Clear Sky Science · es
Comparación de kernels cuánticos y modelos visuales modernos para el reconocimiento de expresiones faciales compuestas
Por qué leer los rostros es más difícil de lo que parece
Hoy muchas tecnologías intentan inferir nuestras emociones a partir de una simple imagen de webcam, desde herramientas de salud mental y monitores de seguridad para conductores hasta robots sociales y evaluadores de videojuegos. Pero las expresiones en la vida real rara vez son solo “alegría” o “tristeza”. Con frecuencia son mezclas: miedo con sorpresa, tristeza con asco, matices que incluso las personas a veces interpretan mal. Este estudio plantea una pregunta actual: ¿qué sistemas informáticos modernos, incluidos métodos emergentes basados en lo cuántico, encuentran el mejor equilibrio entre precisión y velocidad al decodificar esas emociones sutiles y mixtas en rostros del mundo real?
Emociones mezcladas en la vida cotidiana
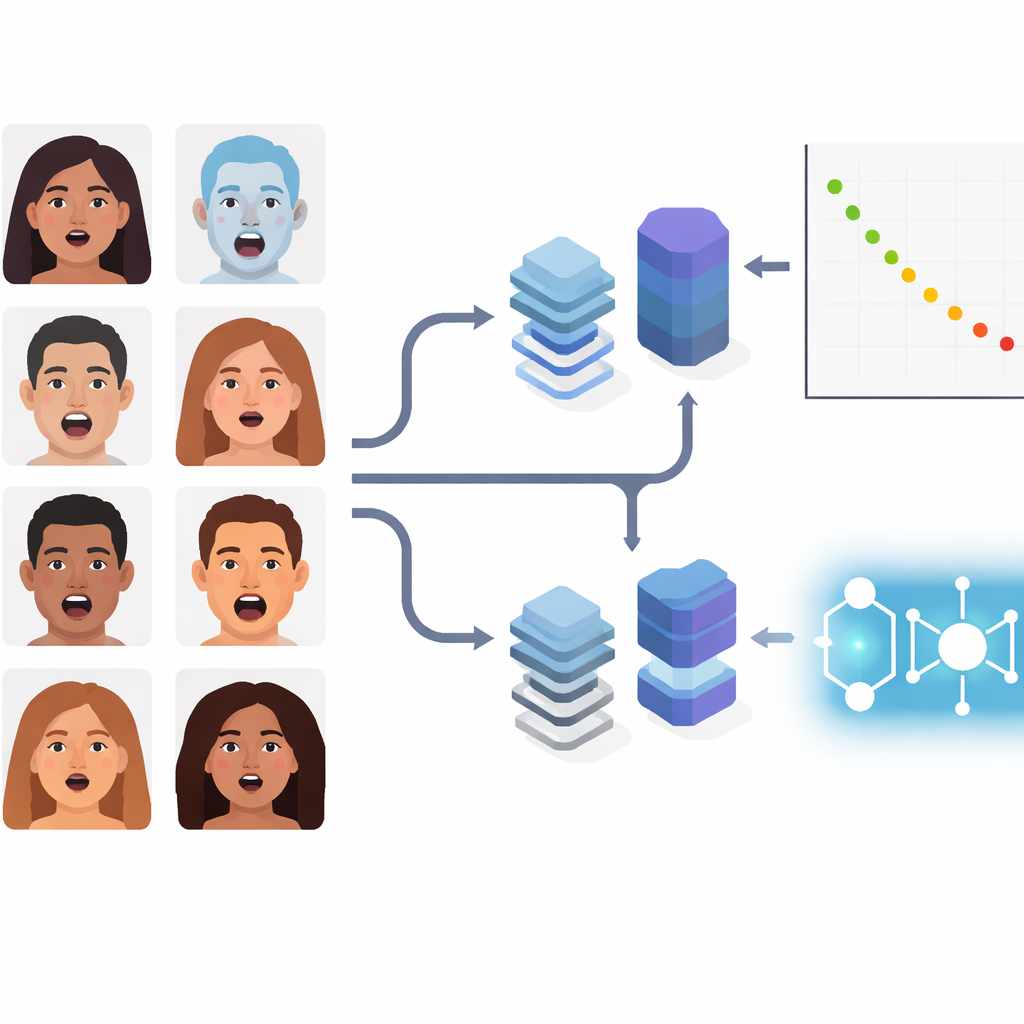
En lugar de centrarse en las emociones básicas de libro de texto, los autores abordan expresiones compuestas como “sorprendido con miedo” o “asqueado con tristeza”. Estos estados matizados aparecen con frecuencia en entornos naturales como clínicas, automóviles o interacciones de robots con humanos. El equipo utiliza una conocida colección de imágenes llamada RAF-DB, que contiene miles de rostros capturados “en la naturaleza” bajo iluminación, poses y demografías variadas. Se limitan a 11 categorías compuestas y aplican divisiones de datos y preprocesado idénticos en todos los métodos para que cualquier diferencia en rendimiento provenga realmente de los modelos y no de condiciones de entrenamiento seleccionadas.
Siete formas de enseñar a las máquinas a leer rostros
El estudio compara siete flujos que representan tres generaciones tecnológicas. Primero, híbridos clásicos que usan redes convolucionales establecidas (ResNet50 y VGGFace) únicamente como extractores de características, para ceder la decisión final a un clasificador más simple basado en márgenes llamado SVM. En segundo lugar, dos modelos profundos modernos populares: EfficientNetV2-S, una red convolucional optimizada para eficiencia, y ViT-B/16, un transformador de visión que analiza imágenes como un conjunto de parches y usa atención global para conectar regiones faciales distantes. Tercero, tres híbridos cuántico–clásicos. En éstos, un codificador visual estándar produce características numéricas compactas que luego son procesadas por componentes inspirados en lo cuántico: una máquina de vectores soporte cuántica (QSVM), un método cuántico de k-vecinos más cercanos (QKNN) o una red convolucional cuántica (QCNN).
Velocidad, precisión y los compromisos entre ellas
En lugar de perseguir un único número de precisión, los autores miden cuidadosamente el tiempo de extracción de características, el tiempo de entrenamiento y el tiempo de clasificación por imagen, todo en el mismo hardware. ViT-B/16 sale vencedor en precisión, clasificando correctamente alrededor del 63% de las expresiones compuestas mientras mantiene la extracción de características sorprendentemente rápida. EfficientNetV2-S queda cerca, con aproximadamente un 61% de precisión, pero necesita mucho más tiempo para extraer características. Entre los híbridos cuánticos, QSVM rinde mejor, alcanzando aproximadamente un 55% de precisión con solo alrededor de un minuto de extracción de características, lo que lo hace atractivo cuando el presupuesto de cómputo es limitado. QKNN y QCNN son aún más frugales en tiempo—especialmente QCNN—pero sacrifican precisión, situándose en torno a la mitad del rango del 30%. Los híbridos clásicos se colocan en el centro, útiles como líneas base transparentes pero generalmente por detrás de las opciones modernas y potenciadas por lo cuántico.
Dónde las máquinas aún se confunden
Un examen más detallado de los errores muestra que todos los sistemas tropiezan de formas similares. Las confusiones tienden a agruparse en dos familias: miedo frente a sorpresa, y tristeza frente a asco (a veces mezclado con ira). Estas categorías comparten patrones musculares faciales similares—ojos muy abiertos y cejas levantadas para miedo y sorpresa, o labios hacia abajo y arrugas nasales para tristeza y asco—por lo que sus huellas visuales se solapan. Ni la atención global de ViT ni los kernels más expresivos de QSVM pueden separar completamente estas expresiones parecidas. Los autores sugieren que los modelos futuros deberían prestar atención dirigida a regiones faciales específicas vinculadas a unidades de acción (como las comisuras de los ojos, las cejas y la zona alrededor de la nariz), ajustar sus objetivos de entrenamiento para ampliar los márgenes entre clases vecinas y usar estrategias de aumento de datos balanceadas para evitar sobreajustar a los compuestos más frecuentes.
Qué significa esto para sistemas del mundo real con conciencia emocional
Los autores no afirman que los métodos cuánticos ya hayan superado al aprendizaje profundo clásico. En cambio, ofrecen un mapa cuidadoso del panorama actual. Si la precisión absoluta es primordial y los recursos de cómputo sobran, los transformadores de visión siguen liderando. Cuando los desarrolladores deben vigilar límites de energía o latencia—por ejemplo, en dispositivos de borde o servidores de baja latencia—los híbridos cuánticos como QSVM y QKNN ofrecen un término medio prometedor, recortando tiempos de extracción de características e inferencia mientras mantienen una precisión respetable. Las canalizaciones clásicas CNN más SVM siguen siendo útiles como referencias. Al combinar una contabilidad rigurosa del cómputo, un análisis detallado de errores y pruebas estadísticas formales, este trabajo muestra que leer emociones humanas complejas tiene tanto que ver con la asignación inteligente de recursos y la equidad como con la precisión pura—y que las herramientas inspiradas en lo cuántico podrían pronto ser socias prácticas en ese empeño.
Cita: Florestiyanto, M.Y., Surjono, H.D. & Jati, H. Benchmarking quantum kernels and modern vision models for compound facial expression recognition. Sci Rep 16, 11261 (2026). https://doi.org/10.1038/s41598-026-41514-2
Palabras clave: reconocimiento de expresiones faciales, emociones compuestas, transformadores de visión, aprendizaje automático cuántico, modelos de IA eficientes