Clear Sky Science · sv
Jämförelse av kvantkärnor och moderna visionsmodeller för igenkänning av sammansatta ansiktsuttryck
Varför det är svårare att läsa av ansikten än det ser ut
Många tekniker försöker idag avläsa våra känslor från en enkel webbkamerabild — från verktyg för mental hälsa och förarövervakning till sociala robotar och speltestare. Men verkliga uttryck är sällan bara ”glada” eller ”ledsna.” De är ofta blandningar — rädsla mixad med förvåning, sorg med inslag av äckel — som även människor ibland missuppfattar. Denna studie ställer en aktuell fråga: vilka moderna datorsystem, inklusive framväxande kvantbaserade metoder, hittar bäst balans mellan noggrannhet och fart när de avkodar dessa subtila, blandade känslor i verkliga ansikten?
Blandade känslor i vardagen
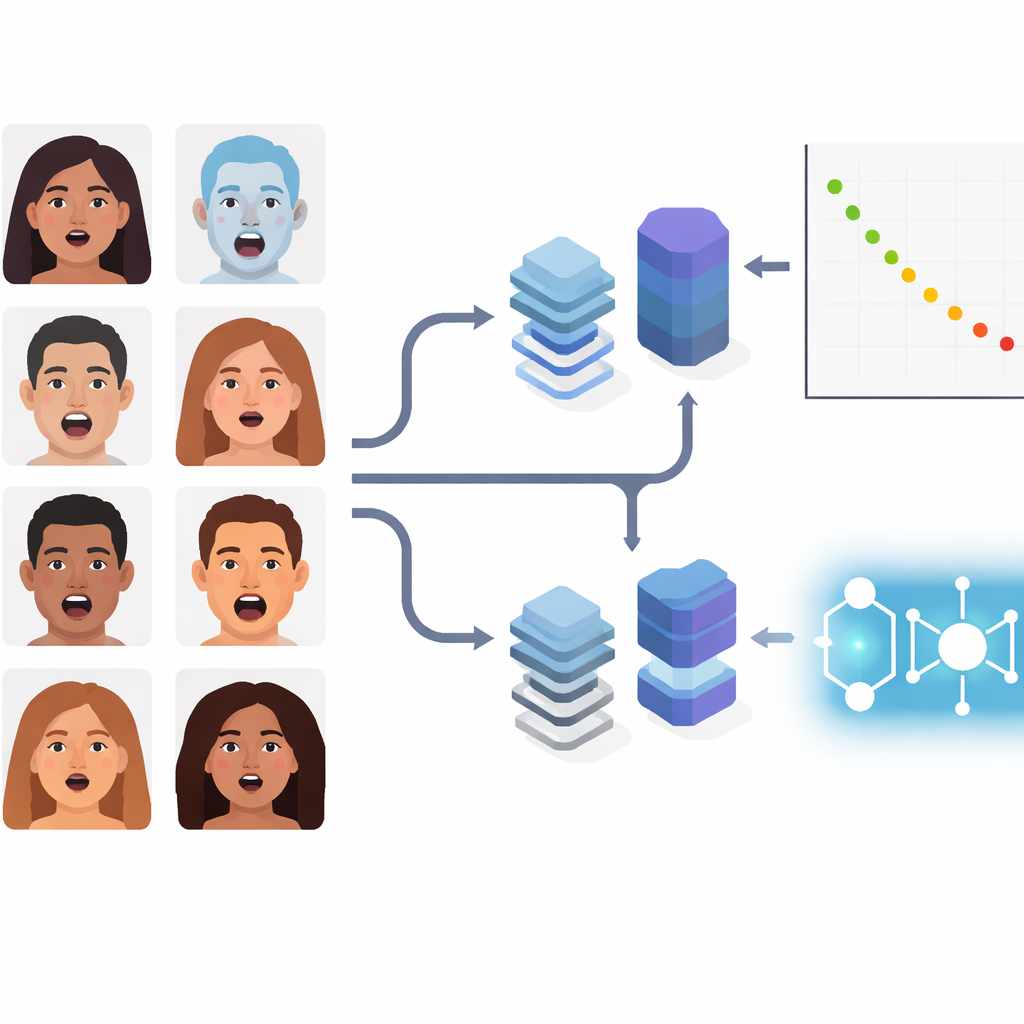
I stället för att fokusera på läroboksbaserade grundkänslor tar författarna sig an sammansatta uttryck som ”rädd-förvånad” eller ”sorgligt äcklad.” Dessa nyanserade tillstånd förekommer ofta i naturliga miljöer som kliniker, bilar eller vid interaktioner med sociala robotar. Teamet använder en välkänd bildsamling kallad RAF-DB, som innehåller tusentals ansikten fångade ”in the wild” under varierande ljusförhållanden, poser och demografier. De begränsar sig till 11 sammansatta kategorier och säkerställer identiska datasplit och förbehandlingar över alla metoder så att eventuella skillnader i prestanda verkligen härstammar från modellerna och inte från utvalda träningsförhållanden.
Sju sätt att lära datorer läsa ansikten
Studien jämför sju pipeliner som representerar tre teknikgenerationer. Först kommer klassiska hybrider, som använder etablerade konvolutionsnätverk (ResNet50 och VGGFace) endast som funktionsutdragare och sedan lämnar slutbeslutet till en enklare marginalbaserad klassificerare kallad SVM. Därefter följer två populära moderna djupa modeller: EfficientNetV2-S, ett strömlinjeformat konvolutionsnät optimerat för effektivitet, och ViT-B/16, en vision-transformer som analyserar bilder som uppsättningar av patchar och använder global attention för att koppla samman avlägsna ansiktsregioner. Slutligen tre kvant–klassiska hybrider. I dessa producerar en standard visuell enkoder kompakta numeriska funktioner som sedan bearbetas av kvantinspirerade komponenter: en kvantstödd supportvektormaskin (QSVM), en kvantbaserad k-närmsta granne-metod (QKNN) eller ett kvantkonvolutionellt nätverk (QCNN).
Hastighet, noggrannhet och kompromisserna mellan dem
I stället för att jaga en enda huvudrubriks-siffra för noggrannhet mäter författarna noggrant tid för funktionsuttag, träningstid och klassificeringstid per bild, allt på samma hårdvara. ViT-B/16 hamnar i topp när det gäller noggrannhet och klassificerar korrekt cirka 63 % av de sammansatta uttrycken samtidigt som funktionsuttaget förblir förvånansvärt snabbt. EfficientNetV2-S ligger nära med cirka 61 % noggrannhet, men kräver betydligt mer tid för funktionsuttag. Bland de kvant-hybrida presterar QSVM bäst och når ungefär 55 % noggrannhet med endast omkring en minuts funktionsuttagstid, vilket gör den attraktiv när beräkningsbudgetar är begränsade. QKNN och QCNN är ännu mer tidsfria — särskilt QCNN — men offrar noggrannhet och ligger runt mitten av 30-procentsintervallet. Klassiska hybrider befinner sig mitt emellan, användbara som transparenta baslinjer men generellt efter de moderna och kvantförstärkta alternativen.
Var maskiner fortfarande blir förvirrade
En närmare granskning av felen visar att alla system kämpar på liknande sätt. Förväxlingar tenderar att klustra kring två familjer: rädsla kontra förvåning, samt sorg kontra äckel (ibland blandat med ilska). Dessa kategorier delar liknande ansiktsmuskelmönster — vidöppna ögon och höjda ögonbryn för rädsla och förvåning, eller nedåtvända läppar och nässkrynkor för sorg och äckel — så deras visuella avtryck överlappar. Inte ens ViT:s globala attention och QSVM:s mer uttrycksfulla kvantkärnor kan helt separera dessa likartade uttryck. Författarna menar att framtida modeller bör rikta särskild uppmärksamhet mot specifika ansiktsregioner kopplade till action units (såsom ögonvrån, ögonbryn och området runt näsan), justera sina träningsmål för att öka marginalerna mellan närliggande klasser och använda balanserade dataaugmenteringsstrategier för att undvika överanpassning till de vanligaste sammansättningarna.
Vad detta betyder för känslo-medvetna system i verkligheten
Författarna påstår inte att kvantmetoder redan överträffat klassisk djupinlärning. I stället erbjuder de en noggrann karta över det nuvarande landskapet. Om absolut noggrannhet är avgörande och beräkningsresurserna är rikliga leder vision-transformers fortfarande. När utvecklare måste hålla koll på effektbudgetar eller latenstider — till exempel på edge-enheter eller låg-latensservrar — erbjuder kvant-hybrider som QSVM och QKNN ett lovande mellanting, då de kortar funktionsuttag och inferenstid samtidigt som de behåller respektabel noggrannhet. Klassiska CNN-plus-SVM-pipeliner är fortfarande användbara riktmärken. Genom att kombinera rigorös beräkningsredovisning, detaljerad felanalys och formella statistiska tester visar detta arbete att tolkningen av komplexa mänskliga känslor lika mycket handlar om smart resursallokering och rättvisa som om rå noggrannhet — och att kvantinspirerade verktyg snart kan bli praktiska partner i det arbetet.
Citering: Florestiyanto, M.Y., Surjono, H.D. & Jati, H. Benchmarking quantum kernels and modern vision models for compound facial expression recognition. Sci Rep 16, 11261 (2026). https://doi.org/10.1038/s41598-026-41514-2
Nyckelord: igenkänning av ansiktsuttryck, sammansatta känslor, vision-transformers, kvantmaskininlärning, effektiva AI-modeller