Clear Sky Science · ar
تقييم نوى كمية ونماذج رؤية حديثة للتعرف على التعبيرات الوجهية المركبة
لماذا قراءة الوجوه أصعب مما تبدو
تحاول العديد من التقنيات اليوم استنتاج مشاعرنا من صورة كاميرا ويب بسيطة، بدءًا من أدوات الصحة النفسية وأنظمة مراقبة سلامة السائقين إلى الروبوتات الاجتماعية وبرامج اختبار الألعاب. لكن التعبيرات في الحياة الواقعية نادرًا ما تكون مجرد «سعيدة» أو «حزينة». غالبًا ما تكون مزيجات—خوف ممزوج بمفاجأة، حزن مائل للاشمئزاز—وحتى البشر قد يخطئون أحيانًا في تفسيرها. تطرح هذه الدراسة سؤالًا راهنًا: أي أنظمة الحاسوب الحديثة، بما في ذلك الأساليب الناشئة القائمة على الكم، تحقق أفضل توازن بين الدقة والسرعة عند فك رموز هذه العواطف المركبة الدقيقة من الوجوه الواقعية؟
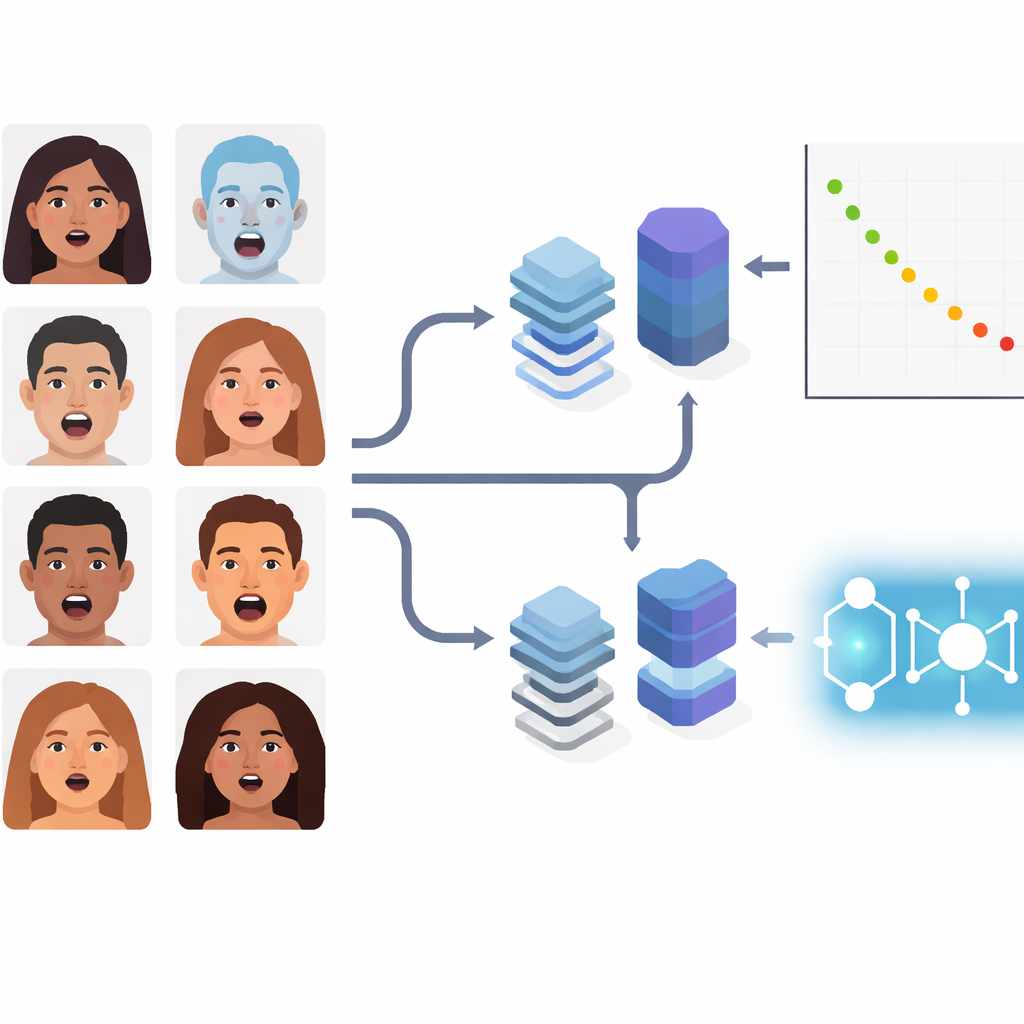
العواطف الممزوجة في الحياة اليومية
بدلًا من التركيز على العواطف الأساسية المدرسية، يتعامل المؤلفون مع تعبيرات مركبة مثل «مندهش بخوف» أو «مشمئز بحزن». هذه الحالات الدقيقة تظهر كثيرًا في بيئات طبيعية مثل العيادات والسيارات أو عند تفاعل الروبوتات الاجتماعية مع البشر. استخدمت الفريق مجموعة صور معروفة باسم RAF-DB، التي تضم آلاف الوجوه الملتقطة «في البرية» تحت ظروف إضاءة وزوايا سطوح وسكانيات متباينة. حصروا الدراسة في 11 فئة مركبة وفرضوا تقسيمات بيانات ومعالجات مسبقة مطابقة على جميع الطرق بحيث تأتي أي فروق في الأداء بالفعل من النماذج نفسها، لا من ظروف تدريب مُنتقاة.
سبع طرق لتعليم الحواسيب قراءة الوجوه
تقارن الدراسة سبع سلاسل معالجة تمثل ثلاثة أجيال من التكنولوجيا. أولًا الهجينة الكلاسيكية، التي تستخدم شبكات تلافيفية معروفة (ResNet50 وVGGFace) فقط كمستخرجات ميزات، ثم تسلم القرار النهائي لمصنف بسيط قائم على الهامش يُسمى SVM. ثانيًا نموذجان عميقان حديثان شائعان: EfficientNetV2-S، شبكة تلافيفية مبسطة مضبوطة للكفاءة، وViT-B/16، محوّل رؤية يحلل الصور كمجموعة رقع ويستخدم الانتباه العام لربط مناطق وجهية بعيدة. ثالثًا ثلاث هجائن كمية–تقليدية. في هذه، ينتج مُشفر بصري قياسي ميزات رقمية مدمجة تُعالَج بعدها بمكونات مستلهمة من الكم: آلة ناقلات الدعم الكمية (QSVM)، طريقة الجيران الأقرب الكمية (QKNN)، أو شبكة تلافيفية كمية (QCNN).
السرعة والدقة والمقايضات بينها
بدلًا من ملاحقة رقم دقة وحيد كعناوين، يقيس المؤلفون بعناية زمن استخراج الميزات، وزمن التدريب، وزمن التصنيف لكل صورة، وكل ذلك على نفس العتاد. يبرز ViT-B/16 في الصدارة من حيث الدقة، حيث يصنّف نحو 63% من التعابير المركبة بشكل صحيح مع بقاء استخراج الميزات سريعًا بشكل مفاجئ. يتبعه EfficientNetV2-S قريبًا بدقة حوالى 61%، لكنه يحتاج وقتًا أطول بكثير لاستخراج الميزات. بين الهجائن الكمية، يقدّم QSVM الأداء الأفضل، محققًا نحو 55% دقة مع زمن استخراج ميزات يقارب دقيقة واحدة فقط، ما يجعله جذابًا عندما تكون ميزانيات الحوسبة محدودة. يُعتبر QKNN وQCNN أكثر اقتصادًا في الزمن—وخاصة QCNN—لكن ذلك على حساب الدقة، حيث يراوح أداؤهما في منتصف نطاق الثلاثينيات بالمئة. تقع الهجائن الكلاسيكية في الوسط، مفيدة كمعايرات شفافة لكنها عمومًا متخلفة عن الخيارات الحديثة والمعزّزة بالكم.
أين ما تزال الآلات مرتبكة
يعكس فحص أدق للأخطاء أن جميع الأنظمة تكافح بطرق متشابهة. تميل حالات الالتباس إلى التجمع حول عائلتين: الخوف مقابل المفاجأة، والحزن مقابل الاشمئزاز (أحيانًا مع اجواء من الغضب). تشترك هذه الفئات في أنماط عضلية وجهية متقاربة—عيون واسعة وحواجب مرفوعة للخوف والمفاجأة، أو شفاه منخفضة وتجاعيد أنف للحزن والاشمئزاز—لذلك تتداخل بصماتها البصرية. حتى الانتباه العام في ViT ونوى QSVM الأكثر تعبيرًا لا يمكّنان من فصل هذه التعبيرات الشبيهة تمامًا. يجادل المؤلفون بأن النماذج المستقبلية يجب أن تولي اهتمامًا موجهًا لمناطق وجهية محددة مرتبطة بوحدات الفعل (مثل زوايا العين، الحواجب، والمنطقة حول الأنف)، وتعدّل أهداف تدريبها لتوسيع الهوامش بين الفئات المتجاورة، وتستخدم استراتيجيات تضخيم بيانات متوازنة لتجنب الإفراط في التكيّف مع المركبات الأكثر شيوعًا.
ما يعنيه هذا لأنظمة واعية بالعاطفة في العالم الحقيقي
لا يدّعي المؤلفون أن الأساليب الكمية قد تفوّقت بالفعل على التعلم العميق التقليدي. بدلاً من ذلك، يقدمون خريطة مدققة للمشهد الحالي. إذا كانت الدقة المطلقة هي الأهم والموارد الحاسوبية متاحة بكثرة، تظل محولات الرؤية في الصدارة. عندما يضطر المطورون لمراقبة ميزانيات الطاقة أو الكمون—مثلًا على الأجهزة الطرفية أو الخوادم منخفضة الكمون—تقدم الهجائن الكمية مثل QSVM وQKNN أرضية وسطى واعدة، تقلل زمن استخراج الميزات والاستدلال مع الحفاظ على دقة محترمة. تظل سلاسل CNN-زائد-SVM الكلاسيكية أدوات قياس مفيدة. من خلال الجمع بين حسابات حوسبية صارمة، وتحليل أخطاء مفصّل، واختبارات إحصائية رسمية، تُظهر هذه الدراسة أن قراءة العواطف البشرية المعقدة تتعلق بقدر كبير بتخصيص الموارد والعدالة بقدر ما تتعلق بالدقة الخام—وأن الأدوات المستلهمة من الكم قد تصبح قريبًا شركاء عمليين في هذا المسعى.
الاستشهاد: Florestiyanto, M.Y., Surjono, H.D. & Jati, H. Benchmarking quantum kernels and modern vision models for compound facial expression recognition. Sci Rep 16, 11261 (2026). https://doi.org/10.1038/s41598-026-41514-2
الكلمات المفتاحية: التعرف على تعابير الوجه, العواطف المركبة, محولات الرؤية, التعلم الآلي الكمي, نماذج ذكية وفعالة