Clear Sky Science · zh
SCB-YOLO:一种适用于复杂课堂场景的轻量自适应注意力增强网络,用于学生行为检测
以新的方式观察课堂
教师长期以来依靠目光和直觉来判断学生是在听讲、阅读还是静静走神。但在如今人满为患且以数据为导向的学校环境中,一个人几乎不可能实时追踪每个孩子的行为。本文提出了 SCB-YOLO——一个紧凑的人工智能系统,能够从普通课堂视频中自动检测关键学生行为(如举手、阅读或写作),即便在光线差、拥挤或视觉杂乱的情况下也能工作。目标不是替代教师,而是为他们提供一条稳定、客观的学生参与情况信息流,从而为更个性化和更有响应性的教学打开可能性。
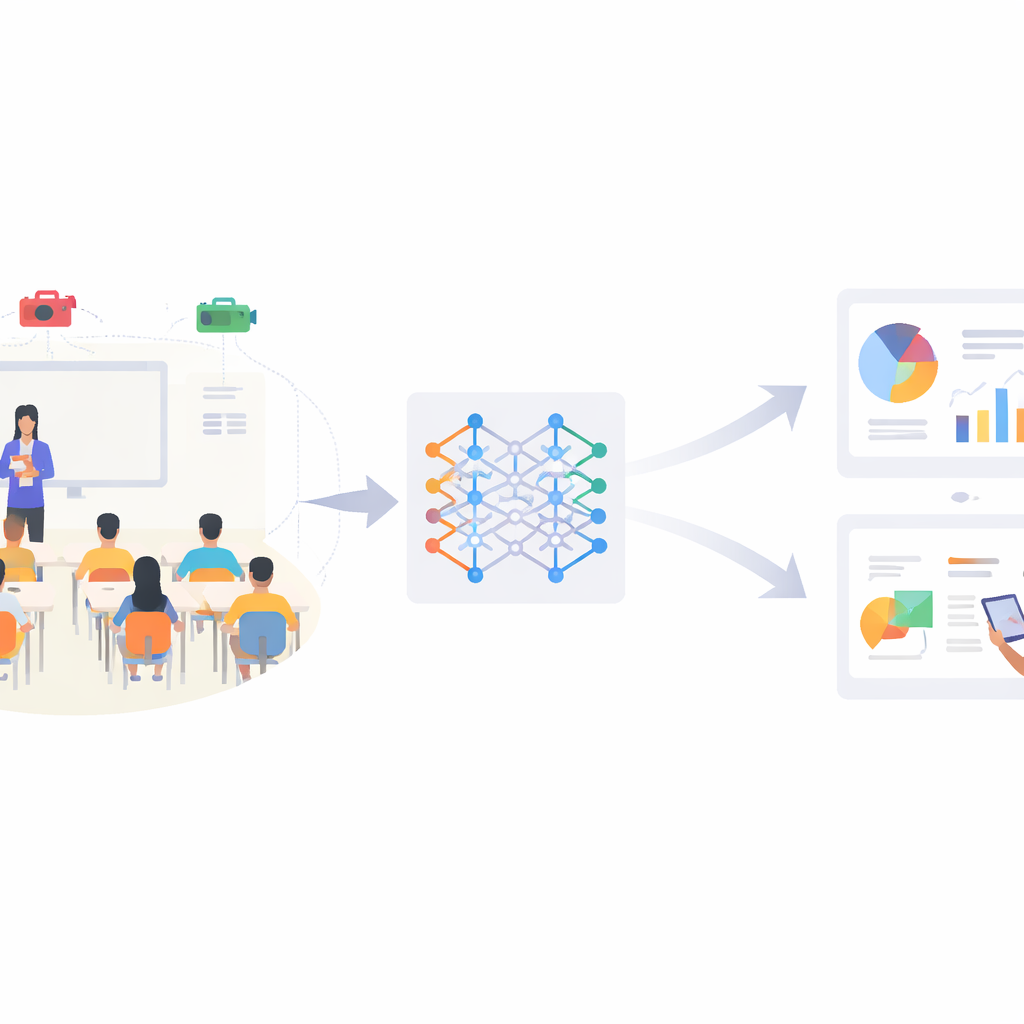
学生动作为何重要
简单的课堂动作包含着出乎意料的信息量。频繁举手、持续阅读和专注写作与学生的学习效果和参与感高度相关。传统上,教师或观察者会手工记录这些行为,这一过程既缓慢又主观,难以扩展到多堂课。早期自动化尝试使用可穿戴传感器或教室内的专用硬件,但这些设备具有侵入性、成本高且引发隐私担忧。相比之下,现代计算机视觉可以利用许多学校已有的普通视频流,从原始像素中提取学生行为记录,而不会干扰课堂。
从原始视频到识别行为
SCB-YOLO 构建于一类流行的视觉模型家族 YOLO 之上,该类模型能在一次快速通行中识别并定位图像中的对象。作者基于轻量的 YOLOv11n 变体进行调整,并专门为小学生课堂进行重塑——该场景光照不均、课桌和墙面杂乱、学生常相互遮挡。他们的数据集 SCB-Dataset3-S 包含超过 5000 张真实课堂图像,并标注了三类核心行为:举手、阅读和写作。之所以选择这些类别,是因为它们既在教育上重要,又在视觉上具有挑战性——尤其是将写作与阅读区分开来,往往只依赖手部和头部位置的细微变化。
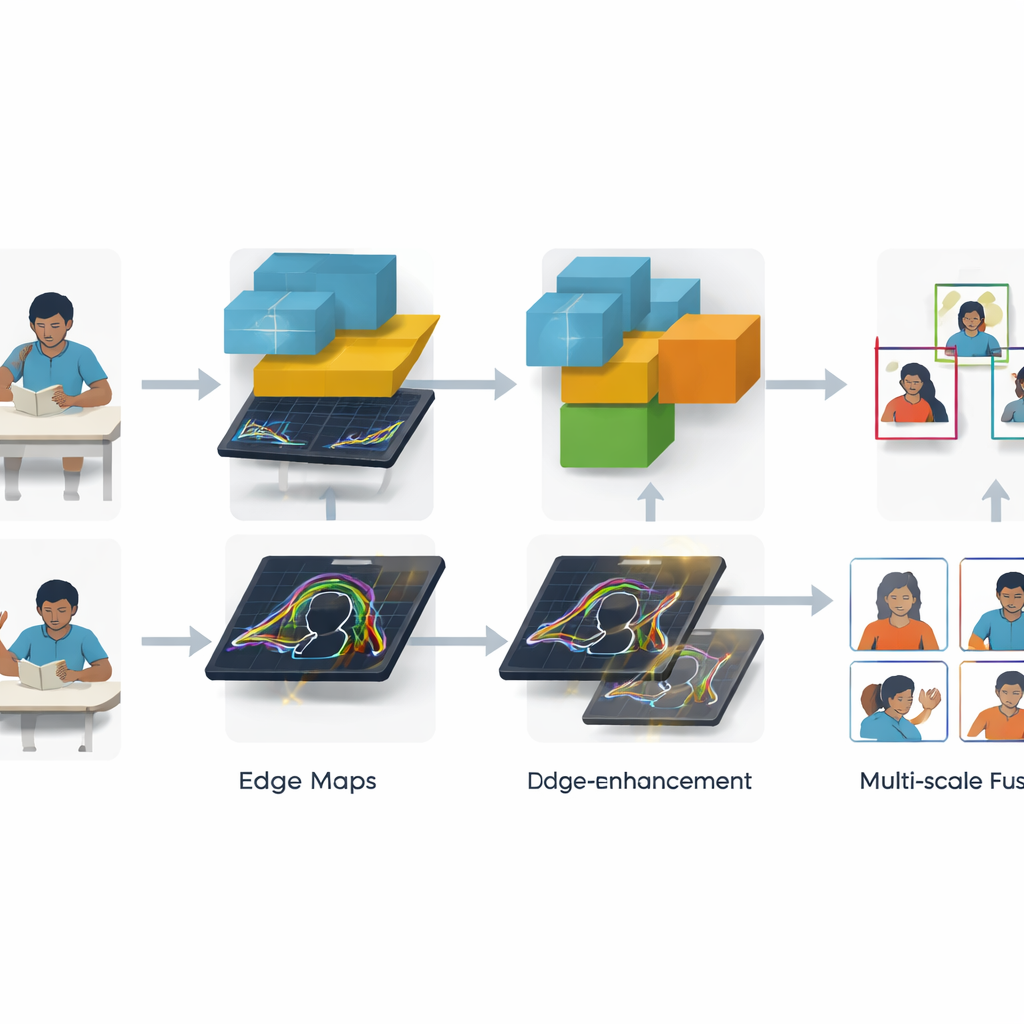
锐化边缘与融合多尺度信息
两项关键创新帮助 SCB-YOLO 应对杂乱的真实场景。其一,全局边缘信息传递模块(Global Edge Information Transfer)聚焦轮廓与边界——例如高举手臂的轮廓或手与笔记本之间的边缘。通过不是直接对原始图像而是对早期网络特征应用经典边缘滤波,然后将这些精炼的边缘信息输入更深层,系统在对举手和写作等行为画出紧密框时表现更好,即便学生体积小或部分被遮挡。其二,新引入的 MANet_Star 融合模块更智能地结合不同图像尺度的信息。它通过若干轻量分支传递特征,模拟注意力机制,提升最有信息量的模式,同时保持整体模型紧凑,利于实时运行。
系统表现如何
在 SCB-Dataset3-S 基准上,SCB-YOLO 优于多种其他精简的 YOLO 模型。与其 YOLOv11n 起点相比,标准准确度指标(mAP@0.5)提高了 2.6 个百分点,达到 71.8%,且仍能以视频速率运行。增益在最难的类别——写作上尤为显著,该类别的准确率提升最大,且与阅读的混淆明显减少。对网络内部热图的可视化分析显示,与基线相比,SCB-YOLO 更精确地聚焦于书本、手部和头部,尤其是在识别小体积或远处学生时。在从强力桌面显卡到紧凑 Jetson 边缘模块等不同设备上的测试表明,该系统在现实部署中能够舒适地超过实时帧率。
这对未来课堂意味着什么
对非专业读者来说,主要结论是:现在可以构建不仅能记录课堂、还能在基础层面理解学生行为和参与度的教室摄像系统。SCB-YOLO 表明,通过精心设计的模块以锐化边缘并跨尺度融合信息,相对较小的 AI 模型就能在拥挤且不完美的条件下可靠地识别关键学习行为。在不久的将来,这类系统可为学习分析和辅导平台提供数据,提醒教师注意力下降时刻、指出哪些课程让学生失去兴趣,并支持更有针对性的教学。在负责任地使用并采取强有力隐私保护措施的前提下,这项技术有望成为帮助每个孩子获得所需关注的安静但强大的助手。
引用: Guo, C., Yuan, B., Xie, J. et al. SCB-YOLO: a lightweight adaptive attention-enhanced network for student behavior detection in complex classroom settings. Sci Rep 16, 13309 (2026). https://doi.org/10.1038/s41598-026-43753-9
关键词: 智慧课堂, 学生参与度, 计算机视觉, 行为检测, 轻量深度学习