Clear Sky Science · zh
用于复合面部表情识别的量子核与现代视觉模型基准评测
为什么读懂面孔比看上去要难
如今许多技术试图从简单的网络摄像头图像中读取我们的情绪,从心理健康工具和驾驶员安全监控到社交机器人和游戏测试工具。但现实中的表情很少只是“高兴”或“悲伤”。它们经常是混合的——恐惧夹杂惊讶,悲伤带有厌恶——即便是人类有时也会读错。本研究提出了一个及时的问题:在从真实世界面孔解码这些细微、混合情绪时,包括新兴的基于量子的做法在内,哪些现代计算系统在准确性与速度之间达到了最佳平衡?
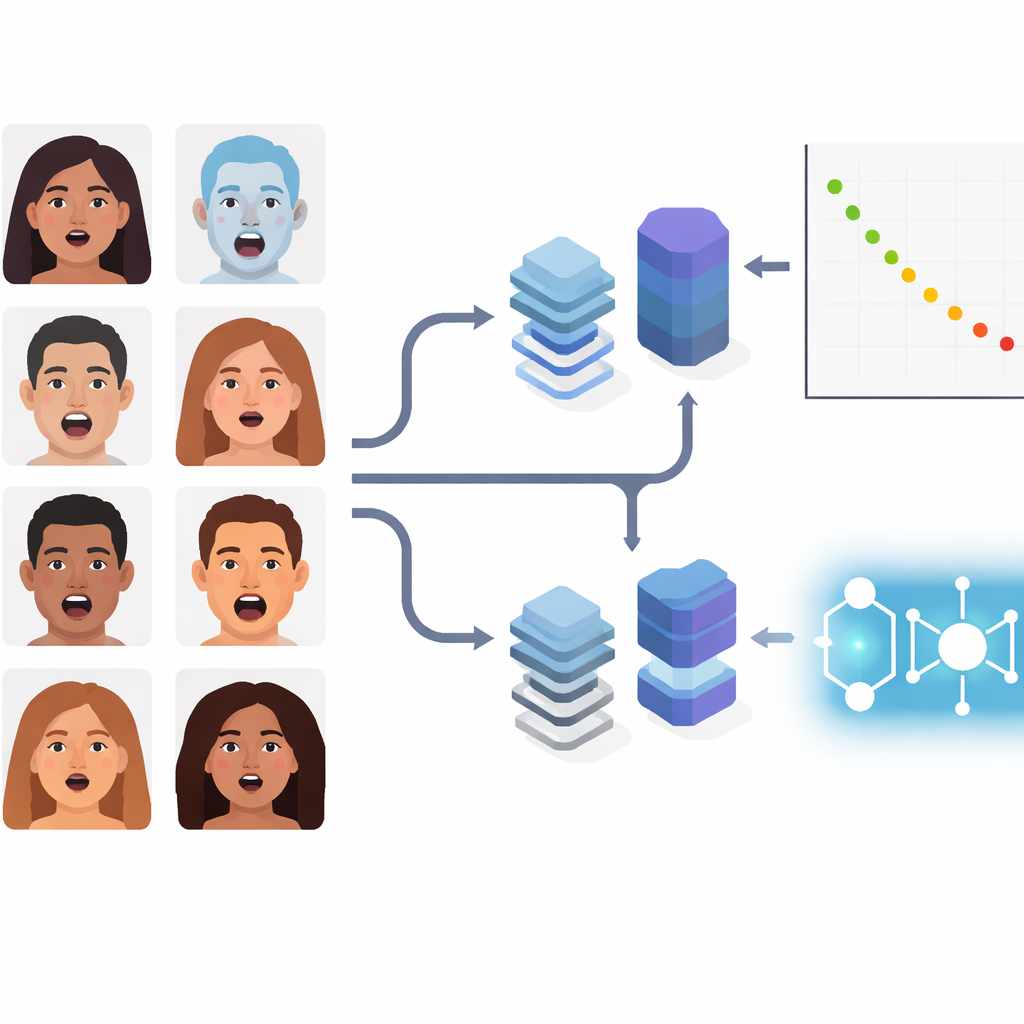
日常生活中的混合情绪
作者没有只关注教科书式的基本情绪,而是研究诸如“惊恐交织的惊讶”或“悲伤夹带厌恶”等复合表情。这些细微状态在诊所、车内或与人交互的社交机器人等自然场景中经常出现。团队使用了一个知名的图像集合 RAF-DB,其中包含成千上万张“野外”拍摄的人脸,覆盖多种光照、姿态和人口统计学特征。他们将注意力限制在 11 个复合类别上,并在所有方法中强制使用相同的数据划分和预处理,以确保性能差异确实来自模型本身,而不是人为挑选的训练条件。
教计算机读脸的七种方法
研究比较了代表三代技术的七种流程。首先是经典混合方法,这些方法使用已有的卷积网络(ResNet50 和 VGGFace)仅作为特征提取器,然后将最终决策交给一种更简单的基于间隔的分类器 SVM。第二类是两种流行的现代深度模型:EfficientNetV2-S,一种为效率优化的精简卷积网络;以及 ViT-B/16,一种将图像视为若干补丁并利用全局注意力连接远端面部区域的视觉变换器。第三类是三种量子—经典混合体。在这些方法中,标准视觉编码器产生紧凑的数值特征,随后由受量子启发的组件处理:量子支持向量机(QSVM)、量子 k 近邻方法(QKNN)或量子卷积网络(QCNN)。
速度、准确率及其权衡
作者并未追逐单一的最高准确率数字,而是在相同硬件上仔细测量特征提取时间、训练时间和每张图像的分类时间。ViT-B/16 在准确率上领先,能正确分类约 63% 的复合表情,同时保持令人意外的快速特征提取。EfficientNetV2-S 紧随其后,准确率约为 61%,但特征提取所需时间要长得多。在量子混合体中,QSVM 表现最佳,达到约 55% 的准确率,且特征提取时间仅约一分钟,这在计算预算受限时具有吸引力。QKNN 和 QCNN 在时间上更为节省——尤其是 QCNN——但以牺牲准确率为代价,准确率徘徊在中 30% 左右。经典混合方法处于中间位置,作为透明的基线很有用,但通常落后于现代与量子增强选项。
机器仍然容易混淆的地方
对错误的更细致分析表明,所有系统在类似方面都有困难。混淆倾向于集中在两类家族上:恐惧与惊讶,以及悲伤与厌恶(有时夹带愤怒)。这些类别共享相似的面部肌肉模式——恐惧与惊讶表现为睁大眼睛和抬起的眉毛,悲伤与厌恶则表现为下垂的嘴角和鼻部皱纹——因此它们的视觉特征存在重叠。即便是 ViT 的全局注意力和 QSVM 更具表现力的量子核也无法完全区分这些相似表情。作者认为未来的模型应有针对性地关注与动作单元相关的特定面部区域(如眼角、眉毛和鼻周区域),调整训练目标以扩大相邻类别之间的间隔,并采用均衡的数据增强策略以避免对最常见复合类别的过拟合。
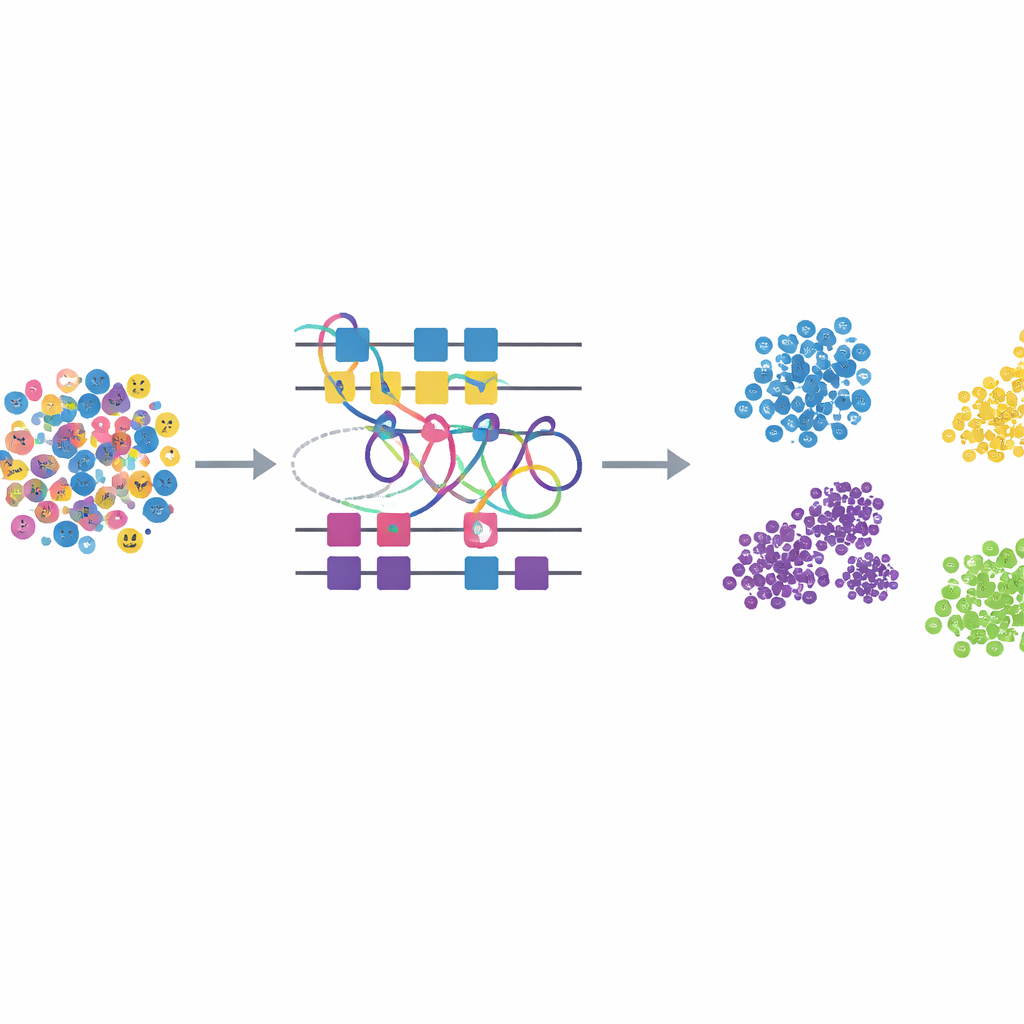
这对现实世界的情感感知系统意味着什么
作者并不声称量子方法已经超越了经典深度学习,而是提供了一份对当前格局的细致地图。如果绝对准确率最重要且计算资源充足,视觉变换器仍然领先。当开发者必须关注功耗或延迟——例如在边缘设备或低延迟服务器上——像 QSVM 和 QKNN 这样的量子混合体提供了有前景的折衷方案,削减特征提取和推理时间的同时保持令人可接受的准确率。经典的 CNN 加 SVM 流程仍然是有用的参照。通过结合严格的计算统计、详细的错误分析和正式的统计检验,这项工作表明,解读复杂的人类情绪不仅关乎原始准确率,还关乎智能的资源分配与公平性——而受量子启发的工具可能很快成为实现这一目标的实用伙伴。
引用: Florestiyanto, M.Y., Surjono, H.D. & Jati, H. Benchmarking quantum kernels and modern vision models for compound facial expression recognition. Sci Rep 16, 11261 (2026). https://doi.org/10.1038/s41598-026-41514-2
关键词: 面部表情识别, 复合情绪, 视觉变换器, 量子机器学习, 高效 AI 模型