and complications. These topics often involve subtle trade-offs and long-term follow-up, which the tools tended to oversimplify. Some replies gave unrealistic expectations about weight loss or left out important safety information, while others offered advice that was too generic to be useful for real patients. When the experts asked the chatbots to review and correct their poorest answers, most tools improved noticeably, especially when prompted to check evidence-based sources online. However, even with self-correction and web search, some responses from certain models remained inaccurate, showing that internet access alone does not guarantee reliable medical guidance.
What this means for patients and clinicians
For now, the study suggests that large language model chatbots can be helpful as educational aids for bariatric surgery, especially for basic questions and early information seeking. They are not ready to replace professional advice or to guide decisions about surgery, recovery, or long-term care on their own. The authors argue that safer use will require models that are tailored to bariatric medicine, built on solid evidence, and developed with ongoing input from surgeons, physicians, dietitians, and nurses. With careful design and strict oversight, these tools may eventually support more informed conversations between patients and their care teams rather than standing in for them.
Citation: Cai, J., Chen, J., Yu, T. et al. Multidisciplinary expert evaluation of large language models on questions regarding bariatric surgery: a comparative analysis of ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro. Sci Rep 16, 16043 (2026). https://doi.org/10.1038/s41598-026-46766-6
Keywords: bariatric surgery, weight loss surgery, medical chatbots, large language models, patient education