Clear Sky Science · de
Benchmarking von Quanten-Kernmethoden und modernen Vision-Modellen für die Erkennung zusammengesetzter Gesichtsausdrücke
Warum Gesichterlesen schwieriger ist, als es scheint
Viele Technologien versuchen heute, unsere Gefühle aus einem einfachen Webcam‑Bild abzulesen — von Tools für psychische Gesundheit und Fahrersicherheitsüberwachung bis zu Sozialrobotern und Spieletestern. In der Realität sind Gesichtsausdrücke jedoch selten nur „glücklich“ oder „traurig“. Häufig handelt es sich um Mischformen — Angst gemischt mit Überraschung, Traurigkeit mit einem Hauch von Ekel — die selbst Menschen bisweilen falsch interpretieren. Die vorliegende Studie stellt eine aktuelle Frage: Welche modernen Computersysteme, einschließlich aufkommender quantenbasierter Methoden, finden die beste Balance zwischen Genauigkeit und Geschwindigkeit beim Entschlüsseln dieser subtilen, gemischten Emotionen aus realen Gesichtern?
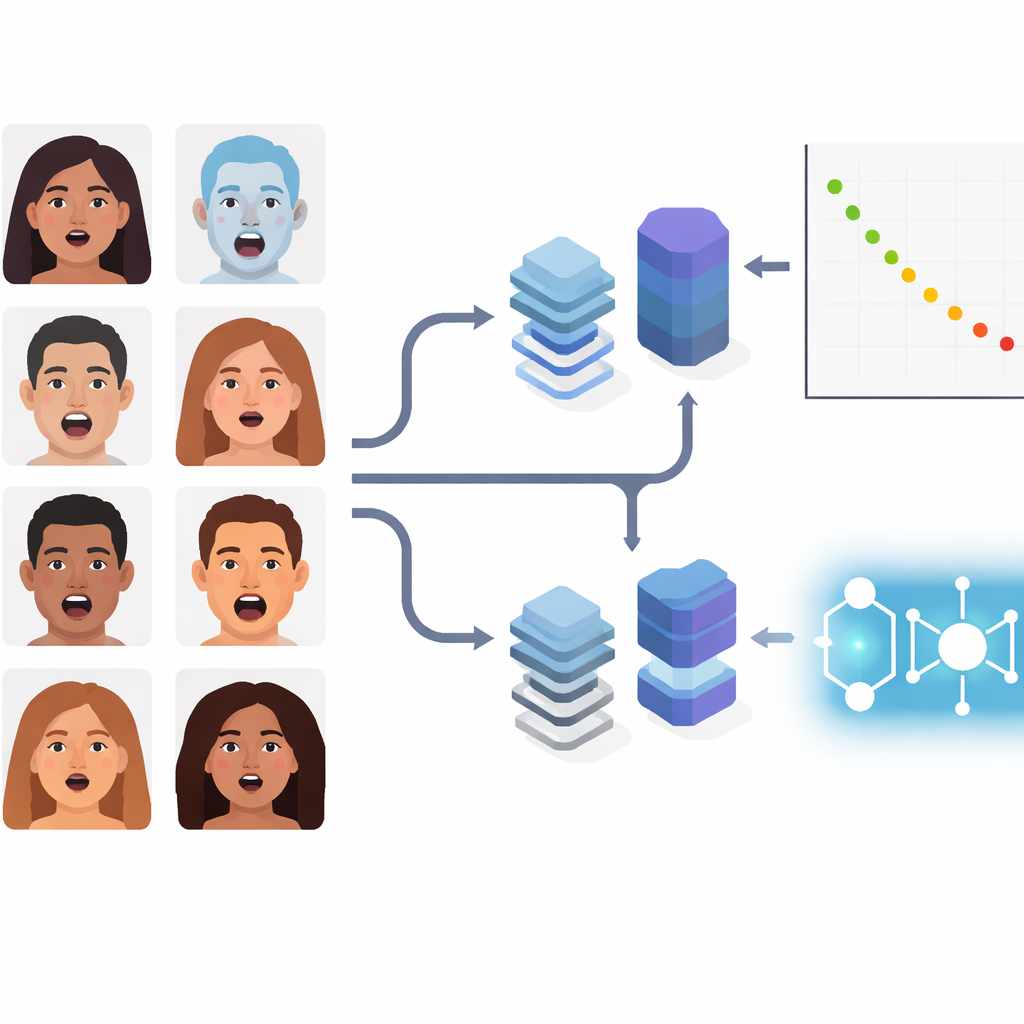
Gemischte Emotionen im Alltag
Anstatt sich auf die standardmäßigen Basisemotionen zu konzentrieren, befassen sich die Autorinnen und Autoren mit zusammengesetzten Ausdrücken wie „erschrocken‑ängstlich“ oder „traurig‑eklig“. Solche nuancierten Zustände treten häufig in natürlichen Situationen auf, etwa in Kliniken, in Fahrzeugen oder bei Interaktionen mit Sozialrobotern. Das Team verwendet eine bekannte Bildsammlung namens RAF‑DB, die Tausende von Gesichtern „in freier Wildbahn“ unter unterschiedlichen Lichtverhältnissen, Posen und Demografien enthält. Es wird auf 11 zusammengesetzte Kategorien beschränkt und bei allen Methoden dieselbe Datenaufteilung und Vorverarbeitung durchgesetzt, sodass Leistungsunterschiede tatsächlich aus den Modellen resultieren und nicht aus selektiv gewählten Trainingsbedingungen.
Sieben Wege, Computern Gesichter beizubringen
Die Studie vergleicht sieben Pipelines, die drei Technologiegenerationen repräsentieren. Zunächst klassische Hybride, die etablierte Faltungsnetze (ResNet50 und VGGFace) nur als Merkmalextraktoren nutzen und die finale Entscheidung an einen einfacheren marginbasierten Klassifikator, ein SVM, übergeben. Zweitens zwei populäre moderne Deep‑Modelle: EfficientNetV2‑S, ein für Effizienz optimiertes Faltungsnetz, und ViT‑B/16, ein Vision Transformer, der Bilder als Patch‑Menge analysiert und mit globaler Attention entfernte Gesichtsregionen verknüpft. Drittens drei Quanten‑Klassische Hybride. Hier erzeugt ein standardmäßiger visueller Encoder kompakte numerische Merkmale, die anschließend von quanteninspirierten Komponenten verarbeitet werden: einer Quanten‑Support‑Vector‑Machine (QSVM), einer quanten‑k‑Nearest‑Neighbor‑Methode (QKNN) oder einem quantum convolutional network (QCNN).
Geschwindigkeit, Genauigkeit und deren Abwägungen
Anstatt einer einzigen Schlagzeilenzahl für Genauigkeit nachzujagen, messen die Autorinnen und Autoren sorgfältig die Zeit für Merkmalextraktion, Trainingszeit und Klassifikationszeit pro Bild — alles auf derselben Hardware. ViT‑B/16 liegt vorn bei der Genauigkeit und klassifiziert rund 63% der zusammengesetzten Ausdrücke korrekt, wobei die Merkmalextraktion überraschend schnell bleibt. EfficientNetV2‑S folgt nahebei mit etwa 61% Genauigkeit, benötigt jedoch deutlich mehr Zeit zur Merkmalsextraktion. Unter den Quantenhybriden schneidet die QSVM am besten ab und erreicht ungefähr 55% Genauigkeit bei nur etwa einer Minute Merkmalextraktionszeit, was sie attraktiv macht, wenn die Rechenbudgets begrenzt sind. QKNN und QCNN sind zeitlich noch sparsamer — besonders QCNN — opfern dafür aber Genauigkeit und liegen im mittleren 30‑Prozent‑Bereich. Klassische Hybride befinden sich in der Mitte: nützliche, transparente Baselines, die allgemein hinter den modernen und quantenunterstützten Optionen zurückbleiben.
Wo Maschinen noch durcheinanderkommen
Ein genauerer Blick auf die Fehler zeigt, dass alle Systeme auf ähnliche Weise Probleme haben. Verwechslungen gruppieren sich tendenziell in zwei Familien: Angst versus Überraschung und Traurigkeit versus Ekel (manchmal gemischt mit Ärger). Diese Kategorien teilen ähnliche Gesichtsmuskelmuster — geweitete Augen und hochgezogene Augenbrauen bei Angst und Überraschung oder nach unten gezogene Lippen und Nasenfältchen bei Traurigkeit und Ekel — sodass ihre visuellen Merkmale überlappen. Selbst ViTs globale Attention und QSVMs ausdrucksstärkere quantenbasierte Kernel können diese ähnlichen Ausdrücke nicht vollständig trennen. Die Autorinnen und Autoren argumentieren, dass künftige Modelle gezielt bestimmte Gesichtsregionen berücksichtigen sollten, die mit Action Units verknüpft sind (wie Augenwinkel, Augenbrauen und der Bereich um die Nase), ihre Trainingsziele anpassen sollten, um die Margen zwischen benachbarten Klassen zu vergrößern, und ausgeglichene Datenaugmentierungsstrategien nutzen sollten, um ein Überanpassen an die häufigsten Mischformen zu vermeiden.
Was das für reale, emotionssensitive Systeme bedeutet
Die Autorinnen und Autoren behaupten nicht, dass Quantenmethoden bereits klassische Deep‑Learning‑Ansätze übertroffen haben. Vielmehr liefern sie eine sorgfältige Landkarte der aktuellen Landschaft. Wenn absolute Genauigkeit oberste Priorität hat und ausreichend Rechenressourcen vorhanden sind, führen weiterhin Vision Transformer. Müssen Entwickler jedoch Energie‑ oder Latenzbudgets einhalten — etwa auf Edge‑Geräten oder latenzsensitiven Servern — bieten Quantenhybride wie QSVM und QKNN vielversprechende Kompromisse, indem sie Merkmalextraktions‑ und Inferenzzeiten verkürzen und dabei eine respektable Genauigkeit behalten. Klassische CNN‑plus‑SVM‑Pipelines bleiben nützliche Maßstäbe. Durch die Kombination rigoroser Rechenaufstellung, detaillierter Fehleranalyse und formaler statistischer Tests zeigt diese Arbeit, dass das Erkennen komplexer menschlicher Emotionen ebenso sehr eine Frage intelligenter Ressourcenallokation und Fairness ist wie rohe Genauigkeit — und dass quanteninspirierte Werkzeuge bald praktische Partner in diesem Bestreben werden könnten.
Zitation: Florestiyanto, M.Y., Surjono, H.D. & Jati, H. Benchmarking quantum kernels and modern vision models for compound facial expression recognition. Sci Rep 16, 11261 (2026). https://doi.org/10.1038/s41598-026-41514-2
Schlüsselwörter: Erkennung von Gesichtsausdrücken, zusammengesetzte Emotionen, Vision Transformer, quantum machine learning, effiziente KI‑Modelle