Clear Sky Science · it
Un quadro unificato per la classificazione di serie temporali tramite una rappresentazione immagini gaussiana adattativa
Trasformare segnali temporali complessi in immagini
Dai battiti cardiaci e onde cerebrali ai prezzi di borsa e ai flussi di traffico, gran parte del nostro mondo digitale è registrata come serie temporali: numeri che cambiano nel tempo. Tuttavia questi flussi intrecciati sono difficili da classificare in modo affidabile per i computer, specialmente quando provengono da molti sensori contemporaneamente o variano in lunghezza. Questo articolo introduce un modo per trasformare tali segnali disordinati in immagini che i moderni modelli di visione possono comprendere, facilitando la costruzione di sistemi affidabili per il monitoraggio della salute, della finanza e dei dispositivi quotidiani. 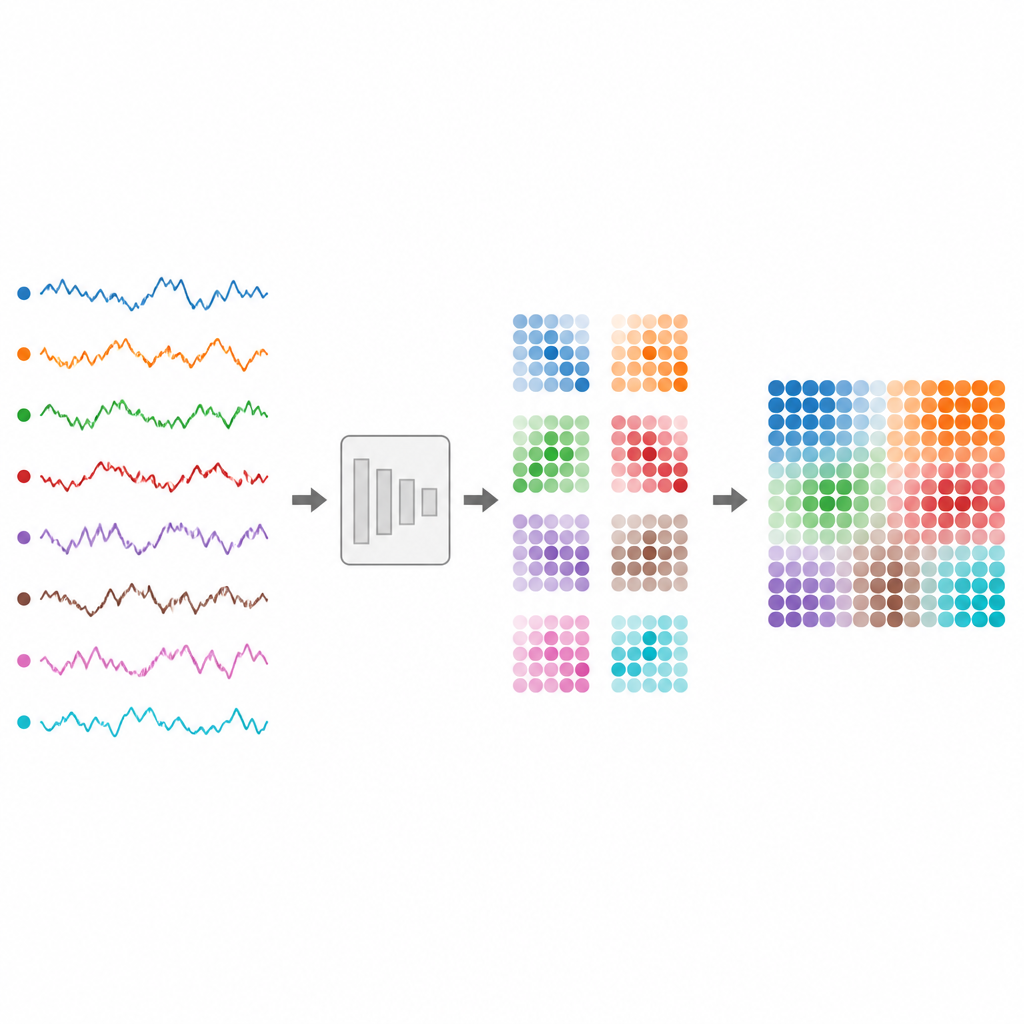
Perché le serie temporali sono così difficili da classificare
Le serie temporali nel mondo reale raramente si comportano in modo regolare. Diversi sensori possono registrare a velocità differenti, interrompersi e riprendere inaspettatamente o fornire letture rumorose. Alcune applicazioni tracciano un singolo segnale, come un battito cardiaco, mentre altre combinano dozzine di canali, come movimento, attività muscolare e onde cerebrali insieme. I metodi tradizionali o estraggono caratteristiche a mano oppure usano modelli di deep learning che operano direttamente sulle sequenze temporali grezze. Questi approcci possono funzionare, ma spesso faticano a generalizzare su molti dataset e richiedono una taratura accurata per ogni nuovo problema.
Da onde unidimensionali a immagini bidimensionali
Gli autori propongono TS2Vision, un framework che converte le serie temporali in immagini prima della classificazione. Innanzitutto, ogni canale viene standardizzato e ridimensionato in modo fluido affinché sequenze più corte e più lunghe condividano una lunghezza comune. Poi una mappatura adattativa chiamata Adaptive Time Series Gaussian Mapping trasforma ogni istante temporale in una piccola tessera quadrata all'interno di un'immagine. In quella tessera, a ogni canale sensoriale viene assegnata una regione circolare. All'interno di ciascun cerchio viene tracciato un profilo a campana, controllato dal valore corrente del segnale. Questo processo cattura salite e discese locali in modo sia liscio sia resistente al rumore.
Compattare molti segnali in una sola vista
Una sfida chiave è come disporre tutte quelle regioni circolari in modo che non si sovrappongano, sfruttando allo stesso tempo lo spazio limitato di ciascuna tessera in modo efficiente. Gli autori trattano questo come un rompicapo di impacchettamento di cerchi: come adattare cerchi uguali all'interno di un quadrato. Si basano su layout consolidati dalla ricerca geometrica per disporre i cerchi per qualsiasi numero di canali. Questi layout sono fissati in anticipo, così il modello non perde tempo a imparare dove posizionare ogni canale. Man mano che il tempo avanza, le tessere sono ordinate in sequenza, formando un'immagine più ampia che preserva sia come ciascun segnale cambia sia come i canali si relazionano tra loro. 
Lasciare che i modelli di visione leggano il tempo
Una volta che la serie temporale è stata trasformata in immagine, TS2Vision la passa a un Vision Transformer, un tipo di modello originariamente progettato per il riconoscimento di immagini. Questo modello suddivide l'immagine in tessere più piccole e usa meccanismi di attenzione per connettere pattern tra parti distanti dell'immagine, che qui corrispondono a istanti temporali distanti. Gli autori dimostrano matematicamente che la loro mappatura è stabile: piccole variazioni nei segnali in ingresso portano solo a variazioni limitate nell'immagine, il che aiuta il classificatore a rimanere robusto quando i dati sono rumorosi o i sensori tremolano.
Verifiche su molti dataset del mondo reale
Per valutare l'efficacia di TS2Vision nella pratica, i ricercatori lo hanno testato su 158 dataset di riferimento raccolti da due archivi principali. Questi coprono un ampio ventaglio di domini, incluse letture di dispositivi, motion capture, registrazioni mediche, immagini convertite in serie temporali e altro. Sia nei compiti a singolo canale sia in quelli multicanale, TS2Vision ha ottenuto il miglior posizionamento medio tra i moderni metodi di deep learning e un'accuratezza competitiva rispetto alle migliori tecniche non basate su deep learning, mantenendo tempi di addestramento ragionevoli. Ha inoltre mostrato una forte resilienza quando è stato aggiunto rumore artificiale, degradando più gradualmente rispetto ai modelli concorrenti.
Cosa significa per i sistemi di uso quotidiano
In termini semplici, TS2Vision dimostra che trattare le serie temporali come immagini progettate con cura può sbloccare la potenza della visione artificiale per i dati temporali. Combinando un modo stabile e adattativo di rappresentare i segnali come immagini con un solido modello di visione, il framework offre un metodo unificato che funziona su molti tipi di sensori e lunghezze di sequenza. Per chi progetta sistemi di monitoraggio e decisione, ciò significa uno strumento più generale in grado di gestire dati vari e rumorosi rimanendo sufficientemente efficiente per l'uso pratico.
Citazione: Ren, X., Li, D., Gao, X. et al. A unified time series classification framework via adaptive Gaussian image representation. Sci Rep 16, 14817 (2026). https://doi.org/10.1038/s41598-026-44760-6
Parole chiave: classificazione di serie temporali, rappresentazione in immagine, vision transformer, sensori multivariati, codifica robusta