Clear Sky Science · sv
Multidisciplinär expertutvärdering av stora språkmodeller på frågor om bariatrisk kirurgi: en jämförande analys av ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus och Gemini Pro
Varför detta betyder något för personer som överväger viktminskningskirurgi
Personer som funderar på viktminskningskirurgi vänder sig ofta till onlineresurser och chattbotar för snabba svar. Denna studie ställer en enkel men viktig fråga: när chattbotar med stora språkmodeller svarar på vanliga frågor om bariatrisk kirurgi, hur korrekta och fullständiga är deras svar, och kan de verkligen stödja patienter och kliniker?
Moderna chattbotar som kliver in i kliniken
Forskarlaget granskade fyra allmänt använda chattbotar baserade på stora språkmodeller: ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus och Gemini Pro. De fokuserade på verkliga frågor om bariatrisk kirurgi, såsom vem som är berättigad, hur man förbereder sig, vilka risker man kan förvänta sig och vilka livsstilsförändringar som krävs efteråt. Från en initial samling på 200 frågor insamlade från medicinsk litteratur, sociala medier och klinikbesök valde de ut 50 som bäst representerade patienternas bekymmer. Varje chattbot svarade på alla 50 frågor, vilket gav totalt 200 svar som sedan översattes och standardiserades för granskning.
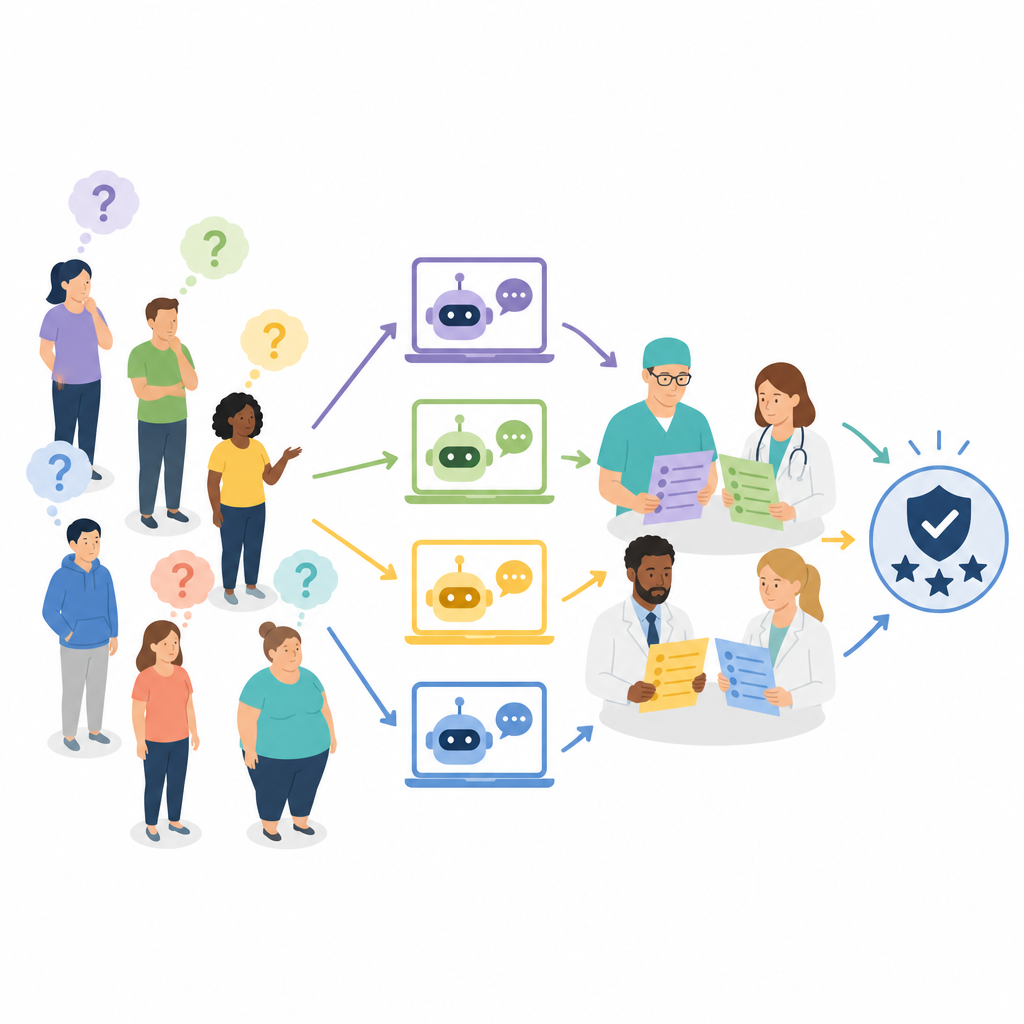
Många experter, inte bara ett perspektiv
I stället för att bara låta kirurger bedöma svaren samlade teamet en multidisciplinär panel av sju erfarna yrkespersoner: fyra bariatrikkirurger, en obesitasläkare och två dietister. Varje expert bedömde oberoende hur korrekt varje svar var och, för de bättre svaren, hur grundligt det var. Korrekthet poängsattes på en trestegs-skala från tydligt fel och potentiellt skadligt till fullt korrekt. Fullständighet poängsattes på en femstegs-skala som reflekterade hur väl ett svar täckte nyckelområden såsom procedurdetsljer, risker och uppföljningsvård. Bedömningsprocessen var blind så att granskare inte visste vilken chattbot som producerat vilket svar, och svaren blandades och fördelades över flera sessioner för att minska bias.
Hur chattbotarna presterade
Överlag visade de fyra chattbotarna blandade resultat. ERNIE Bot 4.0 uppnådde det högsta genomsnittliga korrekthetspoänget när alla experternas bedömningar räknades samman, men ChatGPT-4 hade den största andelen svar som bedömdes som bra, och den fick inga dåliga betyg alls. Claude 3 Opus tenderade att ge de längsta och mest detaljerade svaren, medan Gemini Pro halkade långt efter i korrekthet, med färre än hälften av sina svar bedömda som bra och flera som de flesta granskare satte som dåliga. Alla chattbotar hade svårt att erbjuda fullständig täckning av ämnen: även de bättre svaren nådde oftast bara måttliga detaljnivåer, och ingen erbjöd konsekvent den djupgående information som människor behöver för fullt informerade beslut om kirurgi.
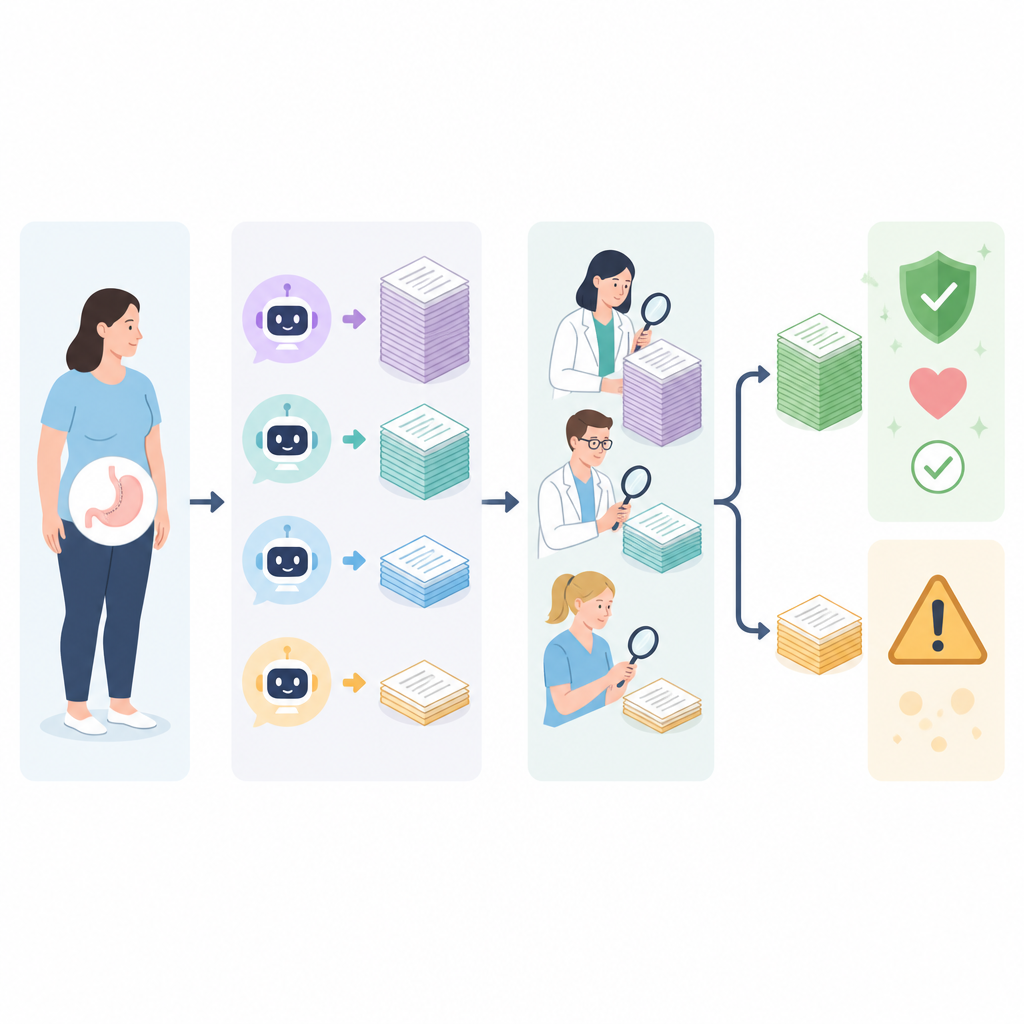
Var svaren brast
Det svagaste området för varje chattbot var förklaringar kring återhämtning, risker och komplikationer. Dessa ämnen involverar ofta subtila avvägningar och långsiktig uppföljning, vilket verktygen tenderade att förenkla. Vissa svar skapade orealistiska förväntningar kring viktminskning eller utelämnade viktig säkerhetsinformation, medan andra gav råd som var för generiska för att vara användbara för verkliga patienter. När experterna bad chattbotarna att granska och korrigera sina sämsta svar förbättrades de flesta verktyg märkbart, särskilt när de uppmanades att kontrollera evidensbaserade källor på nätet. Trots självkorrigering och webbsökning förblev dock vissa svar från vissa modeller felaktiga, vilket visar att internetåtkomst ensam inte garanterar pålitlig medicinsk vägledning.
Vad detta betyder för patienter och kliniker
För närvarande antyder studien att chattbotar med stora språkmodeller kan vara hjälpsamma som pedagogiska hjälpmedel för bariatrisk kirurgi, särskilt för grundläggande frågor och inledande informationssökning. De är inte redo att ersätta professionell rådgivning eller ensamma styra beslut om kirurgi, återhämtning eller långtidsvård. Författarna menar att säkrare användning kräver modeller som är anpassade till bariatrisk medicin, byggda på solid evidens och utvecklade med löpande insyn och bidrag från kirurger, läkare, dietister och sjuksköterskor. Med omsorgsfull utformning och strikt tillsyn kan dessa verktyg så småningom stödja mer informerade samtal mellan patienter och deras vårdteam snarare än att ersätta dem.
Citering: Cai, J., Chen, J., Yu, T. et al. Multidisciplinary expert evaluation of large language models on questions regarding bariatric surgery: a comparative analysis of ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro. Sci Rep 16, 16043 (2026). https://doi.org/10.1038/s41598-026-46766-6
Nyckelord: bariatrisk kirurgi, viktminskningskirurgi, medicinska chattbotar, stora språkmodeller, patientutbildning