Clear Sky Science · tr
Birleşik yüz ifadelerinin tanınmasında kuantum çekirdekleri ve modern görsel modellerin karşılaştırılması
Yüzleri okumak göründüğünden neden daha zor
Artık birçok teknoloji basit bir webcam görüntüsünden duygularımızı çözmeye çalışıyor; ruh sağlığı araçlarından sürücü güvenliği izleyicilerine, sosyal robotlardan oyun test araçlarına kadar. Ancak gerçek hayattaki ifadeler nadiren sadece “mutlu” veya “üzgün” olur. Çoğu zaman korku ile şaşkınlık, tiksinti ile lekeleşmiş üzüntü gibi karışımlar hâlindedir ve bu karışık ifadeleri insanlar bile bazen yanlış yorumlar. Bu çalışma güncel bir soruyu soruyor: gerçek dünyadaki yüzlerden bu ince, karışık duyguları çözerken doğruluk ve hız arasında en iyi dengeyi hangi modern bilgisayar sistemleri, dahil olmak üzere ortaya çıkan kuantum tabanlı yöntemler kuruyor?
Günlük hayatta karışık duygular
Yazarlar ders kitabı temel duygulara odaklanmak yerine “korkuyla şaşırmış” veya “üzgünce tiksinmiş” gibi birleşik ifadelerle uğraşıyor. Bu nüanslı durumlar klinikler, araç içleri veya insanlarla etkileşen sosyal robotlar gibi doğal ortamlarda sıkça ortaya çıkar. Ekip, aydınlatma, poz ve demografiler bakımından değişken koşullarda “vahşi” olarak yakalanmış binlerce yüz içeren RAF-DB adlı iyi bilinen bir görüntü koleksiyonunu kullanıyor. Karşılaştırmanın adil olması için tüm yöntemlerde 11 birleşik kategoriyle sınırlı kalıyor ve veri bölme ile ön işleme adımlarını aynı tutuyorlar; böylece performanstaki farklar gerçekten modellerden kaynaklanıyor, seçici eğitim koşullarından değil.
Bilgisayarlara yüz okumayı öğretmenin yedi yolu
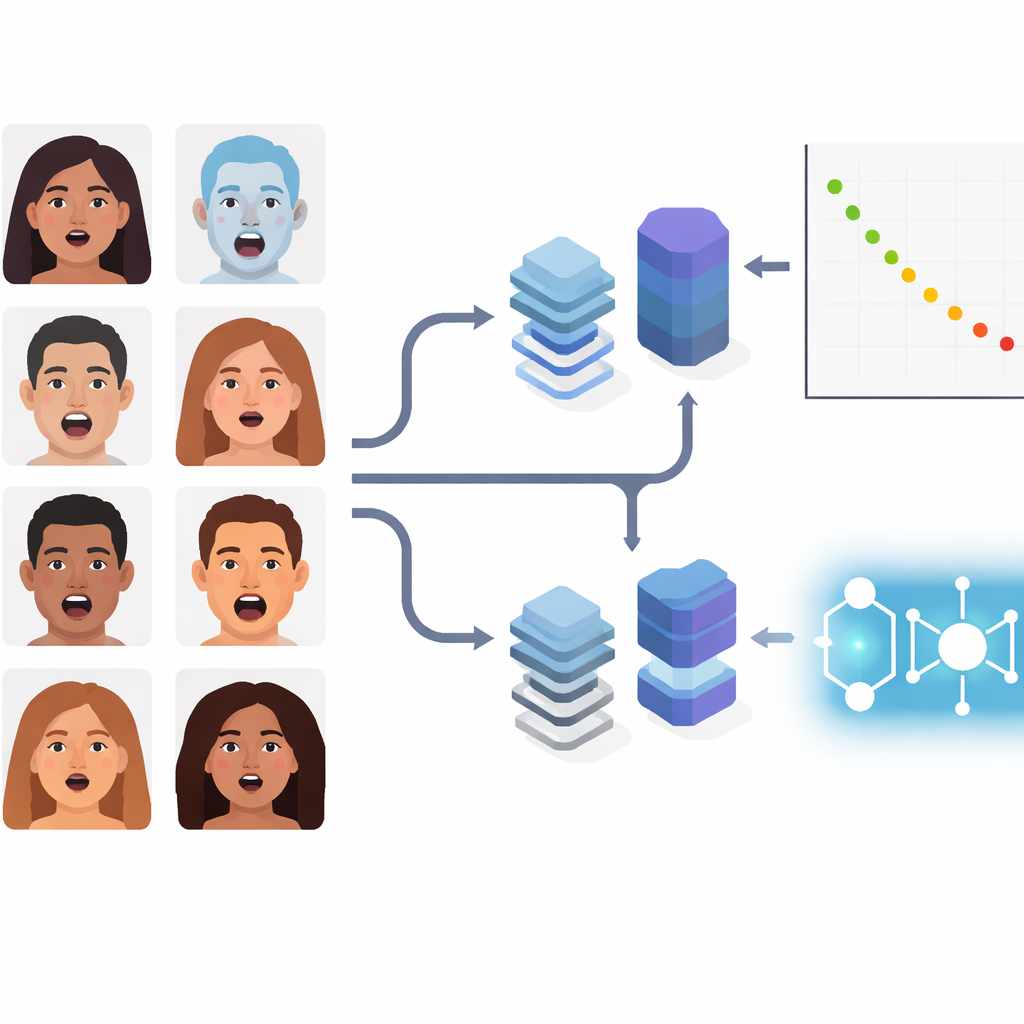
Çalışma, üç nesil teknolojiyi temsil eden yedi boru hattını karşılaştırıyor. İlk olarak klasik hibritler geliyor: yerleşik konvolüsyonel ağları (ResNet50 ve VGGFace) yalnızca özellik çıkarıcı olarak kullanan ve son kararı daha basit, marj tabanlı bir sınıflayıcı olan SVM’ye devreden yaklaşımlar. İkincisi, popüler iki modern derin model: verimlilik için inceltilmiş bir konvolüsyonel ağ olan EfficientNetV2-S ve görüntüleri yamalar halinde ele alıp uzak yüz bölgelerini bağlamak için küresel dikkat mekanizması kullanan ViT-B/16 görsel transformeri. Üçüncü olarak ise üç kuantum–klasik hibrit var. Bunlarda standart bir görsel kodlayıcı sıkıştırılmış sayısal özellikler üretir; bunlar daha sonra bir kuantum destek vektör makinesi (QSVM), bir kuantum k-en yakın komşu yöntemi (QKNN) veya bir kuantum konvolüsyonel ağ (QCNN) gibi kuantum esinli bileşenlerle işlenir.
Hız, doğruluk ve aralarındaki ödünler
Tek bir manşet doğruluk sayısını kovalamak yerine yazarlar, aynı donanım üzerinde özellik çıkarma süresini, eğitim süresini ve görüntü başına sınıflandırma süresini dikkatle ölçüyor. Doğruluk açısından ViT-B/16 öne çıkıyor; birleşik ifadelerin yaklaşık %63’ünü doğru sınıflandırırken özellik çıkarımı şaşırtıcı derecede hızlı tutuluyor. EfficientNetV2-S yaklaşık %61 doğrulukla yakın bir performans sergiliyor, ancak özellik çıkarması çok daha uzun sürüyor. Kuantum hibritleri arasında QSVM en iyi performansı gösteriyor; yaklaşık bir dakika kadar kısa bir özellik çıkarma süresiyle yaklaşık %55 doğruluğa ulaşıyor ve hesaplama bütçelerinin sınırlı olduğu durumlar için çekici hale geliyor. QKNN ve özellikle QCNN zaman açısından daha da ekonomik ancak doğruluktan ödün veriyor; bunlar ortalama %30’lu–%40’lı aralıklarda dolaşıyor. Klasik hibritler ortada konumlanıyor: şeffaf kıyas olarak yararlı ancak genel olarak modern ve kuantumla güçlendirilmiş seçeneklerin gerisinde kalıyorlar.
Makinelerin hâlâ karıştığı yerler
Hatalara daha yakından bakıldığında tüm sistemlerin benzer şekillerde zorlandığı görülüyor. Yanılmalar iki aile etrafında yoğunlaşıyor: korku versus şaşkınlık ve üzüntü versus tiksinti (bazen öfkeyle karışmış). Bu kategoriler benzer yüz kası desenlerini paylaşıyor—korku ve şaşkınlık için geniş açılmış gözler ve kalkmış kaşlar; üzüntü ve tiksinti için aşağı dönük dudaklar ve burun kırışmaları—bu yüzden görsel izleri örtüşüyor. ViT’nin küresel dikkati ve QSVM’nin daha ifade edici kuantum çekirdekleri bile bu benzer görünen ifadeleri tamamen ayıramıyor. Yazarlar gelecekteki modellerin göz köşeleri, kaşlar ve burun çevresi gibi hareket birimleriyle (action units) bağlantılı belirli yüz bölgelerine hedeflenmiş dikkat göstermesi, komşu sınıflar arasındaki marjları genişletmek için eğitim hedeflerini ayarlaması ve en yaygın birleşimlere fazla uyum sağlamamak için dengeli veri artırma stratejileri kullanması gerektiğini savunuyor.
Gerçek dünya duygu farkındalıklı sistemler için anlamı
Yazarlar kuantum yöntemlerinin klasik derin öğrenmeyi şimdiden geride bıraktığını iddia etmiyor. Bunun yerine mevcut manzaranın dikkatli bir haritasını sunuyorlar. Kesin doğruluk en önemli öncelikse ve hesaplama kaynakları bolsa görsel transformerlar hâlâ önde. Geliştiricilerin güç bütçelerini veya gecikmeyi gözlemlemesi gerektiğinde—örneğin uç cihazlarda veya düşük gecikmeli sunucularda—QSVM ve QKNN gibi kuantum hibritleri umut verici bir orta yol sunuyor; özellik çıkarma ve çıkarımsama sürelerini kısaltırken saygın bir doğruluğu koruyor. Klasik CNN-artı-SVM boru hatları hâlâ yararlı kıyas noktaları olarak kalıyor. Titiz hesaplama kaydı, detaylı hata analizi ve resmi istatistiksel testleri birleştirerek bu çalışma, karmaşık insan duygularını okumayı yalnızca ham doğruluk meselesi olmaktan çıkarıp akıllı kaynak tahsisi ve adaletle eşit düzeye koyuyor—ve kuantum esinli araçların yakında bu çabada pratik ortaklar olabileceğini gösteriyor.
Atıf: Florestiyanto, M.Y., Surjono, H.D. & Jati, H. Benchmarking quantum kernels and modern vision models for compound facial expression recognition. Sci Rep 16, 11261 (2026). https://doi.org/10.1038/s41598-026-41514-2
Anahtar kelimeler: yüz ifadesi tanıma, birleşik duygular, görsel transformerlar, kuantum makine öğrenimi, verimli yapay zeka modelleri