Clear Sky Science · zh
通过自适应高斯图像表示实现统一的时间序列分类框架
把复杂的时间信号变成图像
从心跳和脑电到股价和交通流量,我们的数字世界很多信息都以时间序列形式记录:随时间变化的数值。然而,这些纠结的流对计算机而言难以可靠分类,尤其当它们来自多个传感器或长度不一时。本文提出了一种将此类混乱信号转换为现代视觉模型可理解图像的方法,从而更容易构建可信的健康、金融和日常设备监测系统。 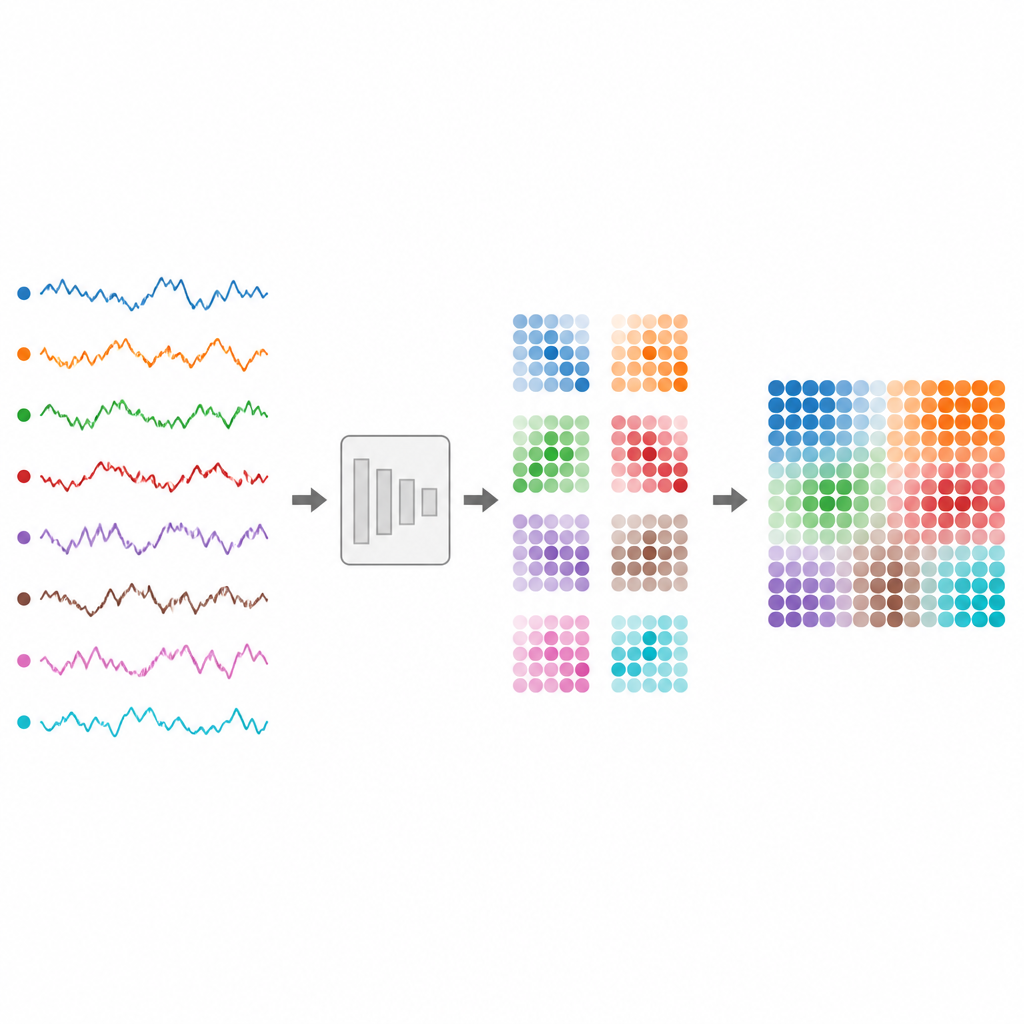
为什么时间序列如此难以分类
现实世界的时间序列很少表现得规整。不同传感器可能以不同速率记录、意外停止或开始,或产生噪声读数。有些应用只跟踪单一信号,例如心跳;而另一些则结合数十个通道,如运动、肌电和脑电。传统方法要么手工构造特征,要么使用直接作用于原始时间序列的深度学习模型。这些方法可以奏效,但常常难以在众多数据集间泛化,并且对每个新问题需要细致调参。
从一维波形到二维图像
作者提出了 TS2Vision 框架,将时间序列在分类前转换为图像。首先,对每个通道进行标准化并平滑地调整长度,以便短序列和长序列共享共同长度。然后,一种称为自适应时间序列高斯映射的自适应映射将时间上的每一时刻转换为图像内的一个小方块补丁。在该补丁内,为每个传感器通道分配一个圆形区域。根据信号当前值,在每个圆内绘制钟形(高斯)模式。该过程以既平滑又抗噪的方式捕捉局部的起伏。
把许多信号打包到单一视图中
一个关键挑战是如何布置这些圆形区域,使其不重叠同时在每个补丁有限空间内高效利用。作者将其视为圆形打包难题:如何在方形内紧密放置相等的圆。他们依赖几何研究中经验证的布局,为任意通道数安排圆的位置。这些布局预先固定,因此模型无需浪费计算去学习每个通道的位置。随着时间推进,补丁按顺序排列,形成更大的图像,该图像既保留了每个信号的变化,又保留了通道之间的关系。 
让视觉模型“读”时间
一旦时间序列被转换为图像,TS2Vision 将其输入视觉变换器(Vision Transformer),这是一类最初为图像识别设计的模型。该模型将图像切成更小的瓷砖,并使用注意力机制连接图像远端的模式,这里对应远端的时间步。作者在数学上证明了他们的映射具有稳定性:输入信号的小幅变化只会导致图像的有界变化,这有助于分类器在数据有噪声或传感器抖动时保持鲁棒性。
在众多真实数据集上的测试
为检验 TS2Vision 的实际效果,研究人员在来自两个主要存档的 158 个基准数据集上进行了测试。这些数据集覆盖广泛领域,包括设备读数、动作捕捉、医学记录、由图像转换而来的时间序列等。在单通道和多通道任务上,TS2Vision 在现代深度学习方法中取得了最佳平均排名,并在与领先的非深度学习技术比较时表现出竞争性的准确率,同时保持合理的训练时间。在加入人工噪声的鲁棒性测试中,其性能下降比竞争模型更平缓。
对日常系统的意义
简而言之,TS2Vision 表明将时间序列视为经精心设计的图像,可以为时序数据打开计算机视觉的优势。通过将一种稳定且自适应的信号绘制为图像的方法与强大的视觉模型相结合,该框架提供了一种统一方法,适用于多种传感器和序列长度。对于监测和决策系统的构建者而言,这意味着一个更通用的工具,能够处理多样且嘈杂的数据,同时在实际应用中保持足够的效率。
引用: Ren, X., Li, D., Gao, X. et al. A unified time series classification framework via adaptive Gaussian image representation. Sci Rep 16, 14817 (2026). https://doi.org/10.1038/s41598-026-44760-6
关键词: 时间序列分类, 图像表示, 视觉变换器, 多元传感器, 鲁棒编码