Clear Sky Science · es
Un marco unificado para clasificación de series temporales mediante representación de imágenes gaussianas adaptativa
Convertir señales temporales complejas en imágenes
Desde latidos y ondas cerebrales hasta precios de acciones y flujos de tráfico, gran parte de nuestro mundo digital se registra como series temporales: números que cambian a lo largo del tiempo. Sin embargo, estas corrientes enmarañadas son difíciles de clasificar de forma fiable por los ordenadores, especialmente cuando proceden de muchos sensores a la vez o tienen longitudes variables. Este artículo introduce una forma de convertir esas señales desordenadas en imágenes que los modelos de visión modernos pueden entender, facilitando la creación de sistemas fiables para monitorizar la salud, las finanzas y dispositivos cotidianos. 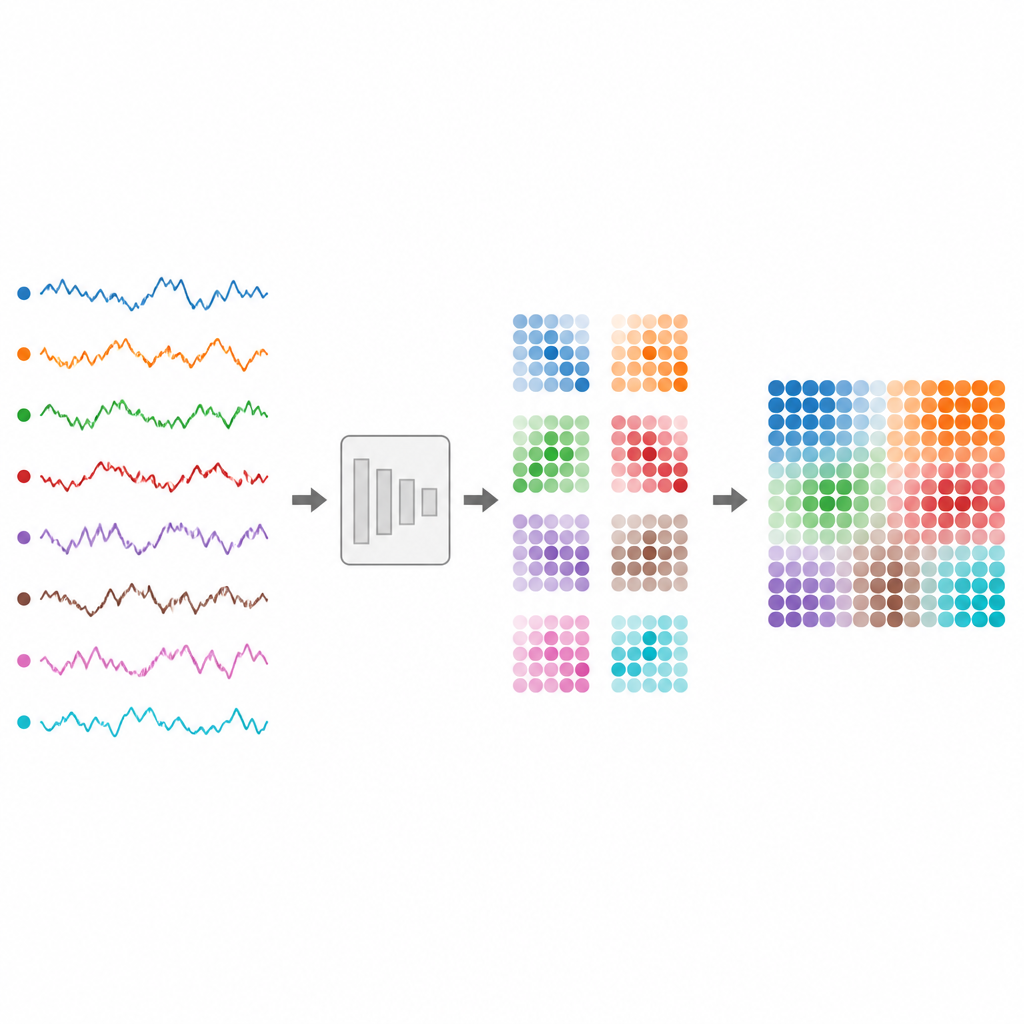
Por qué es tan difícil clasificar series temporales
Las series temporales del mundo real rara vez se comportan de forma ordenada. Diferentes sensores pueden registrar a distintas velocidades, detenerse y reanudarse inesperadamente, o producir lecturas ruidosas. Algunas aplicaciones siguen una única señal, como un latido, mientras que otras combinan docenas de canales, como movimiento, actividad muscular y ondas cerebrales. Los métodos tradicionales o bien diseñan características a mano o emplean modelos de aprendizaje profundo que operan directamente sobre las secuencias temporales crudas. Estos enfoques pueden funcionar, pero a menudo tienen dificultades para generalizar entre muchos conjuntos de datos y requieren un ajuste cuidadoso para cada nuevo problema.
De ondas unidimensionales a imágenes bidimensionales
Los autores proponen TS2Vision, un marco que convierte series temporales en imágenes antes de clasificarlas. Primero, cada canal se estandariza y se redimensiona suavemente de modo que las secuencias más cortas y más largas compartan una longitud común. Luego, un mapeo adaptativo llamado Adaptive Time Series Gaussian Mapping convierte cada instante temporal en un pequeño parche cuadrado dentro de una imagen. Dentro de ese parche, a cada canal de sensor se le asigna una región circular. Se dibuja dentro de cada círculo un patrón en forma de campana, controlado por el valor actual de la señal. Este proceso captura subidas y bajadas locales de una manera tanto suave como resistente al ruido.
Empaquetando muchas señales en una sola vista
Un reto clave es cómo colocar todas esas regiones circulares para que no se solapen y, al mismo tiempo, usar el espacio limitado de cada parche de forma eficiente. Los autores tratan esto como un rompecabezas de empaquetamiento de círculos: cómo encajar círculos iguales ajustados dentro de un cuadrado. Se basan en disposiciones probadas por la investigación en geometría para organizar los círculos para cualquier número de canales. Estas disposiciones se fijan de antemano, de modo que el modelo no desperdicia esfuerzo en aprender dónde ubicar cada canal. A medida que avanza el tiempo, los parches se ordenan en secuencia, formando una imagen mayor que preserva tanto cómo cambia cada señal como cómo se relacionan entre sí los canales. 
Permitir que los modelos de visión lean el tiempo
Una vez que la serie temporal se ha convertido en una imagen, TS2Vision la alimenta a un Vision Transformer, un tipo de modelo diseñado originalmente para el reconocimiento de imágenes. Este modelo corta la imagen en baldosas más pequeñas y utiliza mecanismos de atención para conectar patrones en partes distantes de la imagen, que aquí corresponden a pasos de tiempo lejanos. Los autores demuestran matemáticamente que su mapeo es estable: pequeños cambios en las señales de entrada conducen solo a cambios acotados en la imagen, lo que ayuda al clasificador a mantenerse robusto cuando los datos son ruidosos o los sensores tiemblan.
Pruebas en numerosos conjuntos de datos del mundo real
Para evaluar el desempeño de TS2Vision en la práctica, los investigadores lo probaron en 158 conjuntos de datos de referencia recopilados de dos archivos principales. Estos abarcan una amplia mezcla de dominios, incluidas lecturas de dispositivos, captura de movimiento, registros médicos, imágenes convertidas en series temporales y más. Tanto en tareas de canal único como multicanal, TS2Vision obtuvo la mejor clasificación media entre métodos modernos de aprendizaje profundo y una precisión competitiva frente a técnicas punteras no basadas en aprendizaje profundo, manteniendo tiempos de entrenamiento razonables. También mostró una fuerte resiliencia cuando se añadió ruido artificial, degradándose más suavemente que modelos rivales.
Qué significa esto para los sistemas cotidianos
En términos sencillos, TS2Vision demuestra que tratar las series temporales como imágenes diseñadas con cuidado puede liberar el poder de la visión por ordenador para datos temporales. Al combinar una forma estable y adaptativa de dibujar señales como imágenes con un potente modelo de visión, el marco ofrece un método unificado que funciona con muchos tipos de sensores y longitudes de secuencia. Para los desarrolladores de sistemas de monitorización y toma de decisiones, esto supone una herramienta más general que puede manejar datos variados y ruidosos manteniéndose lo bastante eficiente para su uso práctico.
Cita: Ren, X., Li, D., Gao, X. et al. A unified time series classification framework via adaptive Gaussian image representation. Sci Rep 16, 14817 (2026). https://doi.org/10.1038/s41598-026-44760-6
Palabras clave: clasificación de series temporales, representación en imagen, vision transformer, sensores multivariantes, codificación robusta