Clear Sky Science · fr
Un cadre unifié de classification de séries temporelles via une représentation image gaussienne adaptative
Transformer des signaux temporels complexes en images
Des battements de cœur et ondes cérébrales aux cours boursiers et flux de trafic, une grande partie de notre monde numérique est enregistrée sous forme de séries temporelles : des nombres qui évoluent au cours du temps. Pourtant, ces flux emmêlés sont difficiles à classifier de manière fiable, surtout lorsqu’ils proviennent de nombreux capteurs simultanément ou varient en longueur. Cet article présente une méthode pour convertir ces signaux désordonnés en images que les modèles visuels modernes peuvent comprendre, facilitant la construction de systèmes fiables pour la surveillance de la santé, la finance et les appareils du quotidien. 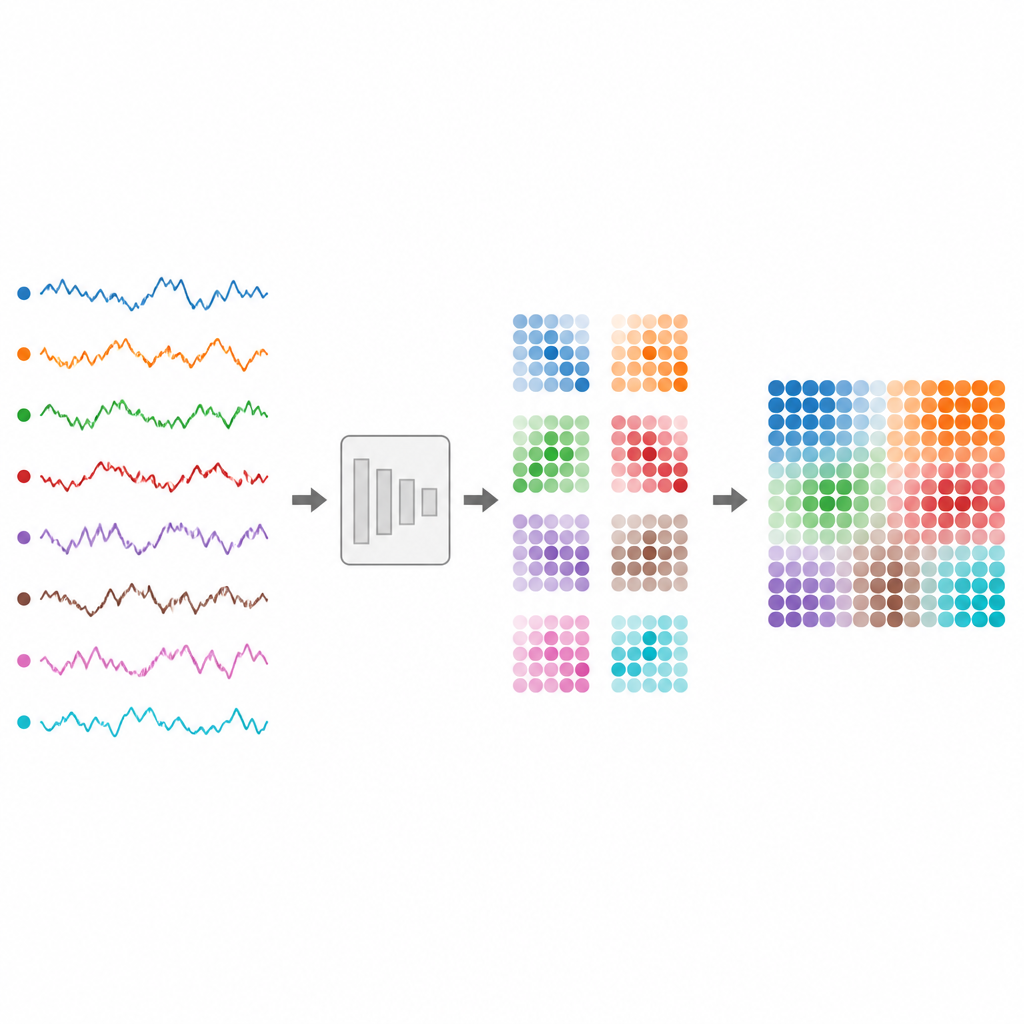
Pourquoi les séries temporelles sont si difficiles à classer
Les séries temporelles du monde réel se comportent rarement de façon idéale. Différents capteurs peuvent enregistrer à des vitesses différentes, s’arrêter et redémarrer de manière inattendue, ou produire des mesures bruitées. Certaines applications suivent un seul signal, comme un battement de cœur, tandis que d’autres combinent des dizaines de canaux, tels que mouvements, activité musculaire et ondes cérébrales. Les méthodes traditionnelles extraient soit des caractéristiques manuellement, soit utilisent des modèles profonds qui opèrent directement sur les séquences temporelles brutes. Ces approches peuvent fonctionner, mais elles peinent souvent à généraliser sur de nombreux jeux de données et exigent un réglage minutieux pour chaque nouveau problème.
De vagues unidimensionnelles à des images bidimensionnelles
Les auteurs proposent TS2Vision, un cadre qui convertit les séries temporelles en images avant classification. D’abord, chaque canal est standardisé et redimensionné de façon lisse pour que les séquences courtes et longues partagent une longueur commune. Puis une cartographie adaptative appelée Adaptive Time Series Gaussian Mapping transforme chaque instant temporel en une petite tuile carrée à l’intérieur d’une image. Dans cette tuile, chaque canal de capteur se voit attribuer une région circulaire. Un motif en forme de cloche, contrôlé par la valeur courante du signal, est tracé à l’intérieur de chaque cercle. Ce processus capture les montées et descentes locales d’une manière à la fois lisse et résistante au bruit.
Assembler de nombreux signaux dans une seule vue
Un défi clé consiste à placer toutes ces régions circulaires sans chevauchement tout en utilisant efficacement l’espace limité de chaque tuile. Les auteurs traitent cela comme un casse-tête d’empilement de cercles : comment faire tenir des cercles égaux de façon serrée à l’intérieur d’un carré. Ils s’appuient sur des dispositions éprouvées issues de la recherche en géométrie pour organiser les cercles pour n’importe quel nombre de canaux. Ces dispositions sont fixées à l’avance, de sorte que le modèle ne gaspille pas d’effort à apprendre où placer chaque canal. Au fil du temps, les tuiles sont ordonnées en séquence, formant une image plus grande qui préserve à la fois l’évolution de chaque signal et les relations entre les canaux. 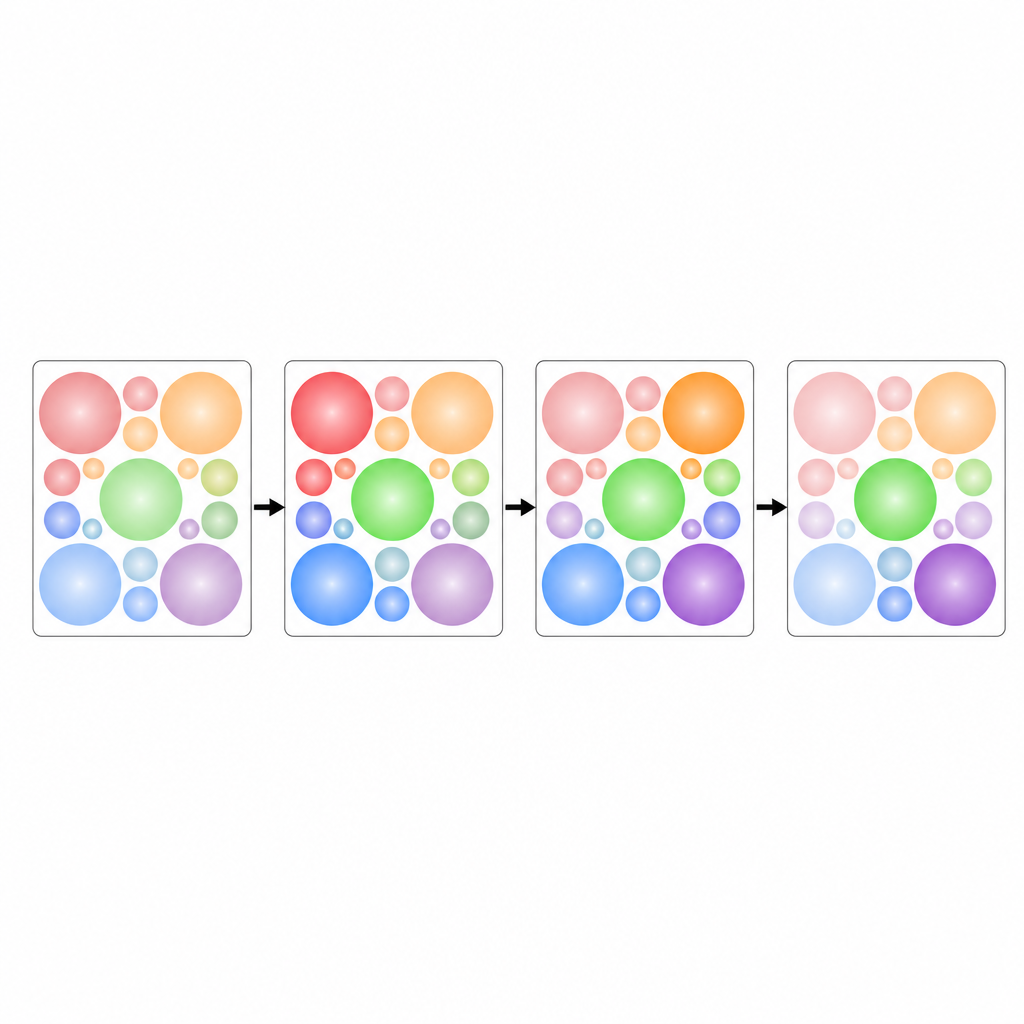
Laisser les modèles de vision lire le temps
Une fois la série temporelle transformée en image, TS2Vision l’alimente dans un Vision Transformer, un type de modèle initialement conçu pour la reconnaissance d’images. Ce modèle découpe l’image en petites tuiles et utilise des mécanismes d’attention pour relier des motifs situés dans des parties éloignées de l’image, qui correspondent ici à des instants temporels éloignés. Les auteurs démontrent mathématiquement que leur cartographie est stable : de faibles changements dans les signaux d’entrée entraînent uniquement des changements bornés dans l’image, ce qui aide le classifieur à rester robuste lorsque les données sont bruitées ou que les capteurs présentent des jitter.
Testé sur de nombreux jeux de données réels
Pour évaluer les performances de TS2Vision en pratique, les chercheurs l’ont testé sur 158 jeux de données de référence collectés à partir de deux archives majeures. Ceux-ci couvrent un large éventail de domaines, incluant relevés d’appareils, capture de mouvement, enregistrements médicaux, images converties en séries temporelles, et plus encore. Tant pour les tâches mono-canal que multicanal, TS2Vision a obtenu le meilleur classement moyen parmi les méthodes modernes de deep learning et une précision compétitive comparée aux principales techniques non profondes, tout en conservant des temps d’entraînement raisonnables. Il a également montré une forte résilience lorsque du bruit artificiel a été ajouté, se dégradant plus doucement que les modèles concurrents.
Ce que cela signifie pour les systèmes du quotidien
En termes simples, TS2Vision montre que traiter les séries temporelles comme des images soigneusement conçues peut libérer la puissance de la vision par ordinateur pour les données temporelles. En combinant une façon adaptative et stable de dessiner les signaux en tant qu’images avec un modèle de vision performant, le cadre offre une méthode unifiée qui fonctionne sur de nombreux types de capteurs et longueurs de séquence. Pour les concepteurs de systèmes de surveillance et de décision, cela signifie un outil plus général capable de gérer des données variées et bruitées tout en restant suffisamment efficace pour un usage pratique.
Citation: Ren, X., Li, D., Gao, X. et al. A unified time series classification framework via adaptive Gaussian image representation. Sci Rep 16, 14817 (2026). https://doi.org/10.1038/s41598-026-44760-6
Mots-clés: classification de séries temporelles, représentation image, vision transformer, capteurs multivariés, encodage robuste