Clear Sky Science · pl
Benchmarking kernelów kwantowych i nowoczesnych modeli wizji dla rozpoznawania złożonych ekspresji twarzy
Dlaczego odczytywanie twarzy jest trudniejsze, niż się wydaje
Wiele technologii próbuje dziś odczytywać nasze emocje z prostego obrazu z kamery — od narzędzi zdrowia psychicznego i monitorów bezpieczeństwa kierowcy po roboty społeczne i testery gier. W rzeczywistości ekspresje rzadko są tylko „szczęśliwe” albo „smutne”. Często są mieszaninami — strach zaskoczony, smutek z domieszką obrzydzenia — które nawet ludzie czasem źle interpretują. Badanie stawia aktualne pytanie: które nowoczesne systemy komputerowe, w tym pojawiające się metody oparte na kwantach, najlepiej równoważą dokładność i szybkość przy dekodowaniu tych subtelnych, zmieszanych emocji z twarzy w warunkach realnych?
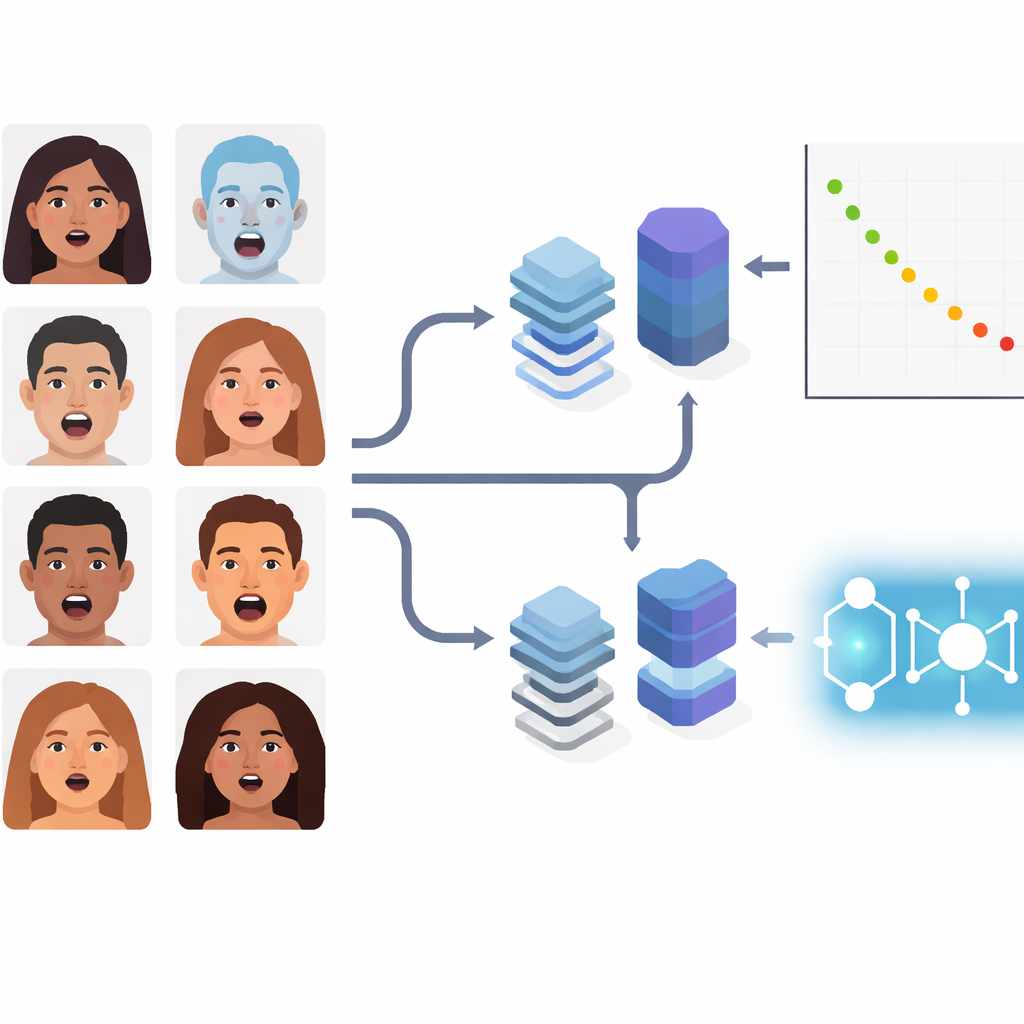
Złożone emocje w życiu codziennym
Zamiast skupiać się na podręcznikowych podstawowych emocjach, autorzy badają złożone ekspresje, takie jak „przerażająco zaskoczony” czy „smutno zniesmaczony”. Te subtelne stany występują często w naturalnych sytuacjach, na przykład w klinikach, samochodach czy podczas interakcji robotów społecznych z ludźmi. Zespół wykorzystuje dobrze znany zbiór zdjęć RAF-DB, zawierający tysiące twarzy „w naturze” zróżnicowanych pod względem oświetlenia, pozy i demografii. Skupiają się na 11 kategoriach złożonych i stosują identyczne podziały danych oraz wstępne przetwarzanie we wszystkich metodach, aby różnice w wynikach wynikały faktycznie z modeli, a nie z selektywnie dobranych warunków treningowych.
Siedem sposobów uczenia komputerów czytania twarzy
Badanie porównuje siedem pipelines reprezentujących trzy generacje technologii. Najpierw klasyczne hybrydy, które używają sprawdzonych sieci konwolucyjnych (ResNet50 i VGGFace) jedynie jako ekstraktorów cech, a końcową decyzję przekazują prostszemu klasyfikatorowi opartemu na marginesie — SVM. Druga grupa to dwa popularne nowoczesne modele głębokie: EfficientNetV2-S, odchudzona sieć konwolucyjna zoptymalizowana pod kątem efektywności, oraz ViT-B/16, transformer wizji analizujący obraz jako zestaw łatek i wykorzystujący globalną uwagę do łączenia odległych regionów twarzy. Trzecia to trzy hybrydy kwantowo-klasyczne. W nich standardowy enkoder wizualny produkuje zwarte cechy numeryczne, które następnie przetwarzane są przez komponenty inspirowane kwantowo: kwantowy SVM (QSVM), kwantową metodę k-najbliższych sąsiadów (QKNN) lub kwantową sieć konwolucyjną (QCNN).
Szybkość, dokładność i kompromisy między nimi
Zamiast gonić za jednym wynikiem dokładności, autorzy dokładnie mierzą czas ekstrakcji cech, czas treningu i czas klasyfikacji na obraz, wszystko na tym samym sprzęcie. ViT-B/16 okazuje się najlepszy pod względem dokładności, poprawnie klasyfikując około 63% złożonych ekspresji przy jednoczesnym zaskakująco szybkim wydobywaniu cech. EfficientNetV2-S jest blisko z około 61% dokładności, ale potrzebuje znacznie więcej czasu na ekstrakcję cech. Wśród hybryd kwantowych QSVM wypada najlepiej, osiągając około 55% dokładności przy zaledwie około minucie na ekstrakcję cech, co czyni go atrakcyjnym przy ograniczonych zasobach obliczeniowych. QKNN i QCNN są jeszcze bardziej oszczędne czasowo — szczególnie QCNN — lecz kosztem dokładności, oscylując w okolicach środkowych 30%. Klasyczne hybrydy plasują się pośrodku, użyteczne jako przejrzyste punkty odniesienia, ale generalnie ustępują nowoczesnym i kwantowo-wspomaganym opcjom.
Gdzie maszyny wciąż się mylą
Bliższa analiza błędów pokazuje, że wszystkie systemy mają podobne trudności. Pomyłki zwykle skupiają się wokół dwóch par: strach kontra zaskoczenie oraz smutek kontra obrzydzenie (czasem zmieszane z gniewem). Kategorie te dzielą podobne wzorce działania mięśni twarzy — szerokie oczy i uniesione brwi dla strachu i zaskoczenia, lub opuszczone kąciki ust i marszczenie nosa dla smutku i obrzydzenia — więc ich wizualne ślady zachodzą na siebie. Nawet globalna uwaga ViT i bardziej ekspresyjne jądra QSVM nie są w stanie całkowicie rozdzielić tych podobnych wyrażeń. Autorzy sugerują, że przyszłe modele powinny skierować uwagę na konkretne regiony twarzy powiązane z jednostkami akcji (takie jak kąciki oczu, brwi i okolice nosa), dostosować cele treningowe, aby zwiększyć marginesy między sąsiednimi klasami, oraz stosować zrównoważone strategie augmentacji danych, by unikać nadmiernego dopasowania do najczęstszych związków ekspresji.
Co to oznacza dla systemów rozpoznających emocje w praktyce
Autorzy nie twierdzą, że metody kwantowe już przewyższyły klasyczne uczenie głębokie. Zamiast tego przedstawiają staranny przegląd aktualnego krajobrazu. Jeśli absolutna dokładność jest najważniejsza i zasoby obliczeniowe są obfite, nadal prowadzą transformery wizji. Gdy deweloperzy muszą kontrolować budżety energetyczne lub opóźnienia — na przykład na urządzeniach brzegowych czy serwerach niskolatencyjnych — hybrydy kwantowe takie jak QSVM i QKNN oferują obiecujący kompromis, skracając czas ekstrakcji cech i inferencji przy zachowaniu przyzwoitej dokładności. Klasyczne rozwiązania CNN-plus-SVM pozostają użytecznymi miarami porównawczymi. Łącząc rygorystyczne rozliczanie zasobów obliczeniowych, szczegółową analizę błędów i formalne testy statystyczne, praca ta pokazuje, że odczytywanie złożonych ludzkich emocji to równie dużo o mądrym przydziale zasobów i sprawiedliwości, co o surowej dokładności — i że narzędzia inspirowane kwantowo mogą wkrótce stać się praktycznymi partnerami w tym wysiłku.
Cytowanie: Florestiyanto, M.Y., Surjono, H.D. & Jati, H. Benchmarking quantum kernels and modern vision models for compound facial expression recognition. Sci Rep 16, 11261 (2026). https://doi.org/10.1038/s41598-026-41514-2
Słowa kluczowe: rozpoznawanie ekspresji twarzy, emocje złożone, transformery wizji, uczenie maszynowe kwantowe, wydajne modele AI