Clear Sky Science · nl
Op ontologie gebaseerde association rule mining voor relaties tussen biomedische entiteiten: hiërarchische kennis integreren om gen-ziekteontdekking te verbeteren
Waarom verborgen gen–ziekteverbindingen ertoe doen
Moderne geneeskunde is in toenemende mate afhankelijk van het vinden welke genen met welke ziekten verbonden zijn. Deze verbanden kunnen onthullen waarom aandoeningen ontstaan, nieuwe medicijndoelen suggereren en wijzen op mensen met een hoger risico. Toch zoeken de meeste computertools alleen naar genen en ziekten die samen in dezelfde zin of publicatie voorkomen, waardoor veel subtiele maar belangrijke relaties worden gemist. Deze studie introduceert een nieuwe manier om de biomedische literatuur te doorzoeken die gebruikmaakt van door experts opgebouwde kennis-hiërarchieën, met als doel zowel bekende als over het hoofd geziene gen–ziekte-relaties betrouwbaarder te ontdekken.
Van ruwe tekst naar kandidaatverbindingen
De auteurs beginnen met het verzamelen van een grote verzameling wetenschappelijke artikelen uit PubMed en verdelen elk artikel in zinnen. Elke zin wordt behandeld als een klein “mandje” met items dat één of meer genamen en één of meer ziektetermen kan bevatten. Met gevestigde data-miningalgoritmen (Apriori, FP-Growth en Eclat) scannen ze miljoenen van deze mandjes om gen–ziekteparen te vinden die vaker samen voorkomen dan op toeval zou berusten. Deze eerste stap, entiteit-specifieke associatie genoemd, legt de directe co-occurrenties vast waarop de meeste bestaande hulpmiddelen vertrouwen. Het levert al duizenden potentiële verbindingen op, maar bevoordeelt nog steeds goed bestudeerde genen en veelvoorkomende ziekten die de literatuur domineren.
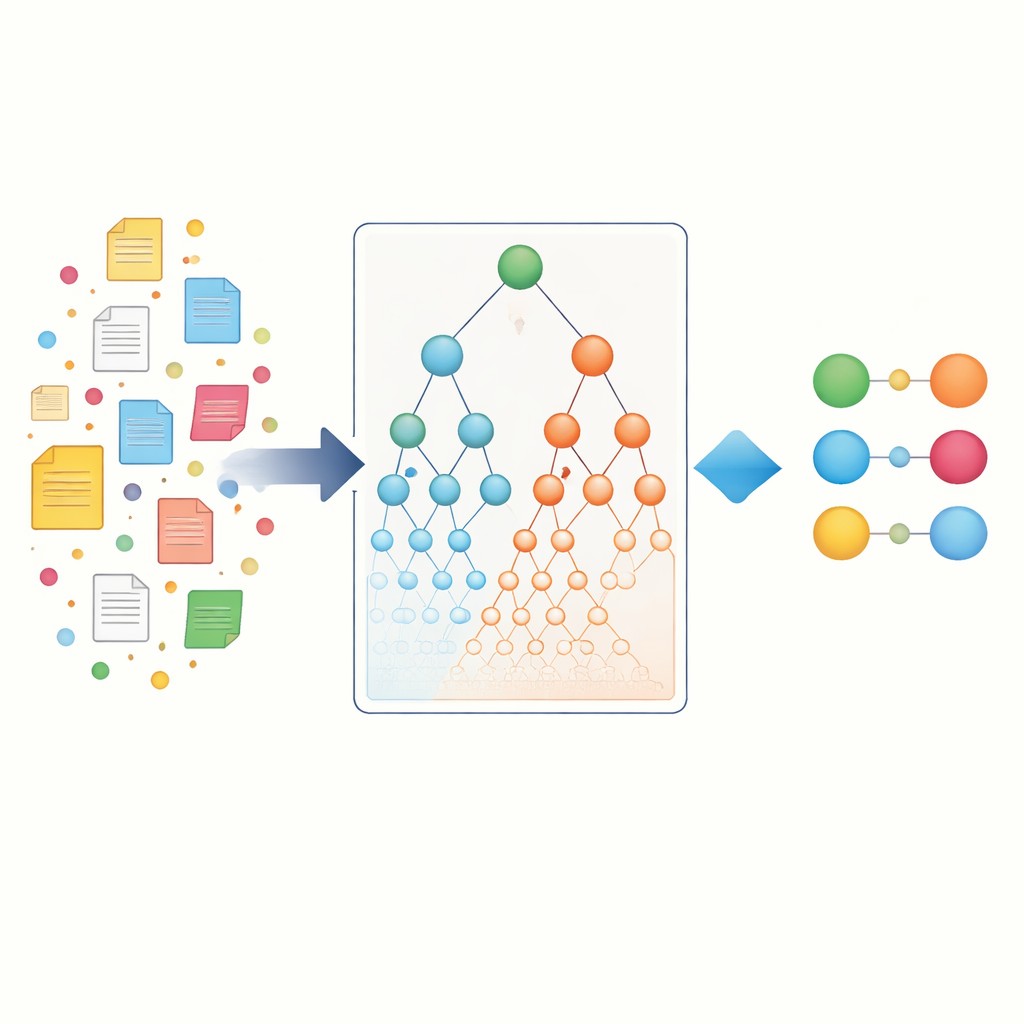
Biologische hiërarchieën als kaart gebruiken
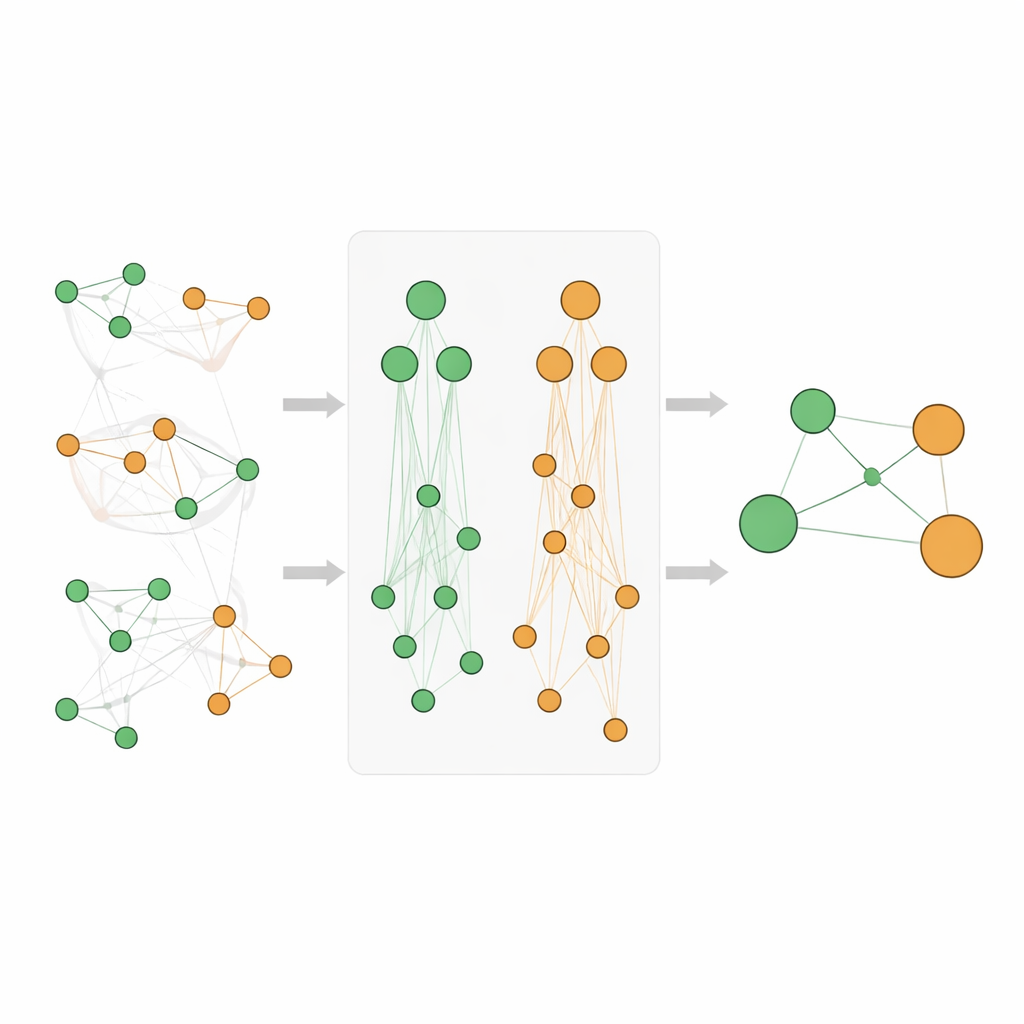
Om verder te gaan dan eenvoudige woordtelling wenden de onderzoekers zich tot biologische “kaarten” die bekendstaan als ontologieën. De Gene Ontology beschrijft wat genen doen en waar ze in de cel actief zijn, terwijl de Disease Ontology ziekten organiseert in families en subtypes. In deze hiërarchieën vallen specifieke termen, zoals een zeldzame epilepsie, onder bredere bovenliggende termen zoals “neurologische ziekte”. Het kernidee is dat als een bepaald gen sterk verbonden is met een zeer specifieke ziekte, en die ziekte behoort tot een grotere familie, het gen waarschijnlijk ook enige relatie heeft met die hele familie. De auteurs formaliseren dit door hiërarchische ontologie-associaties te creëren, die bewijs omhoog laten vloeien via bovenliggende termen aan zowel de gen- als de ziektezijde, en ook indirect “siblings” vastleggen die een ouder delen.
Direct bewijs mengen met geërfde signalen
Het simpelweg optellen van tellingen van vele hiërarchieniveaus kan scores vertekenen, vooral omdat zeer algemene termen zoals “kanker” extreem vaak voorkomen. Het team ontwerpt daarom een zorgvuldige scoresysteem. Ze gebruiken een standaardmaat uit data mining, genaamd lift, om te meten hoe sterk een gen en een ziekte verbonden zijn boven het toeval en transformeren deze scores vervolgens om scheefheid te verminderen en ze vergelijkbaar te maken. Hun nieuwe Athar Semantic-Enriched Association (ASEA)-score mengt drie ingrediënten: de directe gen–ziekteverbinding, verbindingen tussen het gen en bredere ziekte-families, en verbindingen tussen bredere genfuncties en ziekte-families. Ze passen ook ranggebaseerde normalisatie toe zodat scores zich vergelijkbaar gedragen over verschillende dieptes van de ontologieën, wat eerlijke vergelijking en rangschikking mogelijk maakt.
De methode testen aan de hand van vertrouwde databases
Om te beoordelen of ASEA biologisch zinvolle resultaten oplevert, vergelijken de auteurs hun top-gerangschikte associaties met vermeldingen in door experts samengestelde bronnen zoals de Comparative Toxicogenomics Database en DisGeNET. Ze constateren dat ASEA meer hoogkwalitatieve bekende associaties terugvindt dan elk van de klassieke algoritmen afzonderlijk, terwijl het toch een rijke set aanvullende kandidaatverbindingen genereert. In totaal identificeert ASEA 185 opmerkelijke gen–ziekteparen. Deze worden vervolgens ingedeeld in vier categorieën: goed gevestigde connecties die al in grote databases staan; connecties die stevig worden ondersteund door recente studies maar nog niet gecureerd zijn; verbindingen met slechts zwakke of verspreide databaseondersteuning; en puur speculatieve associaties zonder huidige ondersteuning, die worden voorgesteld als hypothesen voor toekomstig laboratorium- of klinisch onderzoek.
Wat dit betekent voor de geneeskunde van de toekomst
Voor niet-specialisten is de cruciale boodschap dat dit kader een slimere manier biedt om de biomedische literatuur op schaal te lezen. In plaats van alleen duidelijke vermeldingen van een gen en een ziekte naast elkaar te tellen, benut het expertkennis over hoe genen en ziekten in families zijn georganiseerd om veelbelovende maar zeldzame signalen te versterken. De resulterende ASEA-score bewijst niet dat een gen een ziekte veroorzaakt, maar levert een transparante, statistisch onderbouwde shortlist van kandidaten voor wetenschappers en clinici om verder te onderzoeken. Op de lange termijn kan dergelijke ontologie-bewuste mining de ontdekking van biomarkers versnellen, precisiegeneeskunde informeren en helpen de groeiende stroom biomedische tekst om te zetten in bruikbare medische inzichten.
Bronvermelding: Naqash, M.A., Amin, M., Uddin, J. et al. Ontology-driven association rule mining for biomedical entity relationships: integrating hierarchical knowledge to improve gene-disease discovery. Sci Rep 16, 13072 (2026). https://doi.org/10.1038/s41598-026-42584-y
Trefwoorden: gen–ziekte-associaties, biomedische tekstmining, ontologieën, precisiegeneeskunde, computationele biologie