Clear Sky Science · de
Ein einheitliches Framework zur Zeitreihenklassifikation mittels adaptiver Gaußscher Bilddarstellung
Komplexe Zeitsignale in Bilder verwandeln
Von Herzschlägen und Hirnströmen bis hin zu Aktienkursen und Verkehrsflüssen: Vieles in unserer digitalen Welt liegt als Zeitreihe vor, also Zahlen, die sich über die Zeit ändern. Solche verknoteten Ströme sind für Computer schwer zuverlässig zu klassifizieren, besonders wenn sie von vielen Sensoren stammen oder in ihrer Länge variieren. Dieses Papier stellt eine Methode vor, solche unordentlichen Signale in Bilder zu überführen, die moderne Vision-Modelle verstehen können. Das erleichtert den Aufbau verlässlicher Systeme zur Überwachung von Gesundheit, Finanzen und Alltagsgeräten. 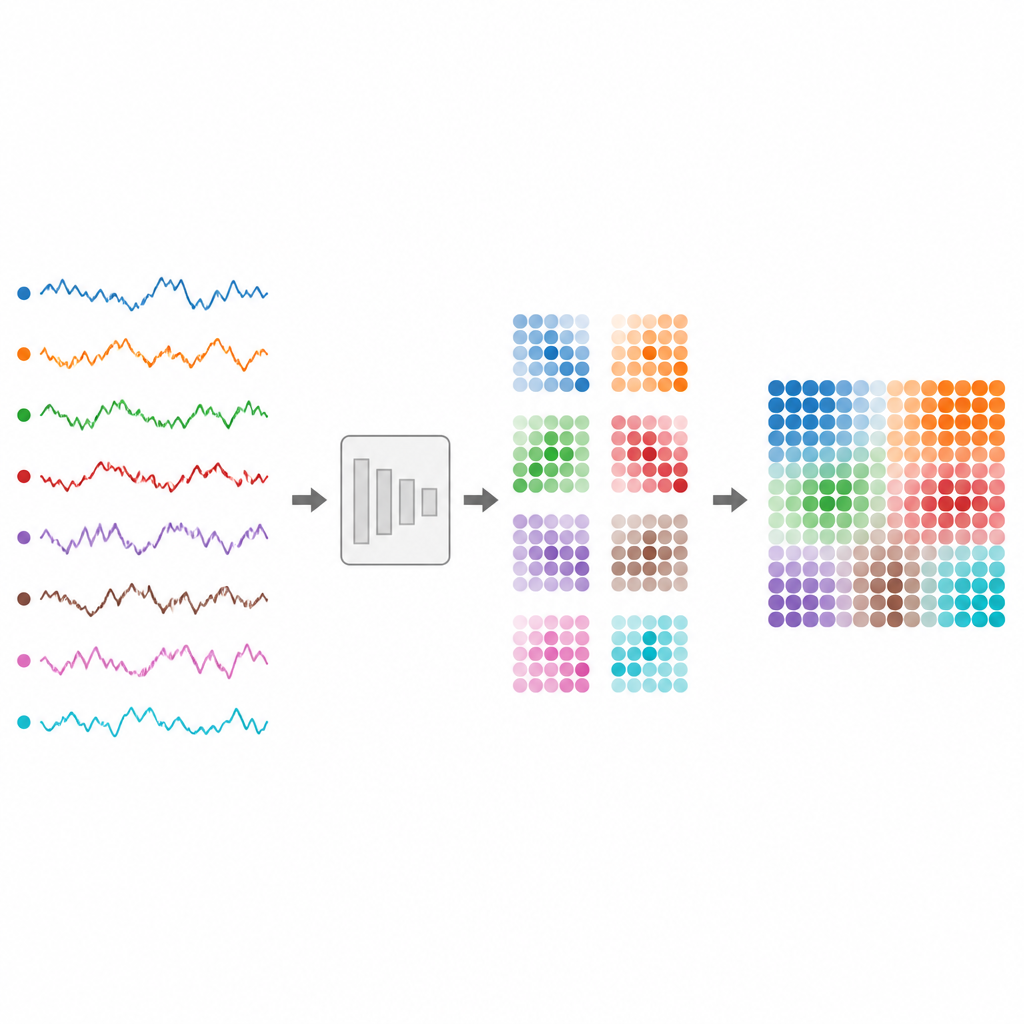
Warum Zeitreihen so schwer zu klassifizieren sind
Zeitreihen verhalten sich in der Praxis selten ordentlich. Unterschiedliche Sensoren messen mit verschiedenen Geschwindigkeiten, können unregelmäßig aussetzen oder laute Messwerte liefern. Manche Anwendungen verfolgen nur ein Signal, etwa einen Herzschlag, andere kombinieren dutzende Kanäle wie Bewegung, Muskelaktivität und Hirnströme. Traditionelle Methoden fertigen entweder manuell Merkmale an oder nutzen Deep-Learning-Modelle, die direkt auf Rohsequenzen arbeiten. Diese Ansätze können funktionieren, kommen jedoch oft schwer über viele Datensätze hinweg generalisierbar zu sein und benötigen für jedes neue Problem sorgfältiges Tuning.
Von eindimensionalen Wellen zu zweidimensionalen Bildern
Die Autor:innen schlagen TS2Vision vor, ein Framework, das Zeitreihen vor der Klassifikation in Bilder umwandelt. Zuerst wird jeder Kanal standardisiert und glatt skaliert, sodass kürzere und längere Sequenzen eine gemeinsame Länge erhalten. Dann wandelt eine adaptive Abbildung, die Adaptive Time Series Gaussian Mapping heißt, jeden Zeitpunkt in ein kleines quadratisches Patch innerhalb eines Bildes um. Innerhalb dieses Patches wird jedem Sensorkanal ein kreisförmiger Bereich zugewiesen. In jedem Kreis wird ein glockenförmiges Muster gezeichnet, das durch den aktuellen Signalwert gesteuert wird. Dieser Prozess erfasst lokale Auf- und Abwärtsbewegungen auf eine Weise, die sowohl glatt als auch gegen Rauschen robust ist.
Viele Signale in einer Ansicht bündeln
Eine zentrale Herausforderung ist, all diese kreisförmigen Bereiche so anzuordnen, dass sie sich nicht überlappen und gleichzeitig den begrenzten Platz pro Patch effizient nutzen. Die Autor:innen behandeln das als Kreispackungsproblem: wie gleiche Kreise dicht in ein Quadrat passen. Sie stützen sich auf erprobte Anordnungen aus der Geometrieforschung, um die Kreise für jede Anzahl von Kanälen zu platzieren. Diese Layouts sind im Vorfeld festgelegt, sodass das Modell keine Ressourcen darauf verwendet, zu lernen, wo jeder Kanal liegen soll. Mit fortschreitender Zeit werden die Patches in Reihenfolge angeordnet und bilden ein größeres Bild, das sowohl die Veränderung jeder Signalfolge als auch die Beziehungen zwischen den Kanälen bewahrt. 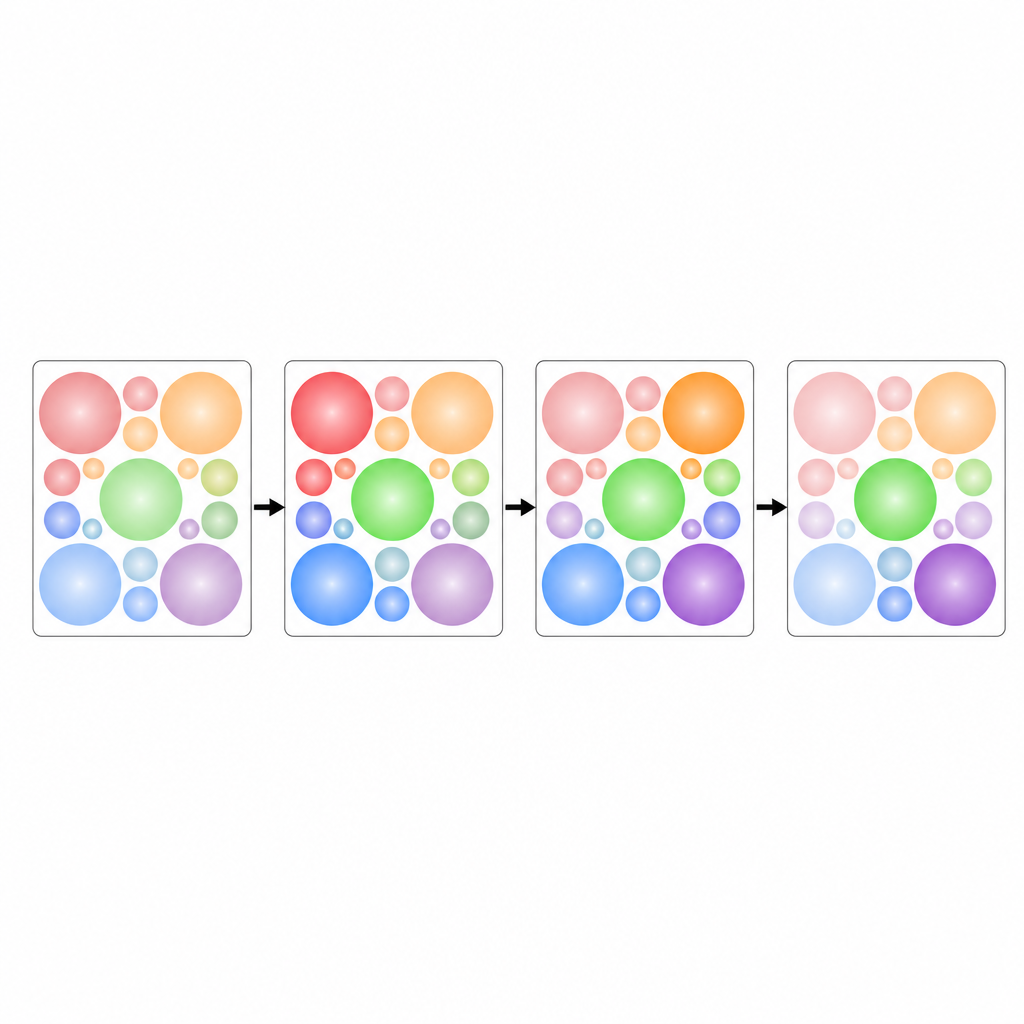
Vision-Modelle lesen Zeit
Sobald die Zeitreihe in ein Bild überführt ist, gibt TS2Vision dieses an einen Vision Transformer weiter, einen Modelltyp, der ursprünglich für Bilderkennung entworfen wurde. Dieses Modell zerteilt das Bild in kleinere Kacheln und nutzt Aufmerksamkeitsmechanismen, um Muster über weit entfernte Bildbereiche hinweg zu verknüpfen — hier entsprechen diese entfernten Bereiche weit auseinanderliegenden Zeitpunkten. Die Autor:innen zeigen mathematisch, dass ihre Abbildung stabil ist: Kleine Änderungen in den Eingangssignalen führen nur zu begrenzten Änderungen im Bild, was dem Klassifikator hilft, robust zu bleiben, wenn Daten verrauscht sind oder Sensoren zittern.
Tests über viele reale Datensätze
Um die praktische Leistungsfähigkeit von TS2Vision zu prüfen, testeten die Forschenden es an 158 Benchmark-Datensätzen aus zwei großen Archiven. Diese decken ein breites Spektrum an Bereichen ab, darunter Gerätemessungen, Motion-Capture, medizinische Aufzeichnungen, in Zeitreihen umgewandelte Bilder und mehr. Sowohl bei Ein-Kanal- als auch bei Mehrkanalaufgaben erreichte TS2Vision die beste durchschnittliche Platzierung unter modernen Deep-Learning-Methoden und eine wettbewerbsfähige Genauigkeit gegenüber führenden nicht-deep-learning Techniken, bei gleichzeitig vertretbaren Trainingszeiten. Außerdem zeigte es eine starke Widerstandsfähigkeit gegenüber künstlich hinzugefügtem Rauschen und degradiert langsamer als konkurrierende Modelle.
Was das für Alltagssysteme bedeutet
Einfach gesagt zeigt TS2Vision, dass die Behandlung von Zeitreihen als sorgfältig gestaltete Bilder die Leistungsfähigkeit der Computer-Vision für zeitliche Daten erschließen kann. Durch die Kombination einer stabilen, adaptiven Art, Signale als Bilder darzustellen, mit einem starken Vision-Modell bietet das Framework eine einheitliche Methode, die über viele Sensortypen und Sequenzlängen hinweg funktioniert. Für Entwickler von Überwachungs- und Entscheidungsystemen bedeutet das ein allgemeineres Werkzeug, das vielfältige und verrauschte Daten handhaben kann und zugleich effizient genug für den praktischen Einsatz bleibt.
Zitation: Ren, X., Li, D., Gao, X. et al. A unified time series classification framework via adaptive Gaussian image representation. Sci Rep 16, 14817 (2026). https://doi.org/10.1038/s41598-026-44760-6
Schlüsselwörter: Zeitreihenklassifikation, Bildrepräsentation, Vision Transformer, multivariate Sensoren, robuste Kodierung