Clear Sky Science · nl
Multidisciplinaire deskundige evaluatie van grote taalmodellen bij vragen over bariatrische chirurgie: een vergelijkende analyse van ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus en Gemini Pro
Waarom dit belangrijk is voor mensen die een gewichtsverliesoperatie overwegen
Mensen die nadenken over een gewichtsverliesoperatie raadplegen vaak online hulpmiddelen en chatbots voor snelle antwoorden. Deze studie stelt een eenvoudige maar belangrijke vraag: hoe nauwkeurig en compleet zijn de antwoorden van grote taalmodel-chatbots op veelgestelde vragen over bariatrische chirurgie, en kunnen ze daadwerkelijk patiënten en zorgverleners ondersteunen?
Moderne chatbots stappen de kliniek binnen
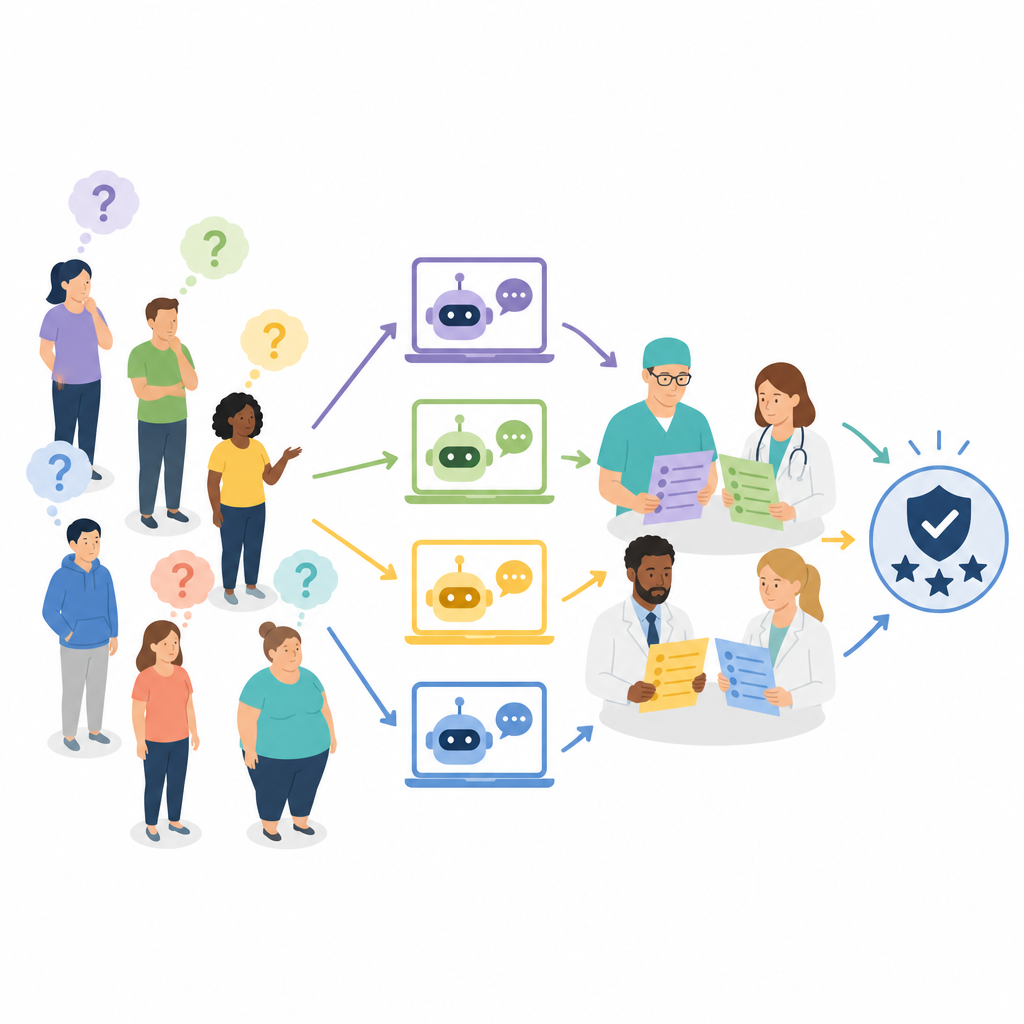
De onderzoekers bestudeerden vier veelgebruikte chatbots gebaseerd op grote taalmodellen: ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus en Gemini Pro. Ze richtten zich op praktijkvragen over bariatrische chirurgie, zoals wie in aanmerking komt, hoe men zich moet voorbereiden, welke risico’s te verwachten zijn en welke leefstijlveranderingen daarna nodig zijn. Uit een initiële verzameling van 200 vragen uit medische literatuur, sociale media en poliklinische bezoeken, selecteerden ze 50 die de zorgen van patiënten het beste weerspiegelden. Elke chatbot beantwoorde alle 50 vragen, wat in totaal 200 reacties opleverde die vervolgens werden vertaald en gestandaardiseerd voor beoordeling.
Veel experts, niet slechts één gezichtspunt
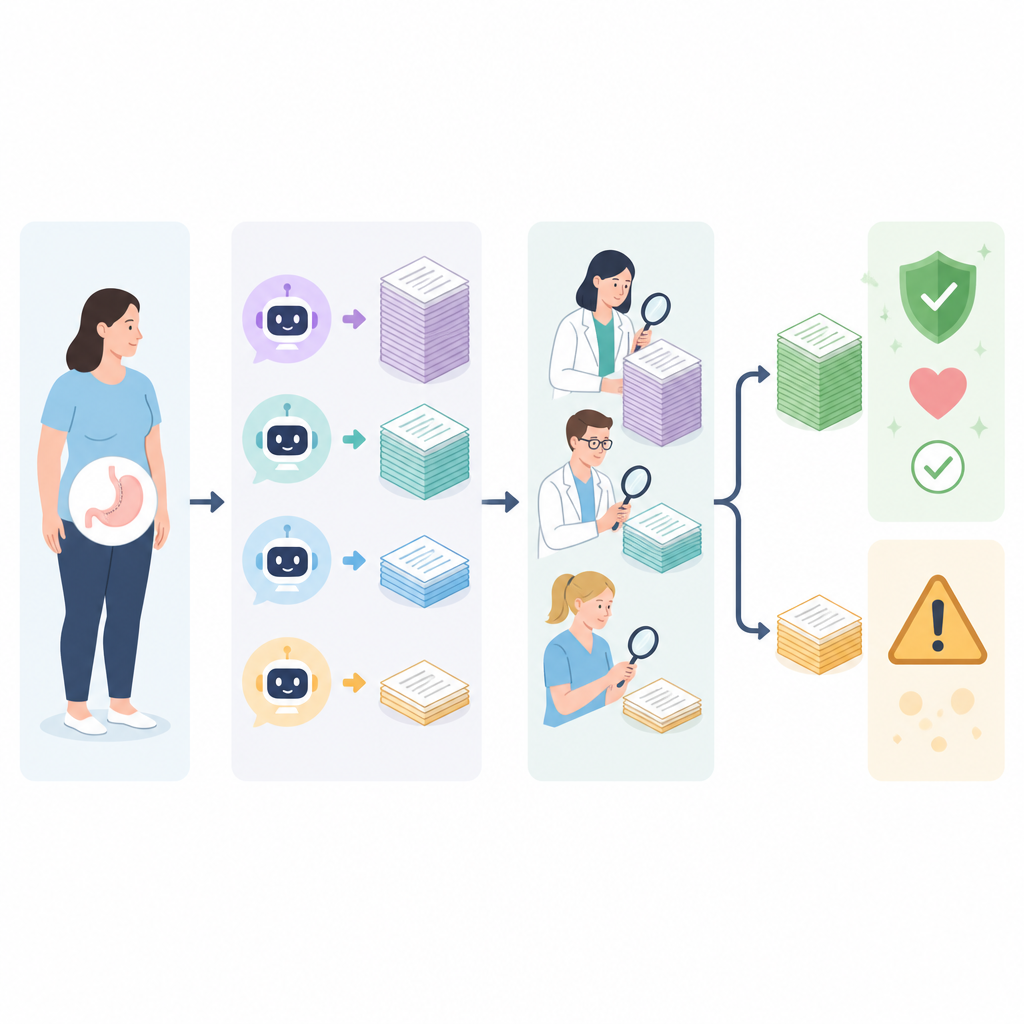
In plaats van alleen chirurgen de antwoorden te laten beoordelen, stelde het team een multidisciplinair panel van zeven ervaren professionals samen: vier bariatrische chirurgen, één obesitasarts en twee diëtisten. Elke expert beoordeelde onafhankelijk hoe nauwkeurig elk antwoord was en, bij de betere antwoorden, hoe grondig het was. Nauwkeurigheid werd beoordeeld op een driepuntschaal, variërend van duidelijk onjuist en potentieel schadelijk tot volledig correct. Volledigheid werd beoordeeld op een vijfpuntschaal die weerspiegelde hoe goed een antwoord belangrijke punten behandelde, zoals proceduredetails, risico’s en nazorg. Het beoordelingsproces was geblindeerd zodat beoordelaars niet wisten welke chatbot welk antwoord had geproduceerd, en de antwoorden werden gemixt en verspreid over meerdere sessies om bias te verminderen.
Hoe de chatbots presteerden
In het algemeen lieten de vier chatbots wisselende resultaten zien. ERNIE Bot 4.0 behaalde de hoogste gemiddelde nauwkeurigheidsscore wanneer alle expertbeoordelingen werden opgeteld, maar ChatGPT-4 had het grootste aandeel antwoorden dat simpelweg als goed werd beoordeeld en kreeg helemaal geen slechte beoordelingen. Claude 3 Opus neigde ertoe de langste en meest gedetailleerde antwoorden te geven, terwijl Gemini Pro ver achterbleef qua nauwkeurigheid, met minder dan de helft van zijn reacties beoordeeld als goed en meerdere antwoorden door de meeste beoordelaars als slecht bestempeld. Alle chatbots hadden moeite om onderwerpen volledig te dekken: zelfs de betere antwoorden bereikten meestal slechts een matig detailniveau, en geen enkele bood consequent de diepgang die mensen nodig hebben voor volledig geïnformeerde beslissingen over chirurgie.
Waar de antwoorden tekortschieten
Het zwakste gebied voor elke chatbot was het uitleggen van herstel, risico’s en complicaties. Deze onderwerpen omvatten vaak subtiele afwegingen en langdurige opvolging, die de tools de neiging hadden te simplificeren. Sommige reacties wekten onrealistische verwachtingen over gewichtsverlies of lieten belangrijke veiligheidsinformatie weg, terwijl andere adviezen te algemeen waren om nuttig te zijn voor echte patiënten. Toen de experts de chatbots vroegen hun slechtste antwoorden te herzien en te corrigeren, verbeterden de meeste tools merkbaar, vooral wanneer ze werden aangespoord bewijsgebaseerde bronnen online te controleren. Zelfs met zelfcorrectie en websearch bleven sommige antwoorden van bepaalde modellen echter onjuist, wat aantoont dat alleen internettoegang geen betrouwbare medische richtlijn garandeert.
Wat dit betekent voor patiënten en zorgverleners
Voorlopig suggereert de studie dat grote taalmodel-chatbots nuttig kunnen zijn als educatieve hulpmiddelen bij bariatrische chirurgie, vooral voor basisvragen en vroegtijdige informatiebehoefte. Ze zijn nog niet klaar om professioneel advies te vervangen of zelfstandig beslissingen over operatie, herstel of langdurige zorg te leiden. De auteurs betogen dat veiliger gebruik vereist dat modellen worden afgestemd op bariatrische geneeskunde, gebaseerd zijn op solide bewijs en ontwikkeld worden met voortdurende input van chirurgen, artsen, diëtisten en verpleegkundigen. Met zorgvuldige opzet en strikte supervisie kunnen deze hulpmiddelen uiteindelijk beter geïnformeerde gesprekken tussen patiënten en hun zorgteams ondersteunen in plaats van deze te vervangen.
Bronvermelding: Cai, J., Chen, J., Yu, T. et al. Multidisciplinary expert evaluation of large language models on questions regarding bariatric surgery: a comparative analysis of ERNIE Bot 4.0, ChatGPT-4, Claude 3 Opus, and Gemini Pro. Sci Rep 16, 16043 (2026). https://doi.org/10.1038/s41598-026-46766-6
Trefwoorden: bariatrische chirurgie, gewichtsverliesoperatie, medische chatbots, grote taalmodellen, patiëntenvoorlichting