Clear Sky Science · fr
SCB-YOLO : un réseau léger, adaptatif et renforcé par attention pour la détection des comportements d’élèves dans des situations de classe complexes
Observer la classe autrement
Les enseignants se sont toujours appuyés sur leurs yeux et leur instinct pour juger si les élèves écoutent, lisent ou décrochent silencieusement. Mais dans les classes surchargées et les établissements axés sur les données d’aujourd’hui, il est presque impossible pour une seule personne de suivre en temps réel le comportement de chaque enfant. Cet article présente SCB-YOLO, un système d’intelligence artificielle compact capable de détecter automatiquement des comportements clés des élèves — comme lever la main, lire ou écrire — à partir de vidéos de classe ordinaires, même en cas de faible éclairage, d’affluence ou d’encombrement visuel. L’objectif n’est pas de remplacer les enseignants, mais de leur fournir un flux d’information fiable et objectif sur l’engagement des élèves, ouvrant la voie à un enseignement plus personnalisé et réactif.
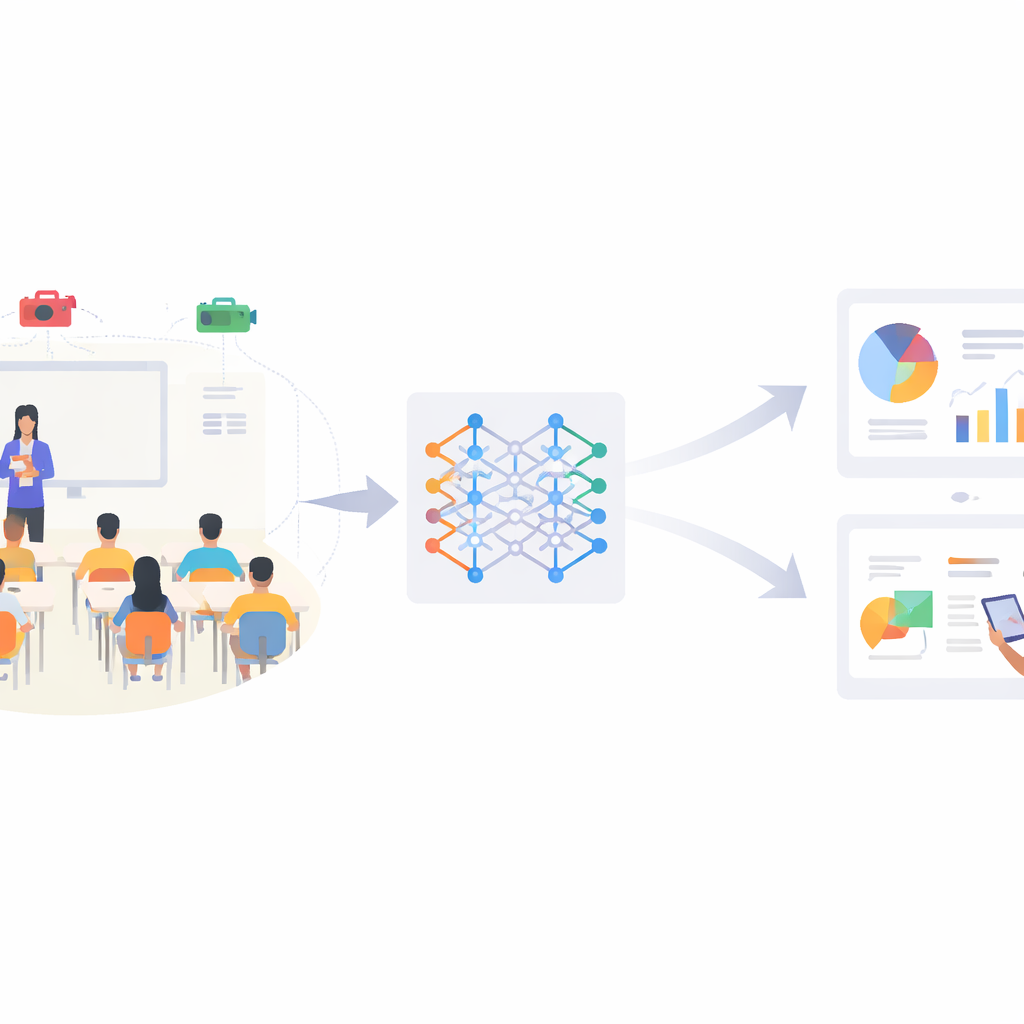
Pourquoi les gestes des élèves sont importants
Les gestes simples en classe portent une quantité surprenante d’informations. Le fait de lever fréquemment la main, de lire régulièrement ou d’écrire avec concentration est fortement lié aux apprentissages et au sentiment d’engagement des élèves. Classiquement, les enseignants ou observateurs enregistraient ces comportements à la main, un processus lent, subjectif et difficile à étendre au‑delà de quelques leçons. Les premières tentatives d’automatisation utilisaient des capteurs portables ou du matériel spécifique dans la salle, mais ces dispositifs étaient intrusifs, coûteux et soulevaient des problèmes de vie privée. En revanche, la vision par ordinateur moderne peut s’appuyer sur des flux vidéo ordinaires déjà présents dans de nombreuses écoles, transformant des pixels bruts en un registre du comportement des élèves sans perturber le cours.
De la vidéo brute au comportement reconnu
SCB-YOLO s’appuie sur une famille populaire de modèles de vision connue sous le nom de YOLO, capable de repérer et localiser des objets dans une image en un seul passage rapide. Les auteurs adaptent la variante légère YOLOv11n et la réorientent spécifiquement pour les classes élémentaires, où l’éclairage est inégal, les bureaux et les murs encombrés, et les élèves se masquent souvent les uns les autres. Leur jeu de données, SCB-Dataset3-S, contient plus de 5 000 images de classes réelles étiquetées selon trois comportements centraux : lever la main, lire et écrire. Ces catégories ont été choisies parce qu’elles sont à la fois pédagogiquement importantes et visuellement difficiles à distinguer — en particulier différencier l’écriture de la lecture, qui peut ne varier que par de subtiles positions de la main et de la tête.
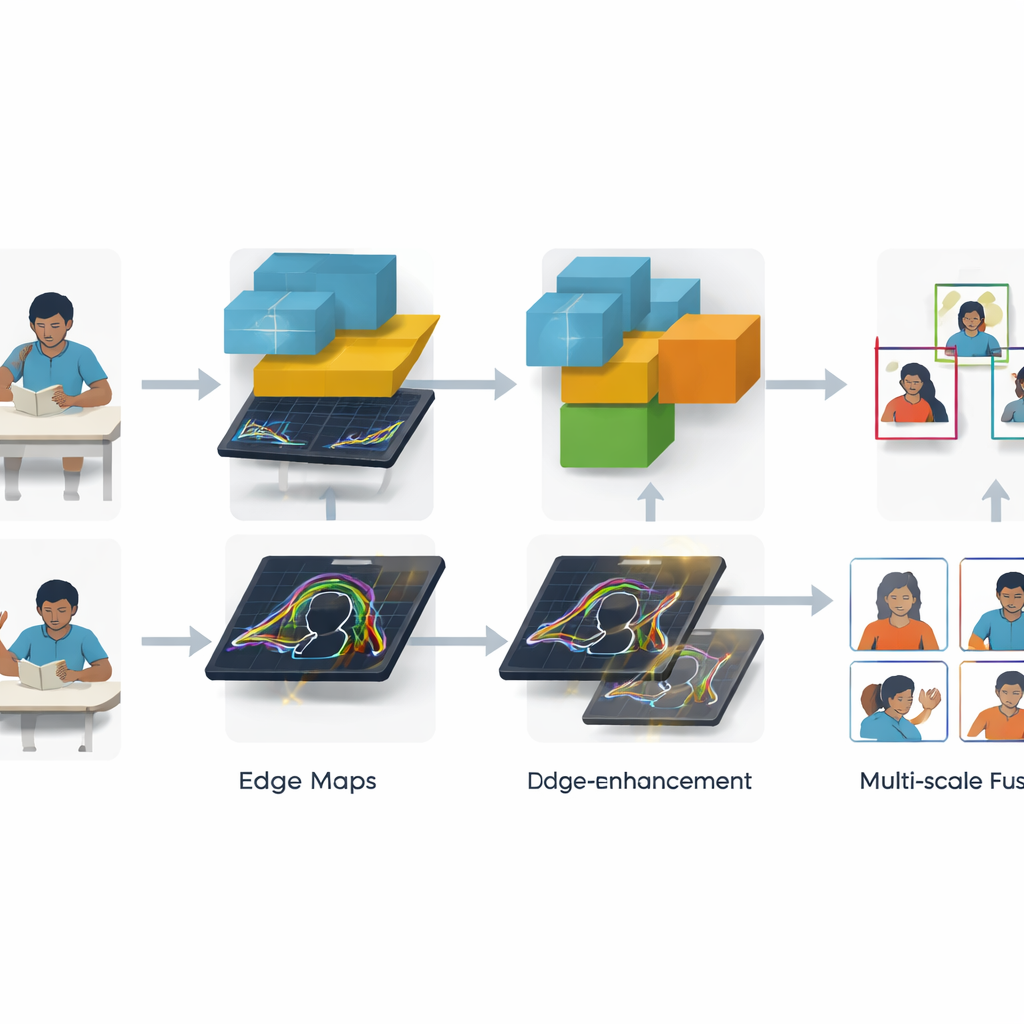
Aiguiser les contours et mêler les échelles
Deux innovations clés aident SCB-YOLO à faire face à des scènes réelles désordonnées. D’abord, un module de Transfert d’Information Globale sur les Contours se concentre sur les silhouettes et les contours — comme la bordure d’un bras levé ou la démarcation entre une main et un carnet. En appliquant des filtres de contours classiques non pas directement à l’image brute mais aux premières caractéristiques extraites par le réseau, puis en injectant ces contours affinés dans les couches plus profondes, le système devient meilleur pour dessiner des boîtes serrées autour de comportements tels que lever la main et écrire, même quand les élèves sont petits ou partiellement cachés. Ensuite, un nouveau module de fusion MANet_Star combine l’information provenant de différentes échelles d’image de manière plus intelligente. Il achemine les caractéristiques à travers plusieurs branches légères imitant l’attention, renforçant les motifs les plus informatifs tout en maintenant le modèle suffisamment compact pour une utilisation en temps réel.
Quel est le niveau de performance du système
Sur le benchmark SCB-Dataset3-S, SCB-YOLO surpasse un large éventail d’autres modèles YOLO allégés. Il améliore une mesure standard d’exactitude (mAP@0.5) de 2,6 points de pourcentage par rapport à son point de départ YOLOv11n, atteignant 71,8 % tout en fonctionnant à des vitesses compatibles avec la vidéo. Les gains sont particulièrement importants pour le cas le plus difficile — l’écriture — où la précision augmente plus que pour toute autre catégorie et où la confusion avec la lecture est fortement réduite. Des analyses visuelles des cartes de chaleur internes du réseau montrent qu’en comparaison avec la base, SCB-YOLO se concentre plus précisément sur les livres, les mains et les têtes, en particulier pour les élèves petits ou éloignés. Des tests sur des appareils allant d’une puissante carte graphique de bureau à un module Jetson compact montrent que le système peut fonctionner confortablement au‑dessus des débits temps réel dans des déploiements réalistes.
Ce que cela signifie pour les classes de demain
Pour les non‑spécialistes, la principale conclusion est qu’il est désormais possible de concevoir des caméras de classe qui font plus que filmer — elles peuvent comprendre, de façon basique, ce que font les élèves et quel est leur niveau d’engagement. SCB-YOLO montre qu’avec des modules conçus pour affiner les contours et fusionner l’information à travers les échelles, un modèle d’IA relativement petit peut repérer de manière fiable des comportements d’apprentissage clés dans des conditions encombrées et imparfaites. Dans un avenir proche, de tels systèmes pourraient alimenter des outils d’analytique d’apprentissage et de tutorat, alertant les enseignants quand l’attention baisse, mettant en évidence les leçons qui perdent les élèves et soutenant un enseignement plus personnalisé. Utilisée de manière responsable et avec de fortes garanties de confidentialité, cette technologie pourrait devenir un allié discret mais puissant pour aider chaque enfant à recevoir l’attention dont il a besoin.
Citation: Guo, C., Yuan, B., Xie, J. et al. SCB-YOLO: a lightweight adaptive attention-enhanced network for student behavior detection in complex classroom settings. Sci Rep 16, 13309 (2026). https://doi.org/10.1038/s41598-026-43753-9
Mots-clés: salle de classe intelligente, engagement des élèves, vision par ordinateur, détection de comportements, apprentissage profond léger