Clear Sky Science · zh
基于本体的关联规则挖掘用于生物医学实体关系:整合层级知识以改进基因-疾病发现
为何隐性基因–疾病关联很重要
现代医学越来越依赖于识别哪些基因与哪些疾病相关。这些关联可以揭示疾病发生的原因、指示新的药物靶点并识别高风险人群。然而,大多数计算工具仅查找在同一句话或同一篇论文中共同出现的基因和疾病,从而错过许多微妙但重要的联系。本研究提出了一种新的生物医学文献挖掘方法,利用专家构建的知识层级,旨在更可靠地发现既有共识又被忽视的基因–疾病关系。
从原始文本到候选关联
作者首先收集了大量来自PubMed的科学文章,并将每篇文章拆分为句子。每个句子被视为一个包含若干项的小“篮子”,可能含有一个或多个基因名和一个或多个疾病名。利用成熟的数据挖掘算法(Apriori、FP-Growth 和 Eclat),他们扫描了数百万个此类篮子,以发现比随机出现更频繁共同出现的基因–疾病对。这个第一步称为实体特异性关联,捕捉了大多数现有工具所依赖的直接共现。该步骤已揭示数千个潜在关联,但仍偏向文献中被大量研究的基因和常见疾病。
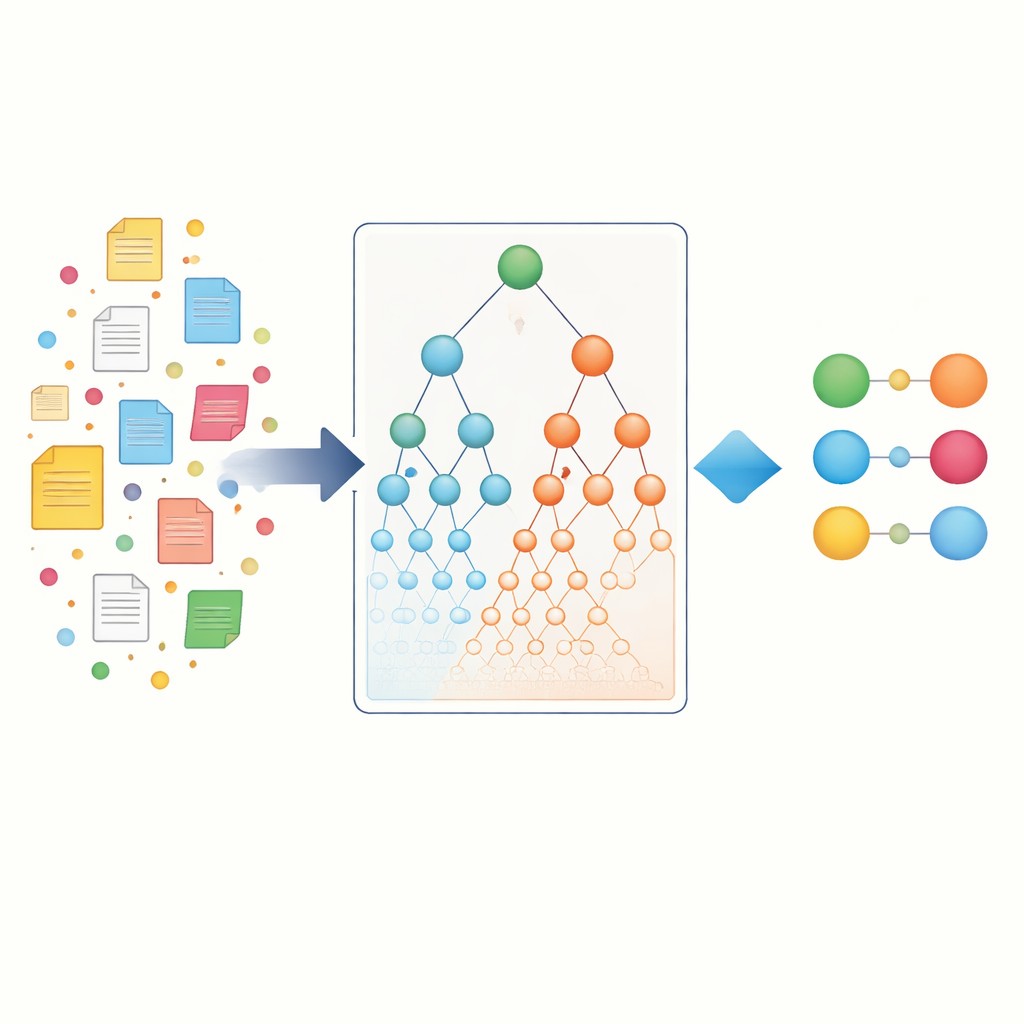
将生物学层级作为地图
为了超越简单的词频统计,研究人员转向了被称为本体的生物学“地图”。基因本体(Gene Ontology)描述基因的功能及其在细胞中的作用位置,而疾病本体(Disease Ontology)将疾病组织为家族和亚型。在这些层级中,像罕见癫痫这样的特定术语位于更广泛父项如“神经系统疾病”之下。关键思想是,如果某个基因与非常具体的疾病有强烈关联,而该疾病属于更大的疾病家族,那么该基因很可能也与整个家族存在某种关系。作者通过构建层级本体关联来形式化这一点,将证据沿基因和疾病两侧向上传播,同时也间接捕捉共享父项的“同级”条目。
混合直接证据与继承信号
简单地将来自多个层级的计数相加会扭曲评分,尤其是像“癌症”这样非常通用的术语出现频率极高。为此,团队设计了一个谨慎的评分系统。他们使用数据挖掘中的标准度量——提升度(lift)来评估基因与疾病超出随机的关联强度,然后对这些分数进行转换以减少偏态并使其可比。他们提出的 Athar 语义增强关联(ASEA)分数融合了三个要素:直接的基因–疾病关联、基因与更广疾病家族之间的关联,以及更广泛基因功能与疾病家族之间的关联。他们还应用基于秩的归一化,使得分数在本体不同深度间具有可比性,从而实现公平的比较与排序。
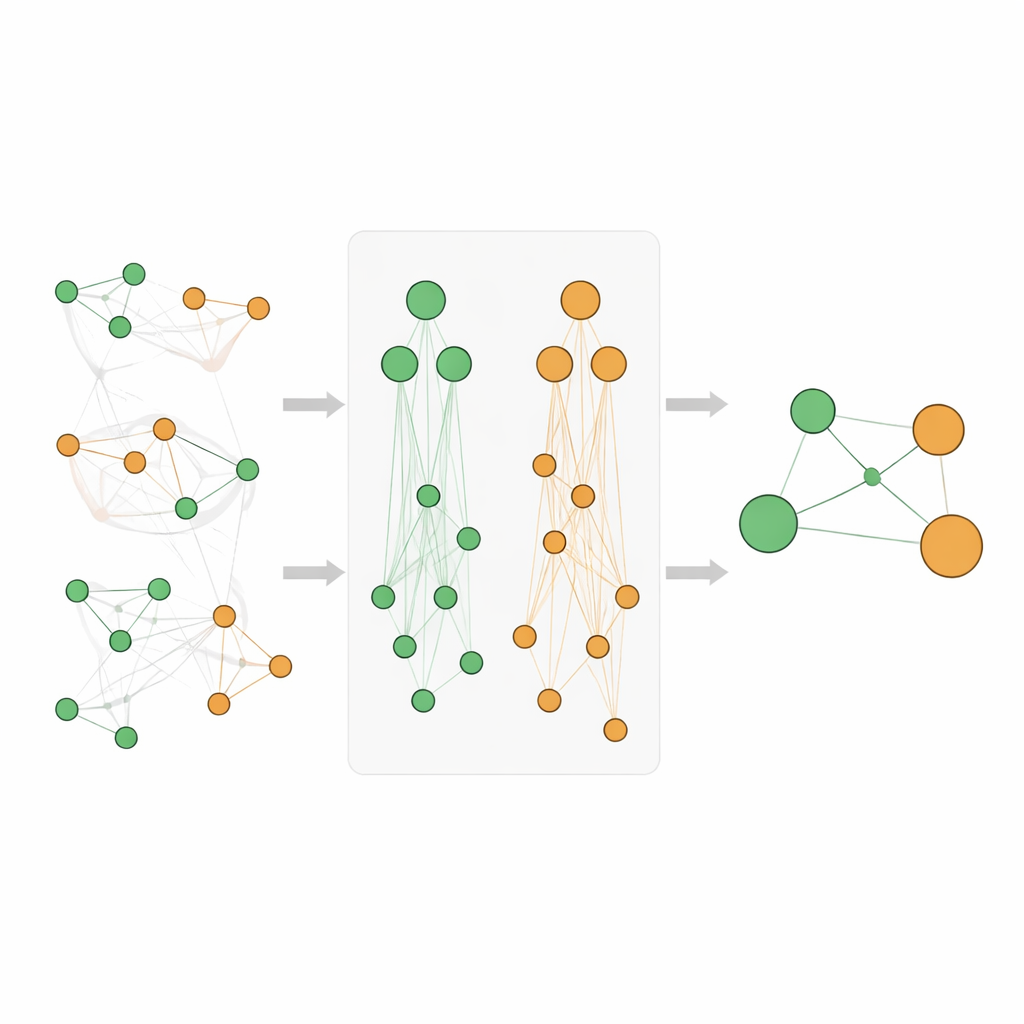
将方法与可信数据库进行比对测试
为评估 ASEA 是否产生生物学上有意义的结果,作者将其高排名的关联与专家策划资源(例如 Comparative Toxicogenomics Database 与 DisGeNET)中的条目进行比对。他们发现,相较于任何单一经典算法,ASEA 能恢复更多高质量的已知关联,同时仍生成大量额外的候选链接。总体而言,ASEA 识别出 185 对显著的基因–疾病配对。这些配对被分为四类:已在主要数据库中确立的连接;由近期研究强力支持但尚未被人工收录的连接;仅有薄弱或零散数据库支持的连接;以及当前没有支持、纯粹作为未来实验或临床验证假设的推测性关联。
这对未来医学意味着什么
对非专业读者而言,关键的信息是该框架提供了一种在大规模文本中更智能地“阅读”生物医学文献的方法。它不只是统计基因和疾病并列出现的明显提及,而是利用关于基因与疾病如何被组织成家族的专家知识来强化那些有希望但罕见的信号。所得的 ASEA 分数并不能证明某基因导致某疾病,但它提供了一个透明且有统计依据的候选清单,供科学家和临床医生进一步调查。从长远看,这种面向本体的挖掘方法可能加速生物标志物的发现,推动精准医学,并将日益增长的生物医学文本转化为可操作的医学洞见。
引用: Naqash, M.A., Amin, M., Uddin, J. et al. Ontology-driven association rule mining for biomedical entity relationships: integrating hierarchical knowledge to improve gene-disease discovery. Sci Rep 16, 13072 (2026). https://doi.org/10.1038/s41598-026-42584-y
关键词: 基因-疾病关联, 生物医学文本挖掘, 本体, 精准医学, 计算生物学