Clear Sky Science · pt
Uma estrutura unificada de classificação de séries temporais via representação de imagem Gaussiana adaptativa
Transformando sinais temporais complexos em imagens
De batimentos cardíacos e ondas cerebrais a preços de ações e fluxos de tráfego, grande parte do nosso mundo digital é registrada como séries temporais: números que mudam ao longo do tempo. Entretanto, esses fluxos emaranhados são difíceis de classificar de forma confiável por computadores, sobretudo quando vêm de muitos sensores ao mesmo tempo ou variam em comprimento. Este artigo apresenta uma forma de transformar tais sinais desordenados em imagens que modelos de visão modernos conseguem interpretar, facilitando a construção de sistemas confiáveis para monitoramento da saúde, finanças e dispositivos do dia a dia. 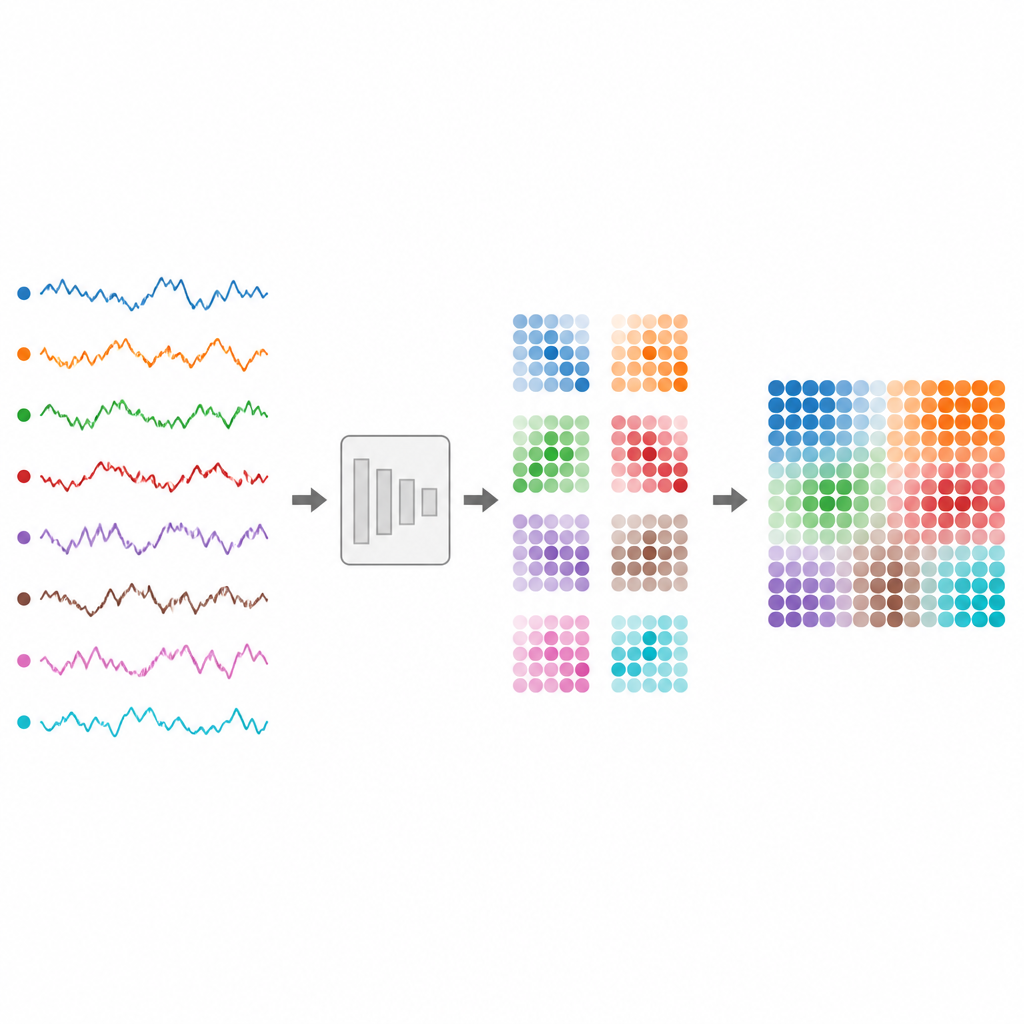
Por que séries temporais são tão difíceis de classificar
Séries temporais no mundo real raramente se comportam de forma ideal. Diferentes sensores podem registrar em velocidades distintas, parar e reiniciar inesperadamente ou produzir leituras ruidosas. Algumas aplicações acompanham um único sinal, como um batimento cardíaco, enquanto outras combinam dezenas de canais, como movimento, atividade muscular e ondas cerebrais. Métodos tradicionais ou extraem características manualmente ou usam modelos de deep learning que operam diretamente nas sequências temporais brutas. Essas abordagens podem funcionar, mas frequentemente têm dificuldade para generalizar entre muitos conjuntos de dados e exigem ajuste cuidadoso para cada novo problema.
De ondas unidimensionais a imagens bidimensionais
Os autores propõem o TS2Vision, uma estrutura que converte séries temporais em imagens antes da classificação. Primeiro, cada canal é padronizado e redimensionado suavemente para que sequências mais curtas e mais longas compartilhem um comprimento comum. Em seguida, um mapeamento adaptativo chamado Adaptive Time Series Gaussian Mapping transforma cada momento no tempo em um pequeno bloco quadrado dentro de uma imagem. Dentro desse bloco, cada canal de sensor recebe uma região circular. Um padrão em formato de sino, controlado pelo valor atual do sinal, é desenhado dentro de cada círculo. Esse processo captura oscilações locais de maneira suave e resistente ao ruído.
Empacotando muitos sinais em uma única visão
Um desafio central é como posicionar todas essas regiões circulares para que não se sobreponham, usando ao mesmo tempo o espaço limitado de cada bloco de forma eficiente. Os autores tratam isso como um quebra-cabeça de empacotamento de círculos: como acomodar círculos iguais confortavelmente dentro de um quadrado. Eles se baseiam em disposições comprovadas pela pesquisa geométrica para organizar os círculos para qualquer número de canais. Essas disposições são fixas antecipadamente, de modo que o modelo não desperdiça esforço aprendendo onde colocar cada canal. Conforme o tempo avança, os blocos são ordenados em sequência, formando uma imagem maior que preserva tanto como cada sinal muda quanto como os canais se relacionam entre si. 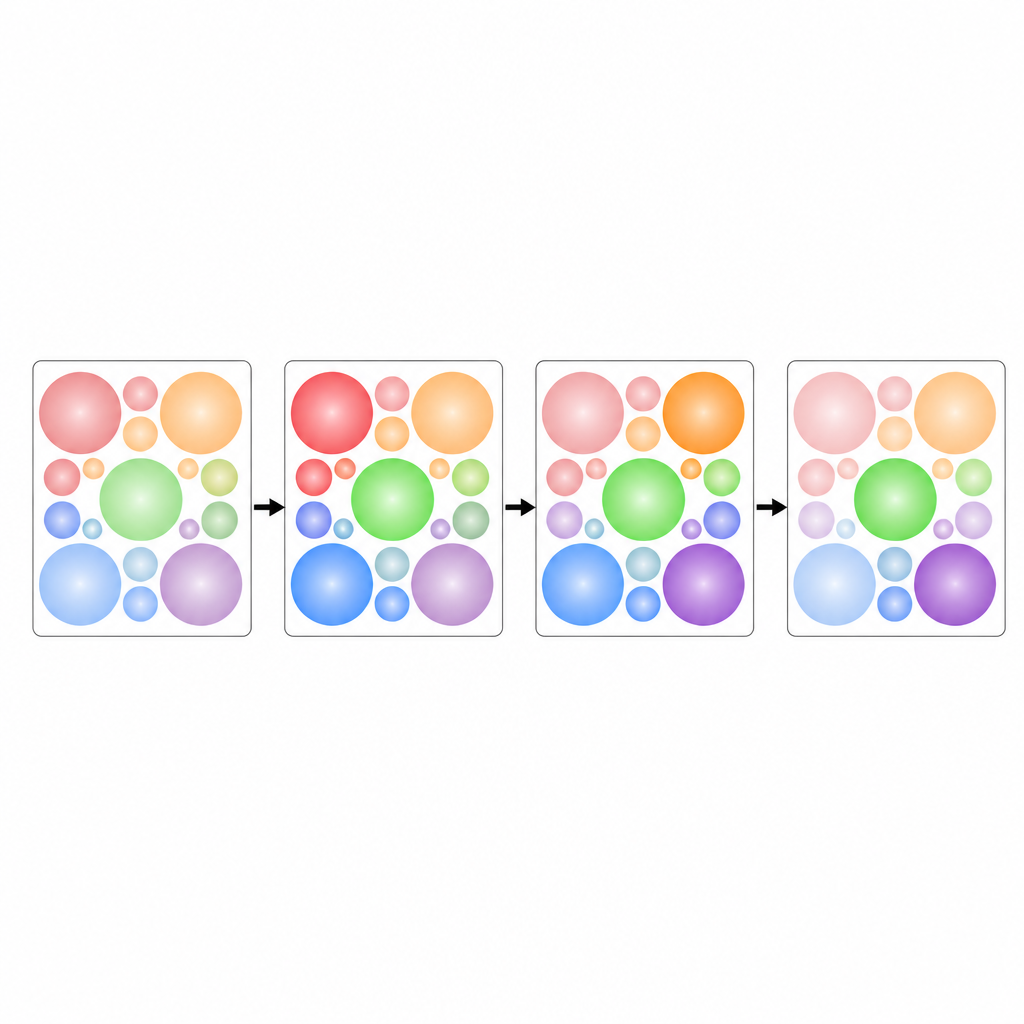
Deixando modelos de visão lerem o tempo
Uma vez que a série temporal foi transformada em imagem, o TS2Vision a alimenta a um Vision Transformer, um tipo de modelo originalmente projetado para reconhecimento de imagens. Esse modelo divide a imagem em ladrilhos menores e usa mecanismos de atenção para conectar padrões em partes distantes da imagem, que aqui correspondem a passos de tempo distantes. Os autores demonstram matematicamente que seu mapeamento é estável: pequenas mudanças nos sinais de entrada levam apenas a variações limitadas na imagem, o que ajuda o classificador a permanecer robusto quando os dados são ruidosos ou os sensores tremem.
Testes em muitos conjuntos de dados do mundo real
Para avaliar o desempenho do TS2Vision na prática, os pesquisadores testaram-no em 158 conjuntos de dados de referência coletados a partir de dois grandes arquivos. Esses conjuntos cobrem uma mistura ampla de domínios, incluindo leituras de dispositivos, captura de movimento, gravações médicas, imagens convertidas em séries temporais e mais. Tanto em tarefas de canal único quanto multicanal, o TS2Vision alcançou a melhor classificação média entre métodos modernos de deep learning e acurácia competitiva em comparação com técnicas líderes não baseadas em deep learning, mantendo tempos de treinamento razoáveis. Também mostrou forte resiliência quando ruído artificial foi adicionado, degradando-se de forma mais suave que modelos concorrentes.
O que isso significa para sistemas do dia a dia
Em termos leigos, o TS2Vision demonstra que tratar séries temporais como imagens cuidadosamente projetadas pode desbloquear o poder da visão computacional para dados temporais. Ao combinar uma forma estável e adaptativa de desenhar sinais como imagens com um modelo de visão robusto, a estrutura oferece um método unificado que funciona em muitos tipos de sensores e comprimentos de sequência. Para desenvolvedores de sistemas de monitoramento e decisão, isso significa uma ferramenta mais geral capaz de lidar com dados variados e ruidosos, permanecendo eficiente o suficiente para uso prático.
Citação: Ren, X., Li, D., Gao, X. et al. A unified time series classification framework via adaptive Gaussian image representation. Sci Rep 16, 14817 (2026). https://doi.org/10.1038/s41598-026-44760-6
Palavras-chave: classificação de séries temporais, representação por imagem, vision transformer, sensores multivariados, codificação robusta