Clear Sky Science · ja
複合表情認識のための量子カーネルと最新ビジョンモデルのベンチマーク
顔の読み取りが見た目より難しい理由
現在、多くの技術がシンプルなウェブカメラ画像から私たちの感情を読み取ろうとしています。メンタルヘルスツールやドライバー安全監視、ソーシャルロボットやゲームテスターなどで使われます。しかし現実の表情は単に「幸福」や「悲しい」だけとは限りません。恐怖と驚き、悲しさと嫌悪が混ざるなど、人でも誤読することがある複合的なブレンドで表れることが多いのです。本研究は時宜を得た問いを投げかけます:実世界の顔からこうした微妙な混合感情を解読する際、最新のコンピュータシステムや新興の量子ベース手法を含め、どの手法が精度と速度のバランスを最もうまく取れているのか?
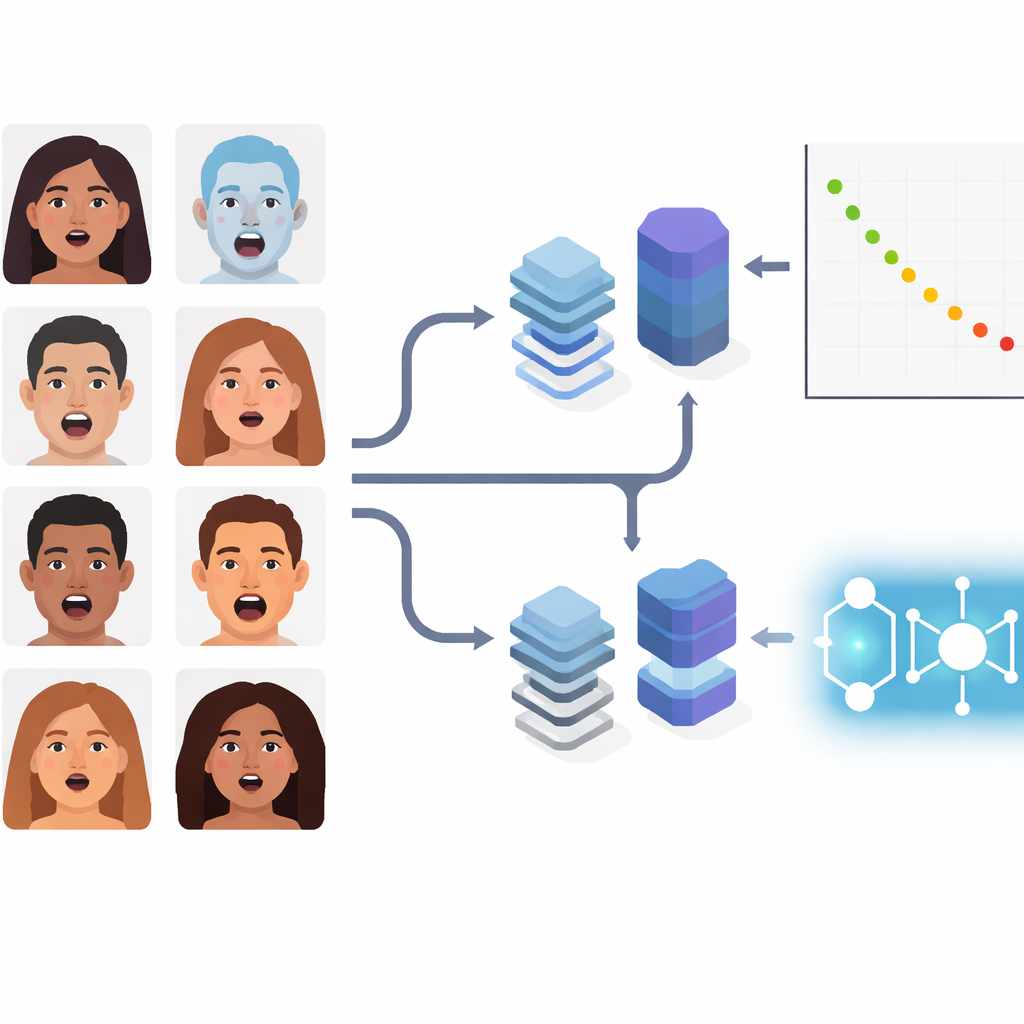
日常に潜む混ざった感情
教科書的な基本感情に注目する代わりに、著者らは「恐れて驚く」や「悲しげに嫌悪する」といった複合表情(compound)に取り組みます。こうした微妙な状態は、クリニックや車内、人と対話するロボットなど、自然な環境で頻繁に現れます。研究チームはRAF-DBと呼ばれる広く知られた画像コレクションを使用しています。これは多様な照明、ポーズ、人口統計下で「野外」で撮影された何千もの顔を含みます。彼らは11の複合カテゴリに注目し、すべての手法でデータ分割と前処理を統一して、性能差がモデルそのものに起因することを保証しています(都合の良い学習条件を選んでいない)。
コンピュータに顔を学ばせる7つの方法
研究は三世代の技術を代表する7つのパイプラインを比較します。まず古典的なハイブリッドでは、既存の畳み込みネットワーク(ResNet50やVGGFace)を特徴抽出器として用い、最終判断をマージンベースの単純な分類器SVMに委ねます。次に人気のある現代的な深層モデル二種:効率性に最適化された畳み込みネットワークEfficientNetV2-Sと、画像をパッチの集合として解析しグローバルな注意機構で離れた顔領域を結び付けるビジョントランスフォーマーViT-B/16です。三つ目は量子–古典ハイブリッド三種で、標準的な視覚エンコーダがコンパクトな数値特徴を生成し、それを量子に着想を得たコンポーネント――量子サポートベクターマシン(QSVM)、量子k近傍法(QKNN)、量子畳み込みネットワーク(QCNN)――で処理します。
速度、精度、そしてそれらのトレードオフ
単一の見出し用精度値を追いかけるのではなく、著者らは同一ハードウェア上で特徴抽出時間、学習時間、画像ごとの分類時間を慎重に測定します。ViT-B/16は精度でトップで、複合表情を約63%正しく分類しながら特徴抽出も驚くほど高速でした。EfficientNetV2-Sは約61%で僅差ですが、特徴抽出により多くの時間を要します。量子ハイブリッドの中ではQSVMが最良で、特徴抽出に約1分しかかからず概ね55%の精度に達するため、計算資源が限られる場合に魅力的です。QKNNとQCNNは特にQCNNがさらに時間効率的ですが、精度は犠牲になり30%台半ばに留まります。古典ハイブリッドは中間に位置し、透明性のあるベースラインとして有用ですが、概して現代的手法や量子強化手法に後れを取ります。
機械がまだ混乱する箇所
誤分類の詳細を見ると、すべてのシステムが似たような苦手領域を持つことがわかります。混同は主に二つの群に集中します:恐怖と驚き、そして悲しみと嫌悪(ときに怒りが混ざる)です。これらのカテゴリは似た顔面筋のパターンを共有します—恐怖や驚きでは見開いた目や上がった眉、悲しみや嫌悪では下がった口角や鼻のしわなど—ため視覚的な特徴が重なります。ViTのグローバルアテンションやQSVMのより表現力ある量子カーネルでも、これら類似表情を完全に分離することはできません。著者らは、将来のモデルは眼角や眉、鼻周囲などアクションユニットに結び付く特定の顔領域に的を絞った注意を払い、隣接クラス間のマージンを広げるよう学習目的を調整し、よく現れる複合表情に過学習しないようバランスの取れたデータ拡張戦略を用いるべきだと論じています。
実世界の感情対応システムにとっての含意
著者らは量子手法が既に古典的な深層学習を凌駕したと主張しているわけではありません。むしろ、現状の地図を慎重に示しています。絶対的な精度が最重要で計算資源が潤沢なら、ビジョントランスフォーマーが依然として優位です。エッジデバイスや低遅延サーバーのように消費電力や待ち時間に制約がある場合、QSVMやQKNNのような量子ハイブリッドは、特徴抽出や推論時間を短縮しつつ妥当な精度を維持する有望な中間解を提供します。古典的なCNN+SVMパイプラインは比較基準として依然有用です。厳密な計算コストの算定、詳細な誤り解析、形式的な統計検定を組み合わせることで、本研究は複雑な人間の感情を読み取ることが単なる生の精度だけでなく、賢いリソース配分と公平性に関わる問題であり、量子に着想を得たツールが近い将来実用的なパートナーになり得ることを示しています。
引用: Florestiyanto, M.Y., Surjono, H.D. & Jati, H. Benchmarking quantum kernels and modern vision models for compound facial expression recognition. Sci Rep 16, 11261 (2026). https://doi.org/10.1038/s41598-026-41514-2
キーワード: 顔表情認識, 複合感情, ビジョントランスフォーマー, 量子機械学習, 効率的なAIモデル