Clear Sky Science · it
SCB-YOLO: una rete leggera adattiva con attenzione migliorata per il rilevamento del comportamento degli studenti in ambienti scolastici complessi
Osservare la classe in modo nuovo
Gli insegnanti si sono sempre affidati alla vista e all’istinto per giudicare se gli studenti stanno ascoltando, leggendo o semplicemente fissando nel vuoto. Ma nelle classi affollate e nelle scuole orientate ai dati di oggi è quasi impossibile per una sola persona monitorare il comportamento di ogni bambino in tempo reale. Questo articolo presenta SCB-YOLO, un sistema di intelligenza artificiale compatto che può individuare automaticamente i comportamenti chiave degli studenti — come alzare la mano, leggere o scrivere — da video di classe ordinari, anche in condizioni di scarsa illuminazione, affollamento e distrazioni visive. L’obiettivo non è sostituire gli insegnanti, ma fornire loro un flusso di informazioni costante e oggettivo su come gli studenti partecipano, aprendo la strada a un insegnamento più personalizzato e reattivo.
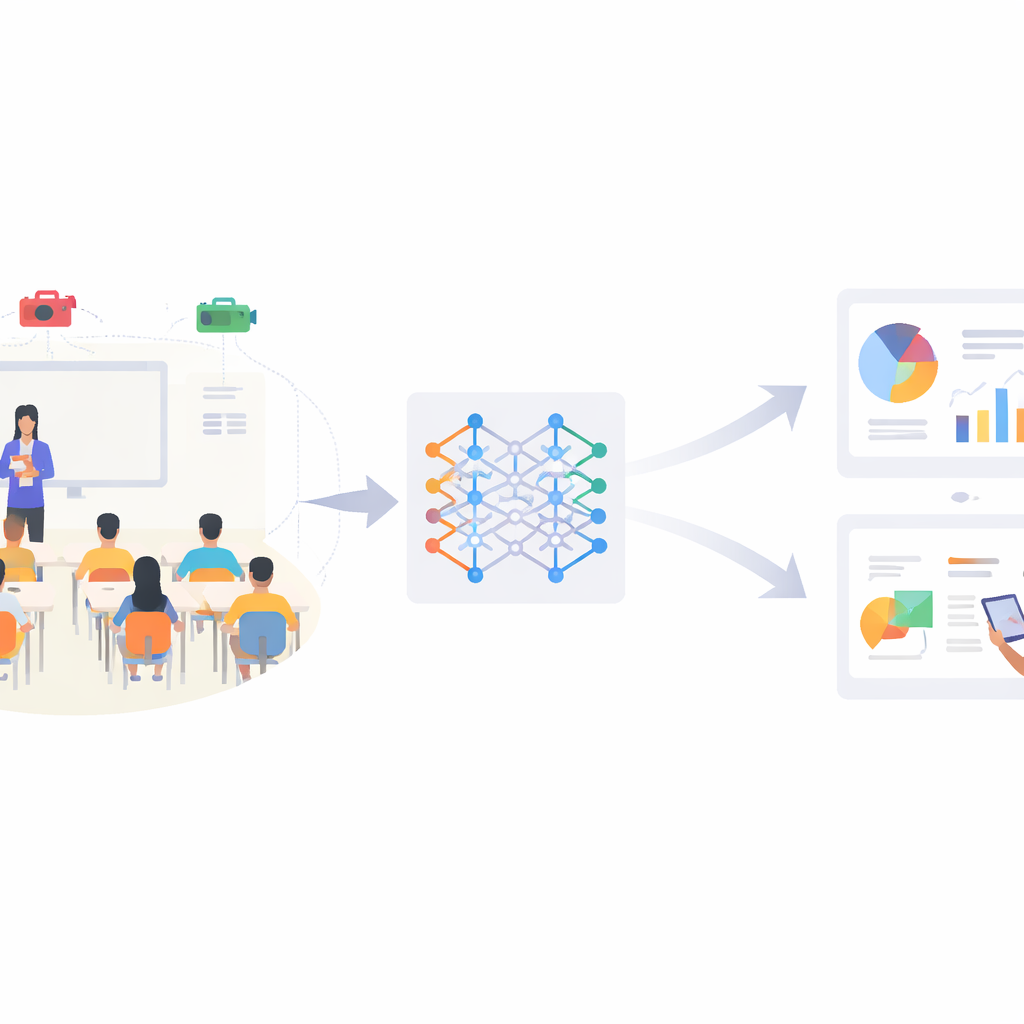
Perché i comportamenti degli studenti contano
Azioni semplici in classe trasmettono una quantità sorprendente di informazioni. L’alzare spesso la mano, la lettura costante e la scrittura concentrata sono fortemente correlate a quanto gli studenti apprendono e a quanto si sentono coinvolti. Tradizionalmente, insegnanti o osservatori cercavano di registrare questi comportamenti a mano, un processo lento, soggettivo e difficile da scalare oltre poche lezioni. I primi tentativi di automatizzare il processo utilizzavano sensori indossabili o hardware speciale nella stanza, ma questi dispositivi erano invadenti, costosi e sollevavano preoccupazioni sulla privacy. Al contrario, la visione artificiale moderna può operare su flussi video ordinari già presenti in molte scuole, trasformando i pixel grezzi in un registro del comportamento degli studenti senza interrompere la classe.
Dal video grezzo al comportamento riconosciuto
SCB-YOLO si basa su una famiglia popolare di modelli di visione nota come YOLO, che è in grado di individuare e localizzare oggetti in un’immagine in un’unica rapida passata. Gli autori adattano la variante leggera YOLOv11n e la rimodellano specificamente per le classi delle scuole elementari, dove l’illuminazione è irregolare, i banchi e le pareti sono ingombri e gli studenti spesso si sovrappongono visivamente. Il loro dataset, SCB-Dataset3-S, contiene più di 5.000 immagini reali di aula etichettate con tre comportamenti fondamentali: alzare la mano, leggere e scrivere. Queste categorie sono state scelte perché sono sia rilevanti dal punto di vista educativo sia visivamente impegnative — in particolare distinguere la scrittura dalla lettura, che può differire solo per sottili variazioni nella posizione della mano e della testa.
Affilare i contorni e fondere le scale
Due innovazioni chiave aiutano SCB-YOLO a gestire scene reali disordinate. Primo, un modulo di Trasferimento Globale delle Informazioni di Contorno si concentra su sagome e contorni — come il profilo di un braccio alzato o il bordo tra una mano e un quaderno. Applicando filtri di contorno classici non direttamente sull’immagine grezza ma su caratteristiche iniziali della rete, e poi alimentando questi contorni raffinati negli strati più profondi, il sistema diventa più abile a tracciare riquadri precisi attorno a comportamenti come l’alzare la mano e lo scrivere, anche quando gli studenti sono piccoli o parzialmente nascosti. Secondo, un nuovo modulo di fusione MANet_Star combina le informazioni provenienti da diverse scale d’immagine in modo più intelligente. Invía le caratteristiche attraverso diversi rami leggeri che imitano l’attenzione, potenziando i pattern più informativi mantenendo il modello complessivo abbastanza compatto per l’uso in tempo reale.
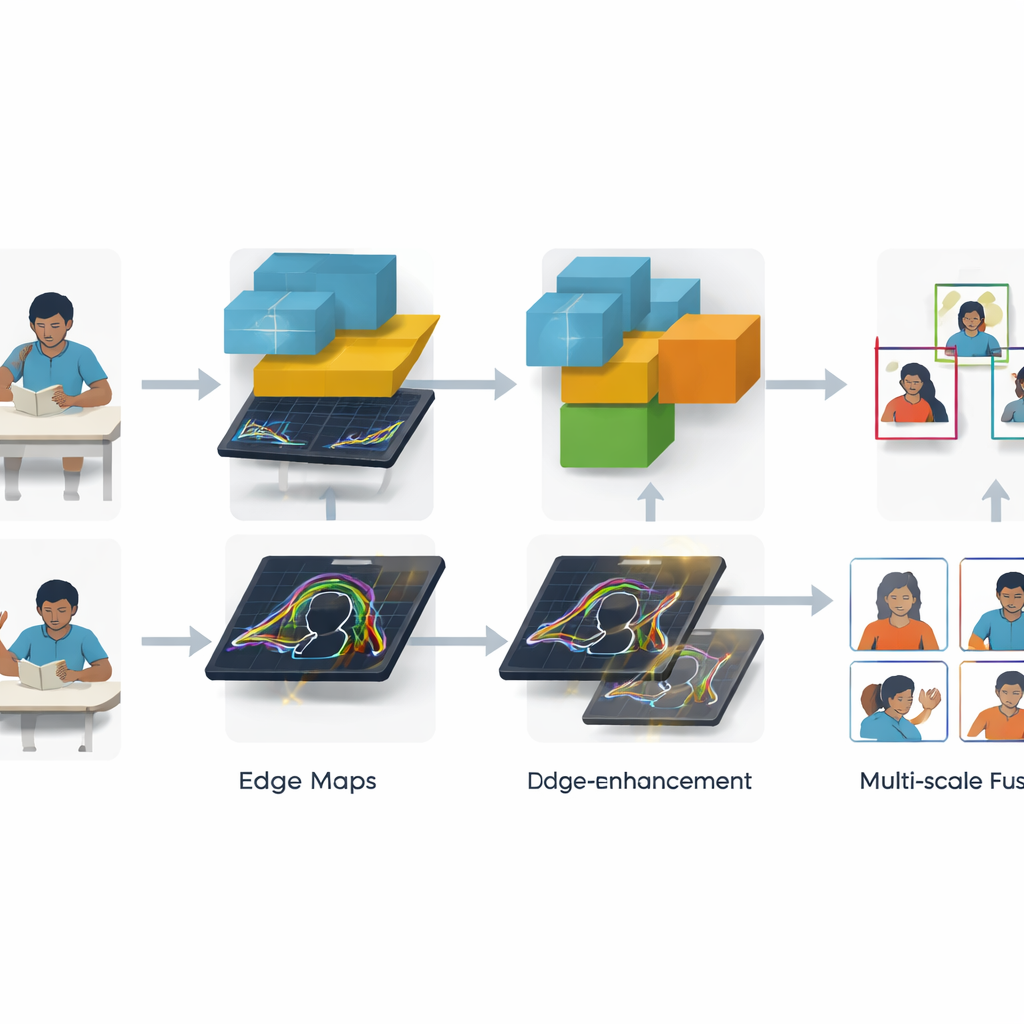
Quanto bene funziona il sistema
Sul benchmark SCB-Dataset3-S, SCB-YOLO supera un’ampia gamma di altri modelli YOLO snelli. Migliora una misura standard di accuratezza (mAP@0.5) di 2,6 punti percentuali rispetto al suo punto di partenza YOLOv11n, raggiungendo il 71,8 percento pur operando a velocità video. I guadagni sono particolarmente rilevanti per il caso più difficile — la scrittura — dove l’accuratezza aumenta più che in qualsiasi altra categoria e la confusione con la lettura si riduce nettamente. Analisi visive delle mappe di calore interne alla rete mostrano che, rispetto al modello di base, SCB-YOLO si concentra con maggiore precisione su libri, mani e teste, in particolare per studenti piccoli o distanti. Test su dispositivi che vanno da una potente scheda grafica desktop a un compatto modulo edge Jetson mostrano che il sistema può funzionare comodamente sopra i tassi in tempo reale in scenari d’uso realistici.
Cosa significa per le classi future
Per i non specialisti, la conclusione principale è che oggi è fattibile costruire videocamere di classe che fanno più che registrare — possono comprendere, in modo basilare, cosa fanno gli studenti e quanto sembrano coinvolti. SCB-YOLO dimostra che con moduli progettati con cura per affinare i contorni e fondere informazioni su diverse scale, un modello di IA relativamente piccolo può identificare in modo affidabile i comportamenti chiave dell’apprendimento in condizioni affollate e imperfette. Nel prossimo futuro, tali sistemi potrebbero integrarsi in piattaforme di analytics dell’apprendimento e tutoraggio, segnalando agli insegnanti quando l’attenzione cala, evidenziando le lezioni che fanno perdere gli studenti e supportando un’istruzione più mirata. Utilizzata responsabilmente e con solide garanzie sulla privacy, questa tecnologia potrebbe diventare un alleato discreto ma potente per assicurare a ogni bambino l’attenzione di cui ha bisogno.
Citazione: Guo, C., Yuan, B., Xie, J. et al. SCB-YOLO: a lightweight adaptive attention-enhanced network for student behavior detection in complex classroom settings. Sci Rep 16, 13309 (2026). https://doi.org/10.1038/s41598-026-43753-9
Parole chiave: classe intelligente, coinvolgimento degli studenti, computer vision, rilevamento del comportamento, deep learning leggero