Clear Sky Science · pl
Jednolita ramowa klasyfikacja szeregów czasowych za pomocą adaptacyjnej reprezentacji obrazu Gaussa
Przekształcanie złożonych sygnałów czasowych w obrazy
Od rytmu serca i fal mózgowych po ceny akcji i przepływy ruchu — wiele elementów naszego świata cyfrowego jest zapisywane jako szeregi czasowe: liczby zmieniające się w czasie. Jednak te splecione strumienie są trudne do wiarygodnej klasyfikacji przez komputery, zwłaszcza gdy pochodzą z wielu czujników jednocześnie lub mają różną długość. Artykuł przedstawia sposób przekształcania takich nieuporządkowanych sygnałów w obrazy zrozumiałe dla nowoczesnych modeli wizji, co ułatwia budowanie niezawodnych systemów do monitorowania zdrowia, finansów i urządzeń codziennego użytku. 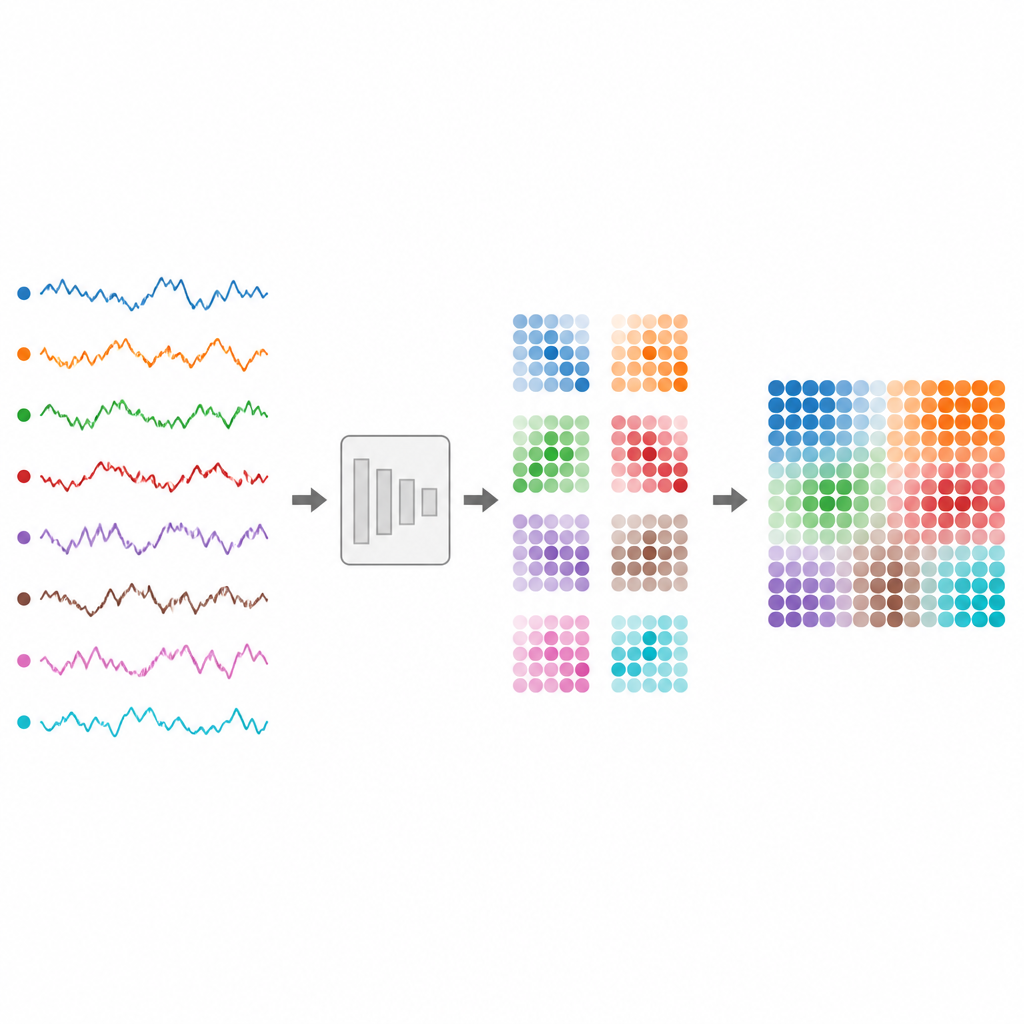
Dlaczego szeregi czasowe są trudne do klasyfikacji
Szeregi czasowe w świecie rzeczywistym rzadko zachowują się w sposób uporządkowany. Różne czujniki mogą rejestrować z różną częstotliwością, przerywać pomiary lub dawać zaszumione odczyty. Niektóre zastosowania śledzą pojedynczy sygnał, na przykład rytm serca, podczas gdy inne łączą dziesiątki kanałów, jak ruch, aktywność mięśniowa i fale mózgowe. Tradycyjne metody albo ręcznie tworzą cechy, albo używają głębokich modeli uczących się bezpośrednio na surowych sekwencjach czasowych. Takie podejścia mogą działać, lecz często mają problemy z uogólnianiem na wiele zbiorów danych i wymagają starannego dostrajania dla każdego nowego zadania.
Z fal jednowymiarowych do obrazów dwuwymiarowych
Autorzy proponują TS2Vision, ramę, która konwertuje szeregi czasowe na obrazy przed klasyfikacją. Najpierw każdy kanał jest standaryzowany i płynnie zmieniany rozmiar, tak aby krótsze i dłuższe sekwencje miały wspólną długość. Następnie adaptacyjne odwzorowanie zwane Adaptive Time Series Gaussian Mapping zamienia każdy moment czasu w mały kwadratowy fragment obrazu. W obrębie tego fragmentu każdemu kanałowi przypisuje się obszar w kształcie okręgu. Wewnątrz każdego koła rysowany jest wzorzec dzwonowy, sterowany bieżącą wartością sygnału. Proces ten rejestruje lokalne wzloty i spadki w sposób zarówno płynny, jak i odporny na szum.
Zmieszczanie wielu sygnałów w jednym widoku
Kluczowym wyzwaniem jest rozmieszczenie wszystkich tych okrągłych obszarów tak, aby się nie nachodziły, a jednocześnie efektywnie wykorzystały ograniczoną przestrzeń w każdym kafelku. Autorzy traktują to jako zagadkę pakowania kół: jak zmieścić równe okręgi ciasno w kwadracie. Korzystają z udokumentowanych układów z badań geometrycznych, aby rozmieścić okręgi dla dowolnej liczby kanałów. Układy te są ustalone z góry, więc model nie traci zasobów na uczenie, gdzie umieszczać każdy kanał. W miarę upływu czasu kafelki są ustawiane w kolejności, tworząc większy obraz, który zachowuje zarówno zmiany każdego sygnału, jak i relacje między kanałami. 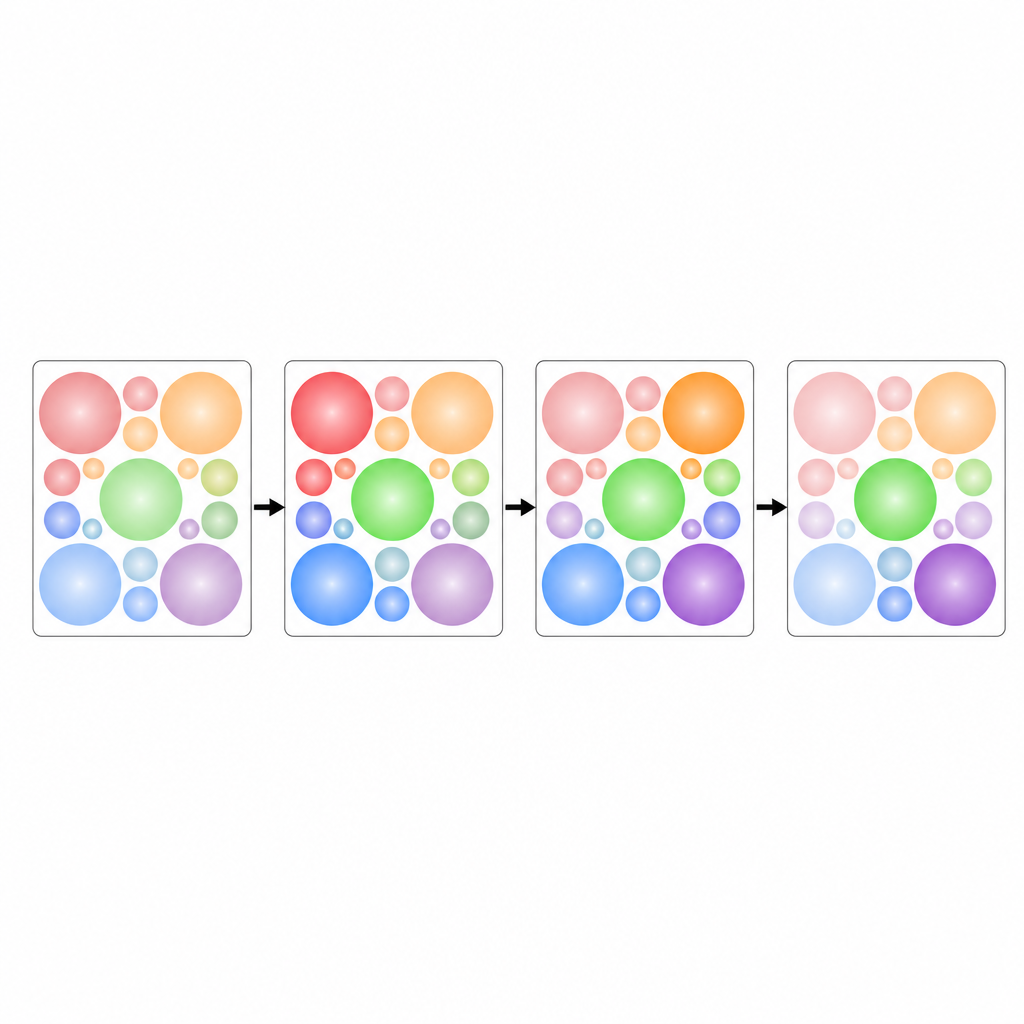
Pozwalając modelom wizji czytać czas
Gdy szeregi czasowe zostaną przekształcone w obraz, TS2Vision przekazuje go do Vision Transformera, rodzaju modelu pierwotnie zaprojektowanego do rozpoznawania obrazów. Model ten dzieli obraz na mniejsze kafelki i używa mechanizmów uwagi, by łączyć wzorce w odległych częściach obrazu, które tu odpowiadają odległym krokom czasowym. Autorzy wykazują matematycznie, że ich odwzorowanie jest stabilne: niewielkie zmiany w sygnałach wejściowych prowadzą jedynie do ograniczonych zmian w obrazie, co pomaga klasyfikatorowi zachować odporność, gdy dane są zaszumione lub czujniki drgają.
Testy na wielu zbiorach danych z rzeczywistego świata
Aby sprawdzić, jak dobrze TS2Vision działa w praktyce, badacze przetestowali go na 158 zestawach benchmarkingowych zebranych z dwóch głównych archiwów. Obejmują one szeroką gamę domen, w tym odczyty z urządzeń, rejestracje ruchu, nagrania medyczne, obrazy przekształcone w szeregi czasowe i inne. Zarówno w zadaniach jedno-, jak i wielokanałowych, TS2Vision uzyskał najlepszą średnią pozycję w rankingu wśród nowoczesnych metod głębokiego uczenia oraz konkurencyjną dokładność w porównaniu z czołowymi technikami niedeep learningowymi, przy zachowaniu rozsądnych czasów treningu. Pokazał także silną odporność przy dodawaniu sztucznego szumu — jego spadek wydajności był łagodniejszy niż w modelach konkurencyjnych.
Co to oznacza dla systemów codziennego użytku
Mówiąc prościej, TS2Vision pokazuje, że traktowanie szeregów czasowych jako starannie zaprojektowanych obrazów może odblokować możliwości wizji komputerowej dla danych temporalnych. Łącząc stabilny, adaptacyjny sposób przedstawiania sygnałów jako obrazów z mocnym modelem wizji, ta rama oferuje ujednoliconą metodę działającą dla wielu rodzajów czujników i długości sekwencji. Dla twórców systemów monitorowania i wspomagania decyzji oznacza to bardziej uniwersalne narzędzie, które radzi sobie z zróżnicowanymi i zaszumionymi danymi, pozostając wystarczająco wydajne do praktycznego zastosowania.
Cytowanie: Ren, X., Li, D., Gao, X. et al. A unified time series classification framework via adaptive Gaussian image representation. Sci Rep 16, 14817 (2026). https://doi.org/10.1038/s41598-026-44760-6
Słowa kluczowe: klasyfikacja szeregów czasowych, reprezentacja obrazu, vision transformer, czujniki wielowymiarowe, odporne kodowanie