Clear Sky Science · fr
Extraction de règles d’association guidée par ontologie pour les relations entre entités biomédicales : intégrer les connaissances hiérarchiques pour améliorer la découverte gène–maladie
Pourquoi les liens cachés entre gènes et maladies comptent
La médecine moderne dépend de plus en plus de l’identification des gènes associés aux maladies. Ces liens peuvent révéler pourquoi des maladies surviennent, suggérer de nouvelles cibles thérapeutiques et identifier des personnes à risque accru. Pourtant, la plupart des outils informatiques ne recherchent que les gènes et les maladies qui apparaissent ensemble dans une même phrase ou un même article, manquant ainsi de nombreuses connexions subtiles mais importantes. Cette étude présente une nouvelle méthode d’exploration de la littérature biomédicale qui exploite des hiérarchies de connaissances construites par des experts, afin de mettre au jour de manière plus fiable des relations gène–maladie à la fois bien connues et négligées.
Du texte brut aux liens candidats
Les auteurs commencent par rassembler une grande collection d’articles scientifiques issus de PubMed et segmentent chaque article en phrases. Chaque phrase est traitée comme un petit « panier » d’éléments pouvant contenir un ou plusieurs noms de gènes et un ou plusieurs noms de maladies. En utilisant des algorithmes établis de fouille de données (Apriori, FP-Growth et Eclat), ils parcourent des millions de ces paniers pour trouver des paires gène–maladie qui tendent à apparaître ensemble plus souvent que ce que le hasard laisserait prévoir. Cette première étape, appelée association spécifique aux entités, capture les cooccurrences directes sur lesquelles la plupart des outils existants s’appuient. Elle révèle déjà des milliers de connexions potentielles, mais favorise encore les gènes bien étudiés et les maladies fréquentes qui dominent la littérature.
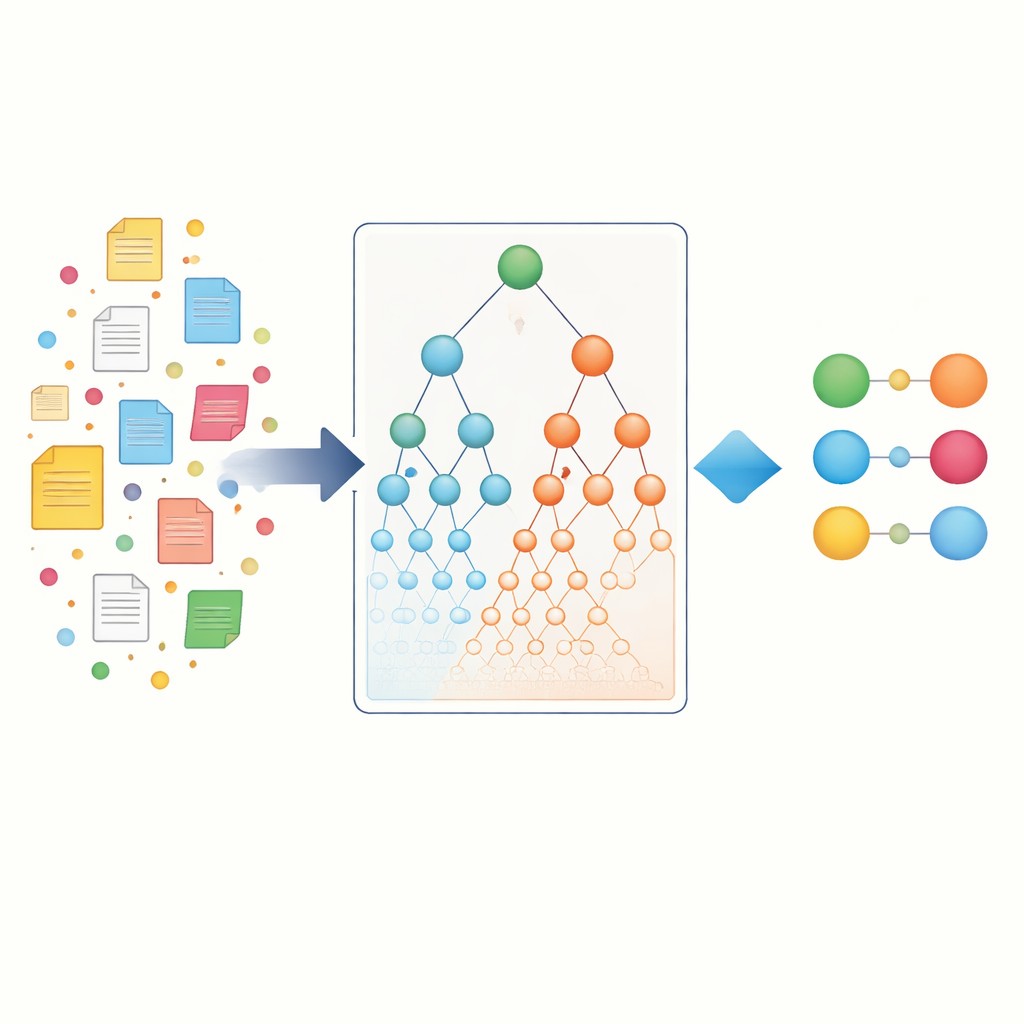
Utiliser les hiérarchies biologiques comme carte
Pour aller au‑delà du simple comptage de mots, les chercheurs se tournent vers des « cartes » biologiques appelées ontologies. Gene Ontology décrit les fonctions des gènes et leurs lieux d’action dans la cellule, tandis que la Disease Ontology organise les maladies en familles et sous‑types. Dans ces hiérarchies, des termes spécifiques comme une épilepsie rare se situent sous des parents plus larges tels que « maladie neurologique ». L’idée clé est que si un gène particulier est fortement lié à une maladie très spécifique, et que cette maladie appartient à une famille plus large, alors le gène est susceptible d’avoir une relation avec l’ensemble de cette famille. Les auteurs formalisent cela en créant des associations ontologiques hiérarchiques, qui propagent les preuves vers les termes parents des deux côtés (gène et maladie) et capturent aussi indirectement des « frères et sœurs » partageant un même parent.
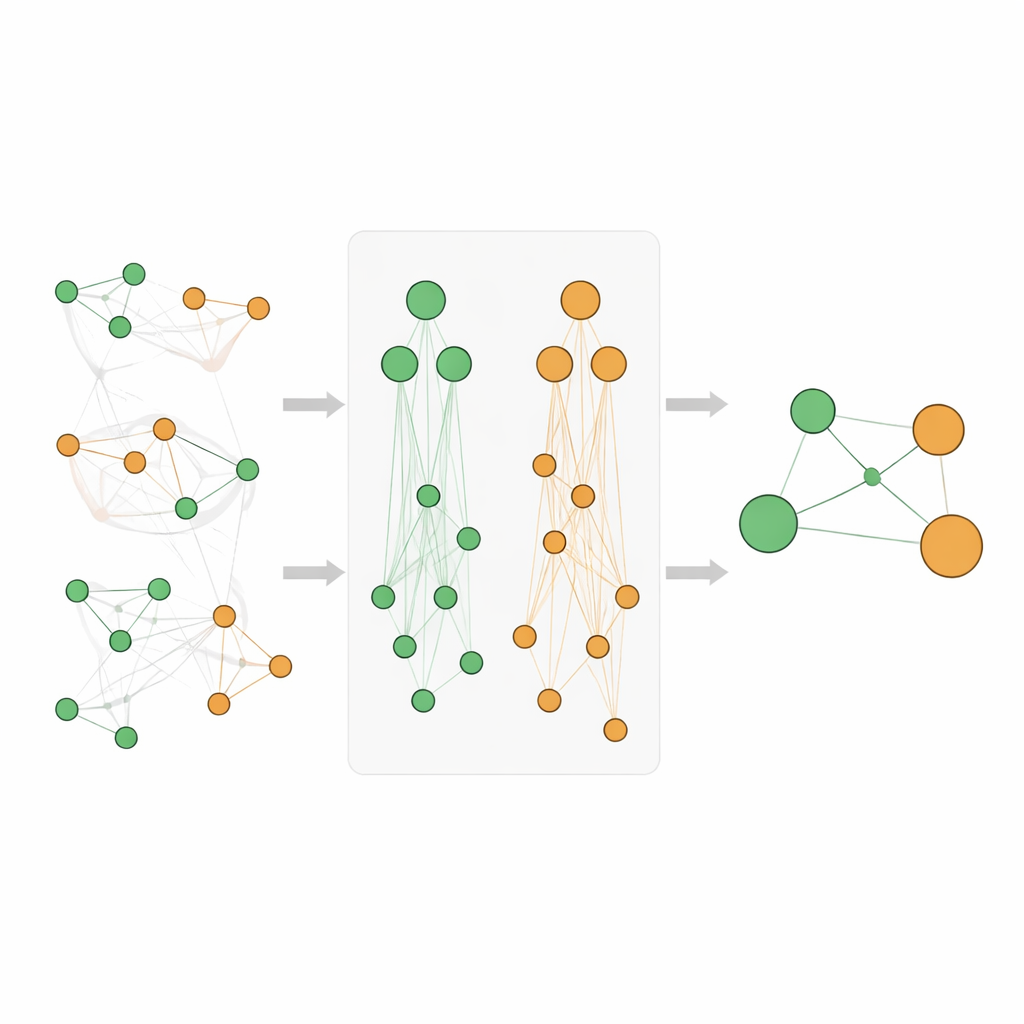
Mélanger les preuves directes et les signaux hérités
Additionner simplement les comptes sur plusieurs niveaux de la hiérarchie peut fausser les scores, d’autant que des termes très généraux comme « cancer » apparaissent extrêmement souvent. L’équipe conçoit donc un système d’évaluation soigneux. Ils utilisent une mesure standard de la fouille de données, appelée lift, pour mesurer la force du lien gène–maladie au‑delà du hasard, puis transforment ces scores pour réduire l’asymétrie et les rendre comparables. Leur nouveau score Athar Semantic-Enriched Association (ASEA) combine trois ingrédients : le lien gène–maladie direct, les liens entre le gène et des familles de maladies plus larges, et les liens entre des fonctions géniques plus générales et des familles de maladies. Ils appliquent également une normalisation basée sur le rang afin que les scores se comportent de façon similaire selon la profondeur des ontologies, permettant une comparaison et un classement équitables.
Tester la méthode sur des bases de données de référence
Pour évaluer si ASEA produit des résultats biologiquement pertinents, les auteurs comparent leurs associations les mieux classées aux entrées de ressources expertisées comme le Comparative Toxicogenomics Database et DisGeNET. Ils constatent qu’ASEA retrouve plus d’associations connues de haut niveau que l’un ou l’autre des algorithmes classiques pris isolément, tout en générant un ensemble riche de liens candidats supplémentaires. Au total, ASEA identifie 185 paires gène–maladie notables. Celles‑ci sont ensuite regroupées en quatre catégories : connexions bien établies déjà présentes dans les grandes bases ; connexions fortement étayées par des études récentes mais pas encore curatées ; liens avec un soutien faible ou dispersé dans les bases ; et associations purement spéculatives sans appui actuel, proposées comme hypothèses pour des travaux futurs en laboratoire ou en clinique.
Ce que cela signifie pour la médecine à venir
Pour les non‑spécialistes, le message essentiel est que ce cadre offre une façon plus intelligente de lire la littérature biomédicale à grande échelle. Plutôt que de ne compter que les mentions évidentes d’un gène et d’une maladie côte à côte, il exploite les connaissances d’experts sur la manière dont gènes et maladies sont organisés en familles pour renforcer des signaux prometteurs mais rares. Le score ASEA obtenu ne prouve pas qu’un gène cause une maladie, mais il fournit une liste courte transparente et fondée statistiquement de candidats à investiguer par des scientifiques et des cliniciens. À long terme, une telle exploration sensible aux ontologies pourrait accélérer la découverte de biomarqueurs, informer la médecine de précision et aider à transformer le flux croissant de textes biomédicaux en connaissances médicales exploitables.
Citation: Naqash, M.A., Amin, M., Uddin, J. et al. Ontology-driven association rule mining for biomedical entity relationships: integrating hierarchical knowledge to improve gene-disease discovery. Sci Rep 16, 13072 (2026). https://doi.org/10.1038/s41598-026-42584-y
Mots-clés: associations gène–maladie, fouille de texte biomédical, ontologies, médecine de précision, biologie computationnelle